近日,北京智源人工智能研究院和清华大学研究团队联合发布了以中文为核心的大规模预训练语言模型 CPM-LM,参数规模达 26 亿,预训练中文数据规模 100 GB。
机器之心报道,机器之心编辑部。
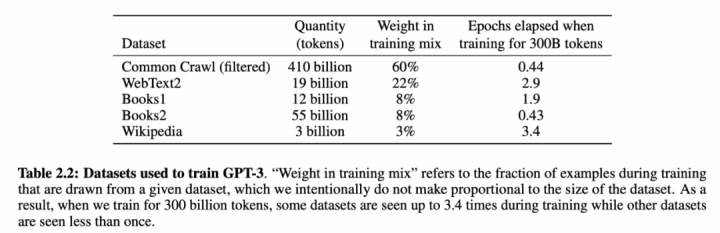
自 2018 年谷歌发布 BERT 以来,预训练模型在自然语言处理(NLP)领域逐渐成为主流。今年 5 月份,OpenAI 推出的史上最大 AI 模型 GPT-3更是引起了大量讨论。但是,目前 NLP 领域的预训练模型多针对英语语言,以英语语言数据为训练数据,例如 GPT-3:
用于训练 GPT-3 的数据集。近日,北京智源人工智能研究院和清华大学研究团队合作开展了一项名为「清源 CPM (Chinese Pretrained Models)」的大规模预训练模型开源计划,旨在构建以中文为核心的大规模预训练模型。首期开源内容包括预训练中文语言模型和预训练知识表示模型,可广泛应用于中文自然语言理解、生成任务以及知识计算应用,所有模型免费向学术界和产业界开放下载,供研究使用。
- 清源 CPM 主页:https://cpm.baai.ac.cn/
- 清源 CPM Github 托管代码主页:https://github.com/TsinghuaAI/
模型特点
根据清源 CPM 主页介绍,该计划发布的预训练模型具备以下特点:
- 模型规模大:本次发布的 CPM-LM 参数规模达 26 亿,预训练中文数据规模 100 GB,使用了 64 块 V100 GPU,训练时间约为 3 周;CPM-KG 的参数规模为 217 亿,预训练结构化知识图谱为 WikiData 全量数据,包含近 1300 个关系、8500 万实体、4.8 亿个事实三元组,使用了 8 块 V100 GPU 训练时间约为 2 周。
- 语料丰富多样:收集大量丰富多样的中文语料,包括百科、小说、对话、问答、新闻等类型。
- 学习能力强:能够在多种自然语言处理任务上进行零次学习或少次学习,并达到较好的效果。
- 行文自然流畅:基于给定上文,模型可以续写出一致性高、可读性强的文本,达到现有中文生成模型的领先效果。
在模型训练方面,CPM 模型预训练过程分布在多块 GPU 上,采用层内并行的方法进行训练,并基于当前已有的成熟技术,减少同步提高通讯速率。
在硬件设施方面,为训练该 CPM 模型,共有 64 块 V100 显卡投入使用。经过预训练的 CPM 模型可以用来促进诸多下游中文任务,如对话、论文生成、完形填空和语言理解等。
为了促进中文自然语言处理研究的发展,该项目还提供了 CPM-LM (2.6B) 模型的文本生成代码,可用于文本生成的本地测试,并以此为基础进一步研究零次学习 / 少次学习等场景,详情参见项目 GitHub 主页。
模型性能
清源 CPM 使用新闻、百科、对话、网页、故事等不同类型的中文语料数据进行预训练。在多个公开的中文数据集上的实验表明,清源 CPM 在少样本或无样本的情况下均能够实现较好的效果。
中文成语填空 ChID
ChID 是 2019 年清华大学对话交互式人工智能实验室(CoAI)收集的中文成语填空数据集,其目标是对于给定的段落,在 10 个候选项中选择最符合段意的成语进行填空。
其中有监督设定是指在 ChID 的训练集上进行训练,随后在测试集上测试;无监督设定是指不经过任何额外训练,直接使用预训练模型进行测试。具体做法是,将候选项依次填入段落中,计算填充后段落的困惑度 (Perplexity),选择困惑度最小的候选项作为预测结果。表中汇报了预测的准确率,可以看到,CPM (大) 在无监督设定下甚至达到了比有监督 CPM (小) 更好的结果,反映出清源 CPM 强大的中文语言建模能力。
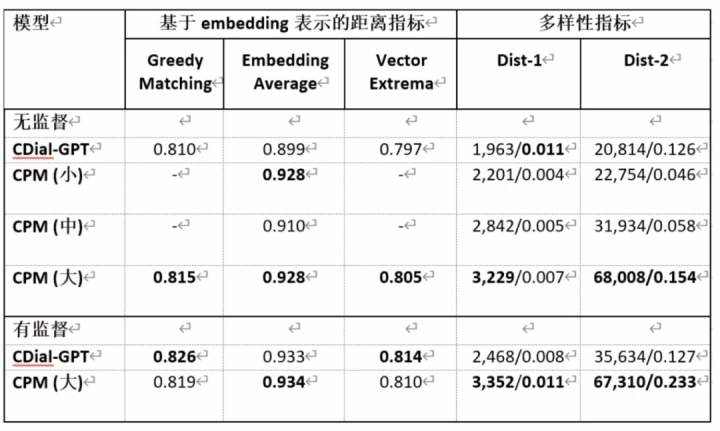
对话生成 STC
STC 是 2015 年华为诺亚方舟实验室提出的短文本对话数据集,要求在给定上文多轮对话的条件下预测接下来的回复。
其中 CDial-GPT 是清华大学对话交互式人工智能(CoAI)实验室 2020 年提出的中文对话预训练模型。用于衡量多样性的 Dist-n 指标的两个数字分别是所有不重复的 N-Gram 的数量及占所有 N-Gram 的比例。可以看到,在无监督的设定下,清源 CPM 具有更好的泛化性,在有监督设定下,清源 CPM 能达到比 CDial-GPT 更优的效果,尤其在多样性指标上表现更佳。
文本分类
清源 CPM 使用头条新闻标题分类(TNEWS,采样为 4 分类)、IFLYTEK 应用介绍分类(IFLYTEK,采样为 4 分类)、中文自然语言推断(OCNLI,3 分类)任务作为文本分类任务的基准。具体做法是,先输入分类样本,再输入「该文章的类别为 / 该介绍的类别为 / 两句话的关系为」,要求模型直接生成标签,四个标签中概率最高的标签作为预测结果。在无监督设定下,不同规模的清源 CPM 在文本分类任务上的精确度如下表所示:
清源 CPM 能够在无监督的设定下达到比随机预测好得多的精确度(TNEWS/IFLYTEK/OCNLI 随机预测精确度分别为 0.25/0.25/0.33)。
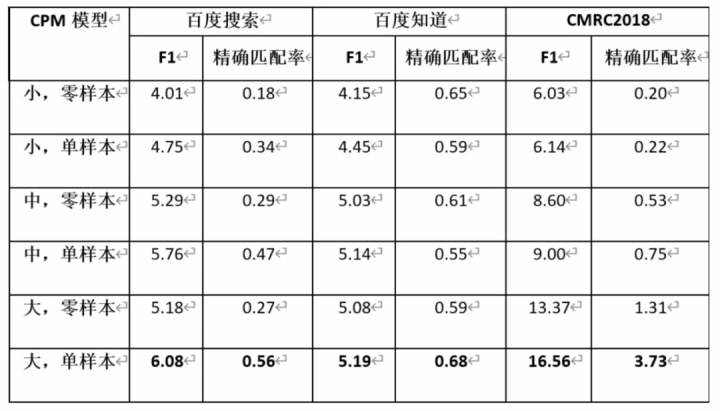
自动问答
CPM 使用 DuReader 和 CMRC2018 作为自动问答任务的基准,要求模型从给定段落中抽取一个片段作为对题目问题的答案,其中 DuReader 由百度搜索和百度知道两部分数据组成。在无监督的设定下,不同规模的 CPM 模型的表现如下表所示:
其中单样本是指在测试时,从数据集中随机抽取一个正确的「(段落,问题,答案)」三元组,插入到用于评价的样例前,作为 CPM 模型生成答案的提示;零样本是指直接使用 CPM 模型预测给定段落和问题的答案。在单样本设定下,CPM 能从给定的样本中学习到生成答案的模式,因此效果总是比零样本设定更好。由于模型的输入长度有限,多样本输入的场景将在未来进行探索。
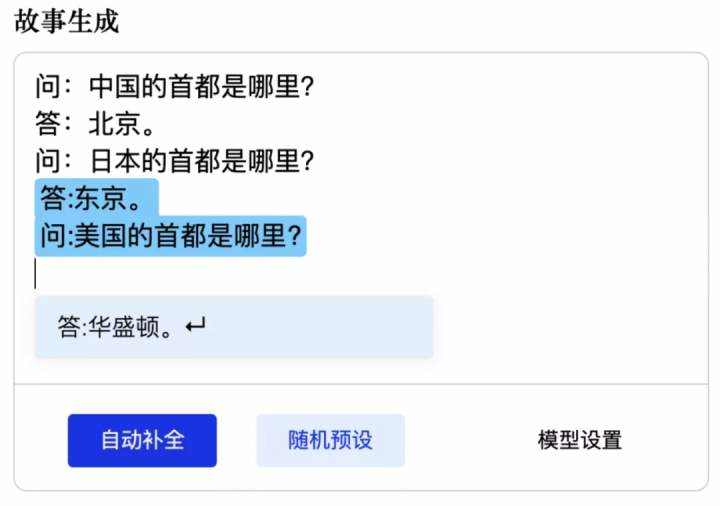
模型效果展示
我们可以从以下示例中,观察 CPM 预训练中文语言模型的效果。比如基于对单个常识性问题的学习,依照规律进行提问和正确回答:
根据前文真实的天气预报,继续报道天气预报(不保证正确性):
执行数理推理:
甚至续写《红楼梦》片段:
据了解,清源 CPM 未来计划开源发布更大规模的预训练中文语言模型、以中文为核心的多语言预训练模型、融合大规模知识的预训练语言模型等。
参考阅读:
- 从 word2vec 开始,说下 GPT 庞大的家族系谱
- 预训练语言模型关系图 + 必读论文列表,清华荣誉出品
- 乘风破浪的 PTM,深度解读预训练模型的进展
















 京公网安备 11010802041100号
京公网安备 11010802041100号