本文主要分享【对行为决策理论观点描述正确的有()】,技术文章【学习笔记8--汽车行为决策理论】为【FUXI_Willard】投稿,如果你遇到自动驾驶汽车决策与控制相关问题,本文相关知识或能到你。对行
本文主要分享【对行为决策理论观点描述正确的有()】,技术文章【学习笔记8--汽车行为决策理论】为【FUXI_Willard】投稿,如果你遇到自动驾驶汽车决策与控制相关问题,本文相关知识或能到你。
对行为决策理论观点描述正确的有()
本系列博客包括6个专栏,分别为:《自动驾驶技术概览》、《自动驾驶汽车平台技术基础》、《自动驾驶汽车定位技术》、《自动驾驶汽车环境感知》、《自动驾驶汽车决策与控制》、《自动驾驶系统设计及应用》。
此专栏是关于《自动驾驶汽车决策与控制》书籍的笔记.
3.汽车行为决策理论 根据现代决策理论发展历程,将决策理论分为:理性决策理论和行为决策理论;理性决策理论:认为决策者会从完全理性的角度,根据其所能获得的所有准确的、完全的决策信息,得出一个最优的或者具有最大效用的决策方案;行为决策理论:主要内容是以决策者的决策行为作为出发点,研究决策者的认知过程,揭示决策者的判断和选择的原理解释,而非对决策对错的评价;从认知原理学的角度,研究决策者做决策过程中的信息处理机制及其所受的内外部环境影响;行为决策理论是探讨"人们实际是怎样进行决策的"及"为什么会这样决策"的理论;无人驾驶汽车为了能实现各种交通场景下的正常行驶,其行为决策子系统需要具备如下特性: 合理性:行为决策系统的合理性是一个比较难以界定的概念,每个人对于驾驶行为是否合理都有一个评判标准;实时性:针对复杂的动态交通场景,行为决策系统能根据外部环境的变化,快速地做出驾驶策略上的响应,避免危险情况的发生; 3.1 无人驾驶行为决策系统 行为决策子系统的目标:对可能出现的驾驶道路环境都给出一个合理的行为决策;行为决策系统先分析道路结构环境,明确自身所处的驾驶场景,然后在此基础上针对特定的驾驶场景,基于基本交通规则或驾驶经验组成的驾驶先验知识,在多个可选行为中基于驾驶任务需求等要素条件,选择此场景下的最优驾驶行为;
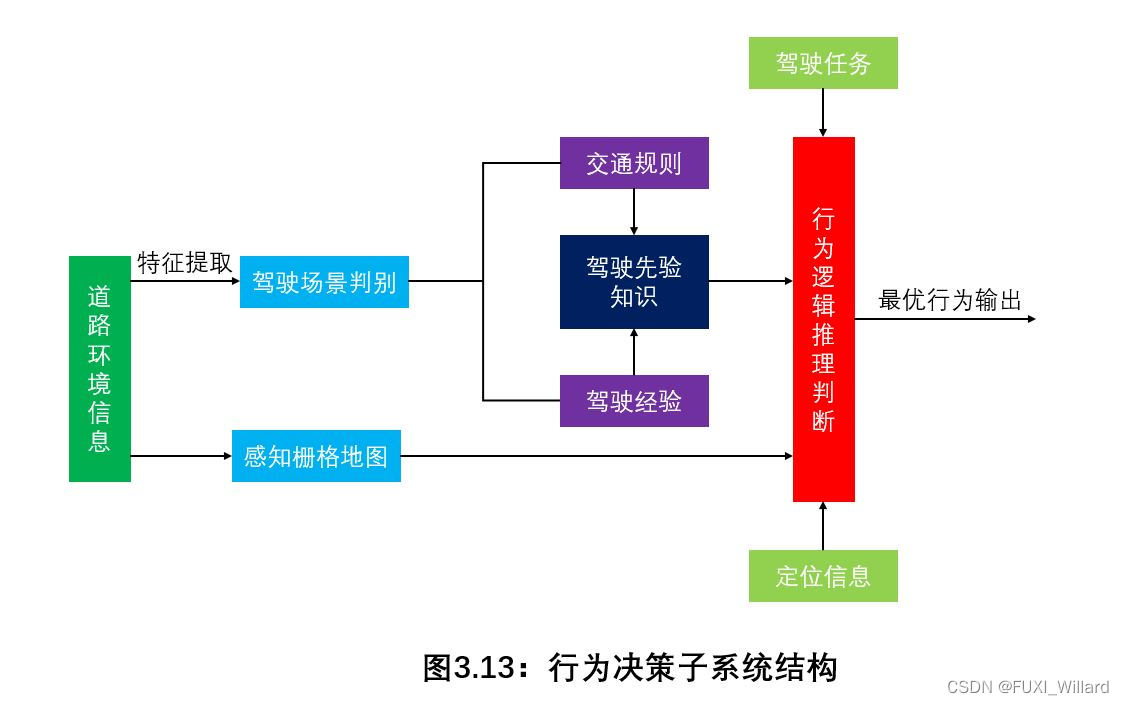
3.2 基于规则的行为决策
介绍一种基于规则的自动驾驶汽车行为决策层设计,核心思想是利用分治的原则将自动驾驶汽车周边的场景进行划分;在每个场景中,独立运用对应的规则来计算自动驾驶汽车对每个场景中元素的决策行为,再将所有划分的场景的决策进行综合,得出一个最后综合的总体行为决定。
综合决策
综合决策代表自动驾驶汽车行为决策层面的整体最高层的决策,如:按照当前车道跟车保持车距行驶,换道至左/右相邻车道,立即停车到某一停止线后等;
作为最高层面的综合决策,其所决策的指令状态空间定义需要和下游的运动规划(Motion Planning)模块保持一致,这样计算得出的综合决策指令是下游可以直接用来执行从而规划出路线轨迹的;
综合决策的指令集定义及其可能的参数:
综合决策的指令集定义参数综合决策的指令集定义参数行驶当前车道
目标车道换道当前车道
换道车道
加速并道
加速并道跟车当前车道
跟车对象
目标车速
跟车距离停车当前车道
停车对象
停车位置转弯当前车道
目标车道
转弯属性
转弯速度
下游的运动规划模块基于宏观综合决定及伴随指令传来的参数数据,结合地图信息等,即可直接规划出安全无碰撞的行驶路线;
个体决策
个体决策:指对所有重要的行为决策层面的输入个体,都产生一个决策;个体可以是感知输出的路上汽车和行人,可以是结合了地图元素的抽象个体,如:红绿灯或人行横道对应的停止线等;在场景划分的基础上产生每个场景下的个体决策,再综合考虑归纳这些个体决策,得到最终的综合决策;个体决策不仅产生最后的综合决策的元素,且和综合决策一起被传递给下游运动规划模块;个体决策和综合决策相似的地方:除了其指令集本身外,个体决策也带有参数数据;
场景
场景可以理解为一系列具有相对独立意义的自动驾驶汽车周边环境的划分;在每个场景实体中,基于交通规则,并结合主车的意图,可以计算出对于每个信息元素的个体决策,再通过一系列准则和必要的运算把这些个体决策最终综合输出给下游;每个场景模块利用自身的业务逻辑来计算不同元素个体的决策,通过场景的复合,及最后对所有个体的综合决策考虑,自动驾驶汽车得到的最终行为决策需要是最安全的决策;
行为决策层面的框架和运行流程:
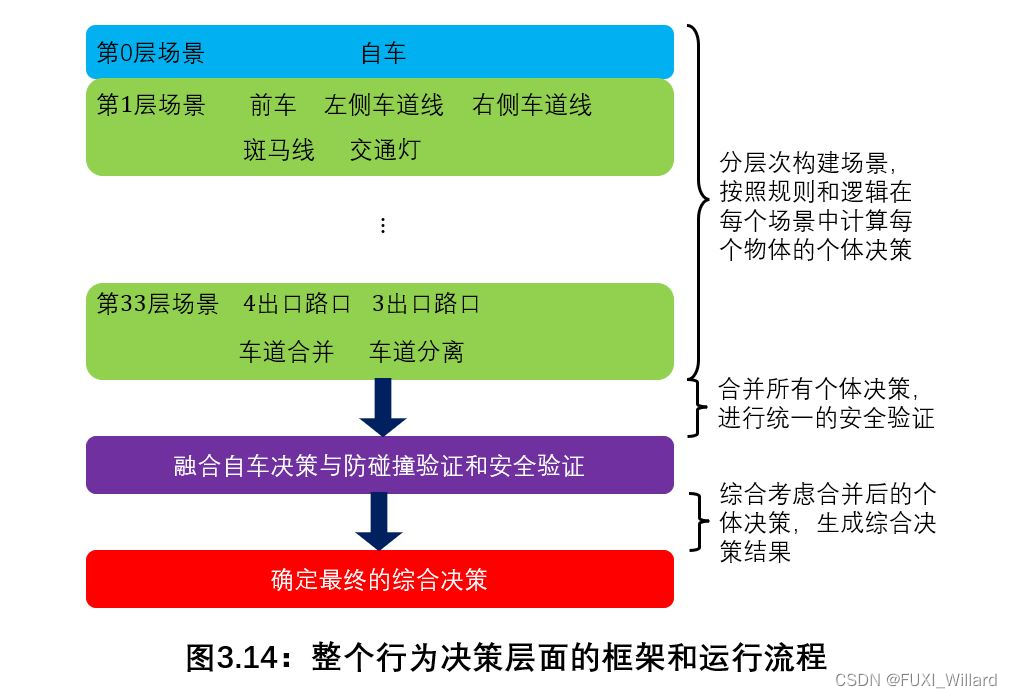
结合主车信息、地图数据及感知结果构建不同层面的场景;在全局路径规划的指引下,每个场景结合自身的规则,计算出属于每个场景物体的个体决策;在所有个体决策计算完毕后,虽然发生的概率极其微小,但模块还是会检查有无冲突的个体决策;在对冲突的个体决策进行冲突解决后,推演、预测当前的所有个体决策能否汇总成一个安全行驶无碰撞的综合决策;如果这样的安全无碰撞综合决策存在,将其和个体决策一起输出给下层的运动规划模块,计算具体从当前位置到下一个位置的时空轨迹; 3.3 马尔可夫决策过程
一个马尔可夫决策过程,由一个五元组定义: ( S , A , T , R , γ ) (S,A,T,R,\gamma) (S,A,T,R,γ):
S S S代表自动驾驶汽车所处的有限状态空间。状态空间的划分可以结合自动驾驶汽车当前位置及其在地图上的场景进行设计:如在位置维度可以考虑将自动驾驶汽车按照当前所处的位置划分成等距离的格子;参考地图的场景,可以将自动驾驶汽车所处的车道和周边道路情况归纳到有限的抽象状态中;
A A A代表自动驾驶汽车的行为决策空间,即自动驾驶汽车在任何状态下的所有行为空间集合。如:可能的状态空间包括当前车道跟车(Follow)、换道(Change Lane)、左/右转(Turn Left/Right)、路口的先后关系(Yield/Overtake)、遇到行人或红绿灯时的停车(Stop)等;状态转移函数
T T T:
T ( s , s ′ ) = P ( s ′ ∣ s , a ) T(s,s')=P(s'|s,a) T(s,s′)=P(s′∣s,a)是一个条件概率,代表自动驾驶汽车在状态
s s s和动作
a a a下,到达下一个状态
s ′ s' s′的概率;激励函数
R R R:
R a ( s , s ′ ) R_a(s,s') Ra(s,s′)代表自动驾驶汽车在动作
a a a下,从状态
s s s到状态
s ′ s' s′所得到的激励。该激励函数可以考虑安全性、舒适性、可通行性、到达目的地能力,及下游运动规划(Motion Planning)执行难度等因素综合设计;
γ ∈ ( 0 , 1 ) \gamma\in(0,1) γ∈(0,1)是激励的衰减因子,下一时刻的激励按照这个因子进行衰减,在任何一个时间,当前激励系数为1,下一时刻的激励系数为
γ 1 \gamma^1 γ1,下两个时刻的激励系数为
γ 2 \gamma^2 γ2,以此类推;含义是当前的激励总是比未来的激励重要;
自动驾驶汽车行为决策层面需要解决的问题,在上述马尔可夫决策过程(MDP)的定义,可以正式描述为寻找一个最优"策略";在任意给定的状态 s s s下,策略会决定产生一个对应的行为;当策略确定后,整个MDP的行为可以看成一个马尔可夫链;
行为决策的策略选取目标是优化从当前时间点开始到未来的累积激励:
∑ t = 0 ∞ γ t R a t ( s t , s t + 1 ) \sum_{t=0}^{\infty}\gamma^tR_{a_t}(s_t,s_{t+1}) t=0∑∞γtRat(st,st+1)
假设转移矩阵和激励分布已知,最优策略的求解通常基于迭代的计算如下两个基于状态 s s s的数组:
π ( s t ) ← a r g m a x { ∑ s t + 1 P a ( s t , s t + 1 ) ( R a ( S t , s t + 1 ) + γ V ( s t + 1 ) ) } \pi(s_t)\leftarrow{argmax}\{\sum_{s_{t+1}}P_a(s_t,s_{t+1})(R_a(S_t,s_{t+1})+\gamma{V(s_{t+1})})\} π(st)←argmax{
st+1∑Pa(st,st+1)(Ra(St,st+1)+γV(st+1))}
V ( s t ) ← ∑ s t + 1 P π ( s t ) ( s t , s t + 1 ) ( R π ( s t ) ( s t , s t + 1 ) + γ V ( s t + 1 ) ) V(s_t)\leftarrow\sum_{s_{t+1}}P_{\pi(s_t)}(s_t,s_{t+1})(R_{\pi(s_t)}(s_t,s_{t+1})+\gamma{V(s_{t+1})}) V(st)←st+1∑Pπ(st)(st,st+1)(Rπ(st)(st,st+1)+γV(st+1))
其中:数组 V ( s t ) V(s_t) V(st)代表未来衰减叠加的累积激励;
具体求解过程可以在所有可能的状态 s s s和 s ′ s' s′间进行重复迭代计算,直到二者收敛为止;
利用MDP解决自动驾驶汽车行为决策最关键部分在于激励函数 R R R的设计,在设计时需要考虑的因素:
到达目的地:"鼓励"自动驾驶汽车按照既定的路由寻径路线行进到达目的地;如果选择的动作会使得自动驾驶汽车有可能偏离既定的全局导航结果,则应当给予对应的惩罚;安全性和避免碰撞:如果将自动驾驶汽车周边的空间划分成等间距的方格,则远离可能有碰撞的方格应当得到激励,接近碰撞发生时,应加大惩罚;乘坐的舒适性和下游执行的平滑性:如从某一个速度状态到一个比较接近的速度状态时,其代价较小;如果猛打方向盘或猛然加速,则对应的代价应该较高;
在马尔可夫决策过程基础上,部分可观察马尔可夫决策过程考虑了环境的部分可观察性,即智能体不能准确地得到所有的环境状态,如:无人驾驶汽车无法通过环境感知系统直接得到其他汽车的驾驶意图等;
部分可观察马尔可夫决策过程可以形式化地表示为一个六元组 ( S , A , Ω , T , O , R ) (S,A,\Omega,T,O,R) (S,A,Ω,T,O,R),其中状态集合 S S S、动作集合 A A A、状态转移函数 T T T和激励函数 R R R的定义和马尔可夫决策过程相同,MDP所不具备的观察集合和观察函数用以描述环境状态的部分可观察性;
观察集合
O O O:表示观察序列集合;观察函数
Ω \Omega Ω:
S × A × O → [ 0 , 1 ] S\times{A}\times{O}\rightarrow[0,1] S×A×O→[0,1],表示在给定所执行的动作
A A A和环境状态
s ′ s' s′的情况下,智能体观察序列集合为
O O O的概率分布;
当环境是部分可观察时,无人驾驶汽车无法完全获得自身所处的真实状态,只能估计在所有可能状态上的概率分布;这种概率分布被称为信念状态,是对目前环境状态的概率估计,是对所有过去观察、行动历史的统计充分量;信念状态的集合构成一个信念空间,部分可观察马尔可夫决策过程可以看作在信念空间上的马尔可夫决策过程;
对于自动驾驶决策来说,部分马尔可夫决策过程(POMDP)的状态空间需要能够涵盖局部规划窗内动态实体的所有可能状态,因此将状态空间定义为无人驾驶汽车自身和周边其他汽车的运动状态,对于无人驾驶汽车自身,主要考虑其在局部栅格图中的位置、坐标、航向;对于其他汽车,除了考虑其位置、速度、航向信息外,还要考虑驾驶意图;
无人驾驶汽车的状态信息是完全可观察的,通过环境感知系统可以完成对状态信息的估计;其他动态实体在局部规划窗内的位置、速度、航向和驾驶意图是部分可观察的,需要通过场景理解模块的意图预测模型对驾驶意图进行估计和预测;
动作空间主要用于定义无人驾驶汽车所有可能采取的驾驶动作;无人驾驶汽车行为决策层的驾驶动作为抽象语义动作,如:“加速”、“减速”、"换道"等;
一般将无人驾驶汽车可能采取的驾驶动作分为横向驾驶动作和纵向驾驶动作;横向驾驶动作包括:“加速”、“匀速”、“减速”、“停车”;纵向驾驶动作包括:“左换道”、“右换道”、“车道保持”、“路口直行”、“路口左转”、"路口右转"等;
状态转移模型是POMDP模型的核心模块,重点描述驾驶场景状态随时间的演进过程,为驾驶动作生成提供前瞻信息;一般情况下,将其他汽车的状态转移分为:运动状态转移和驾驶意图转移;
观察模型(传感器模型),主要是基于当前状态和驾驶动作估计信念状态的分布;由于感知误差的存在,环境感知系统对其他汽车的检测状态与其他汽车的真实状态之间存在一定的差异;此时一般把其他汽车状态看作高斯分布;
激励函数是对自主驾驶任务完成程度的定量评估,通常根据多个目标属性进行定义,一般在无人驾驶中,选用的目标属性包括:安全性、舒适度、任务完成度和任务完成效率;
在自动驾驶决策模块应用中,为了实时求解POMDP,通常求解马尔可夫问题的近似解,而不考虑对真正最优解的求解;
两类常见的近似求解方法:
基于启发式搜索沿着最有可能的信念状态进行扩展;对高度可能的状态进行稀疏随机抽样或使用蒙特卡洛搜索技术;
本文《学习笔记8--汽车行为决策理论》版权归FUXI_Willard所有,引用学习笔记8--汽车行为决策理论需遵循CC 4.0 BY-SA版权协议。



![[大整数乘法] java代码实现](https://img1.php1.cn/3cd4a/24c6f/9f3/0133bb25da242824.jpeg)





 京公网安备 11010802041100号
京公网安备 11010802041100号