作者:挖墙找红杏000 | 来源:互联网 | 2023-06-26 15:18
背景前段时间买了个小米的空调伴侣,想用来查看空调的功率,以确认空调到底会用掉多少电。买的时候发现空调伴侣也支持红外控制,这就得好好利用一下了。但是有个尴尬的问题,就是空调插座在很
背景
前段时间买了个小米的空调伴侣,想用来查看空调的功率,以确认空调到底会用掉多少电。
买的时候发现空调伴侣也支持红外控制,这就得好好利用一下了。但是有个尴尬的问题,就是空调插座在很偏的地方,导致了无法控制空调,也没法控制投影仪。
当一个东西你拥有了以后又失去的时候,你会很难受,所以我就想着要再买它一个红外控制设备来做这个事,看了一圈发现,小米万能遥控没得买了,变成了理财产品,所以就找了一款替代产品。欧瑞博的一款万能遥控。买完之后才发现,虽然能控制空调和投影仪了,但是有两个很严重的问题:
- 是没法使用小爱来通过欧瑞博的万能遥控来控制投影仪,目前两边还没打通,所以该功能还没法支持。
- 是使用小爱通过欧瑞博控制空调的时候常常无响应,估计就是小爱调用欧瑞博的过程出问题了,因为直接使用欧瑞博的app是可以生效的。
决定自制红外控制设备
到此,我决定,要不自己做一个吧,貌似成本也挺便宜的,还能玩玩IoT,多有意义。
所以我就花了大量的时间来做这个事,先去调研了一下用什么单片机,后面了解到用ESP32还挺好的,集成了WIFI和蓝牙,之后还可以实现一些比较fancy的功能。
除了硬件,当然还需要给刷上固件了,所以,还需要快速自学一下程序该咋写,于是乎就快速过了一遍《Arduino从基础到实践》,通过控制LED灯来练了一下手。接下来就是开发红外功能了,淘宝上9块钱买了红外收发的模块,借助PlatformIO开发了第一版红外固件,成功地点亮了投影仪,但是同时还有两个大坑没填:
- 是红外发射模块太弱了,只能在差不多半米的距离来控制设备;
- 是死活控制不了空调。
后续通过另购了一款16元的大功率发射模块解决了问题1。
对于问题2,着实折磨了我好几天的时间,到处检查到底是哪里的代码写出问题了,因此还去研究了一下红外协议,按位对比了一下我发射出去的红外和空调遥控发射出去的红外到底有什么不同,后来发现,格力空调的红外有点特殊,但只需要修改一下配置,就能轻松解决。
终于搞定了控制问题,顺手再撸一个WebServer来接受请求。
到此,单片机端的部分就告一段落了。
决定自制智能音箱
我想的是接下来就是如何通过小爱音箱来控制我的单片机发射红外信号了,所以搜索了一下该怎么做,网上有人实现的做法是通过注册小爱开发者账号,通过类似"小爱同学" -> "让XXX打开空调"的方式来控制。具体就是在小米那边配置一类意图,只要是"让XXX干什么"这样的命令,都转发到我们自己的服务器上,然后在服务器端解析小米给你发送的意图和实体,自行实现逻辑来进行控制(在我们的场景下就是发送一个http请求)。所以,这还要求我们能有个公网地址,或者通过别的服务来做内网穿透。
然后我就去申请了小爱开发者平台,但是他们的服务效率真的是太低了,由于我是周4申请的,竟然两天都没申请下来,到了周末,我就又动了"自己整一个小爱音箱的想法"。
说干就干,要实现这功能,首先得找找思路,所以就在github上先找了一下这类智能音箱的开源代码。
对比了一圈,发现wukong-robot 是一款挺好的产品,支持中文,还可以自定义插件,所以就冲了一波。
然后就又碰到问题了,这个库使用了各种云服务来支持实现智能音箱的功能,所以,我又又需要申请这些云服务的账号来试用,这我就不乐意了,咋又要申请呢?
所以,最后我决定,所有用到的云服务有功能,通通本地搭建。
好处很明显:
- 延迟降低,本地调用微妙级别的延迟。
- 又又可以学到了。
所以就先将智能音箱涉及到的技术部分都先研究一下是些什么。
一款智能音箱会涉及到:
- 唤醒:通过一个关键词来唤醒音箱听取你的命令
- ASR(automatic speech recognition)或STT(speech to text):也就是语音识别,将语音转换成文字
- NLU(natural language understanding):也就是让机器理解这句话的意思。这本身是一个极其庞大的主题,但是在智能音箱领域,就简化了很多,我们只需要识别出来我们的命令想要做什么就行了。这里面就包含了两部分:
- 意图识别:也就是一句话是干什么的,比如【打开空调】就可以识别成【操纵设备】的意图。
- NER(named entity recognition)命名实体识别:有的地方会称之为slot(槽),就是识别出你关心的对象,比如【打开空调】中,【打开】就属于【操作】实体,【空调】就属于【设备】实体。
- 处理意图和实体:通过识别的意图和实体来实现自己的控制逻辑,比如当出现【操纵设备】的意图时,去检查一下具体的操作和设备是什么实体,来达到控制设备的效果。
- TTS(text to speech):也就是语音合成,将文字转成语音,一般用于回复用户的命令。
ASR 部分
知道了各种技术后,要做的无非就是上github上找各种实现了。
最先打算入手的就是ASR,语音识别算是被研究得比较多的,最先想到的就是去看看百度出的飞桨上是不是有类似的模型,还真让我找到一个,有一个PaddleSpeech的库,上面有一些训练好的模型可以用。
其中碰到的一个坑就是,PaddleSpeech涉及到很多配置,而且在配置中还用了相对路径,导致一开始程序以运行路径为起始来找相对路径,以至于怎么都执行不起来,后来只能稍微改造了一下代码,先指定work path,然后用work path来拼接相对路径,最终才能成功运行。
运行起来后测试了一下语音识别的效果也还行,不能说百分百识别,但是起码音都算是对的,只是可能对应的字有时候不太对。
想着,应该也没有啥大影响,所以也就没咋处理了。
ASR部分就暂时告一段落了。
NLU 部分
下面就是NLU部分,NLU的话选用了RASA来构建,之前其实也听说过RASA,主要是用来构建智能聊天机器人的,也就是少掉语音转文字的部分,单使用文字来聊天。
它本身带有很多NLU相关的模型,我选用了
jieba(分词)+bert-base-chinese LanguageModelFeaturizer(词向量提取)+DIETClassifier(实体提取+意图识别)的组合来训练我自己的NLU。
在使用的过程中也碰到了一个巨坑,训练报错,而且报错信息及其简陋:
tensorflow.python.framework.errors_impl.InvalidArgumentError: Incompatible shapes: [57,10] vs. [57,7]
[[{{node cond/PartitionedCall/cond_11/else/_298/cond/add_1}}]] [Op:__inference_train_function_52346]
鬼知道这是啥错啊,然后google一下,竟然还发现了某个github的issue上有类似的症状,但是迄今仍未解决。
那我就只能自己动手了,debug之,花了一个星期的时间来理解它的代码,终于找到了原因,jieba分词和bert LanguageModelFeaturizer的词向量提取不兼容,jieba分词会把【空格】也识别为一个token,而bert LanguageModelFeaturizer默认会把【空格】去除。所以最简单的做法就是删除我训练样本中的空格,之后还可以研究一下,怎么改RASA的源码,增加一个选项来选择是否移除空格。
优化ASR
终于可以开始组装了,RASA因为本身就是一个很成熟的库,提供了以Web Server来服务的方式,所以只需要自己在wukong_robot中添加一个nlu的类,实现一下各种方法就可以。
而PaddleSpeech就自己写一个Python的flask Web Server来提供一下服务了,并且在wukong_robot中添加上对应的类。
至此,终于可以来试一下效果了,不试不知道,一试发现了各种问题:
效果稀烂,,出现了下面这种尴尬的情况:
2. 【打开电视】识别成了【打个电视】
3. 【关闭电视】识别成了【光闭电视】
之前以为ASR识别不算特别准应该没啥大的影响,但是NLU十分依赖ASR的结果,【打个电视】和【关闭电视】直接导致NLU无法识别出操作类型,到底是打开还是关闭就无从得知了。
唤醒很费力,wukong_robot使用的唤醒库是snowboy,这个库其实挺火的,但是可能是我本身英语发音不是很标准吧,就很难唤醒它,最终通过调高了灵敏度来解决,代价就是,有时候啥也没说,突然它就被唤醒了,挺吓人的。
录音部分有点问题,有时候说命令的时间不够,就我说着说着,它就停止接受命令了,原因是录音使用的定时,只要时间到了,就没法继续说了;相应地,时间如果不到,即使命令说完了,也会一直尬等着。
这几部分很明显都是属于语音相关的,所以只好再去研究研究语音方面的内容,后来了解到,语音识别其实也分得很细(但是也慢慢地被深度学习给端到端替代了):
- 声波编码:将声波编码成计算机能识别的二进制格式
- 特征提取:提取声音中的特征,通常会使用mfcc特征提取,最近的端到端深度学习会更多使用mfcc特征的中间结果,fbank特征
- 声学模型:将声音特征识别成token,在最早的语音识别中,token一般是"状态"这是比音素更小的单位。音素大致可以理解为英文中的音标。现在端到端机器学习中,会直接识别出字,甚至是词组的
- 语言模型:就是找出比较符合常识的结果,就比如上面的【打开电视】和【打个电视】,【打开电视】的出现概率会明显高于【打开】电视。而端到端深度学习的方法中,有时候不会专门分出语言模型来,但是训练完一个模型后,再附加一个语言模型,往往能提升准确率。
在研究语音相关内容的时候,意外发现了一个库,wenet ,然后就试用了一下它预训练的一个multi_cn的模型,发现,这才是真的香呀,引入该模型后直接解决了音箱的两个问题:
- 识别效果:效果贼棒,它在识别的时候会打印出中间过程,从中间过程可以看到,虽然中间过程产出的文本是不太对的,但是你一句话说完后,它能给你把前面不对的部分给纠正过来。
- 录音部分:它支持识别说话结束,也就是说,如果你有一句话特别特别长的话,它会一直等你说完它才会认为这句话说完了,所以只要把ASR替换成这个模型,我的音箱就基本可用了。
wenet提供了CPU部署和GPU部署两种方式,CPU部署非常简单,一行命令启动docker容器就行了,GPU的话需要使用它提供的DockerFile自己build一个docker image,目前multi_cn这个模型没有支持,我也去尝试了一下,发现build完后,在推理时会报错,原因是到了某一层后,所有的参数都变成-1了,目前没有太多的时间研究(赶紧完成音箱才是重点),所以就暂时搁置了。
直接使用了wenet提供的image进行CPU部署,目前它只提供了websocket的服务方式,所以需要我再花些时间适配一下。
终于,除了偶尔会误唤醒外,听力非常正常的智能音箱完工了,
总结
效果演示
下面放上一段效果视频
总体的架构图:
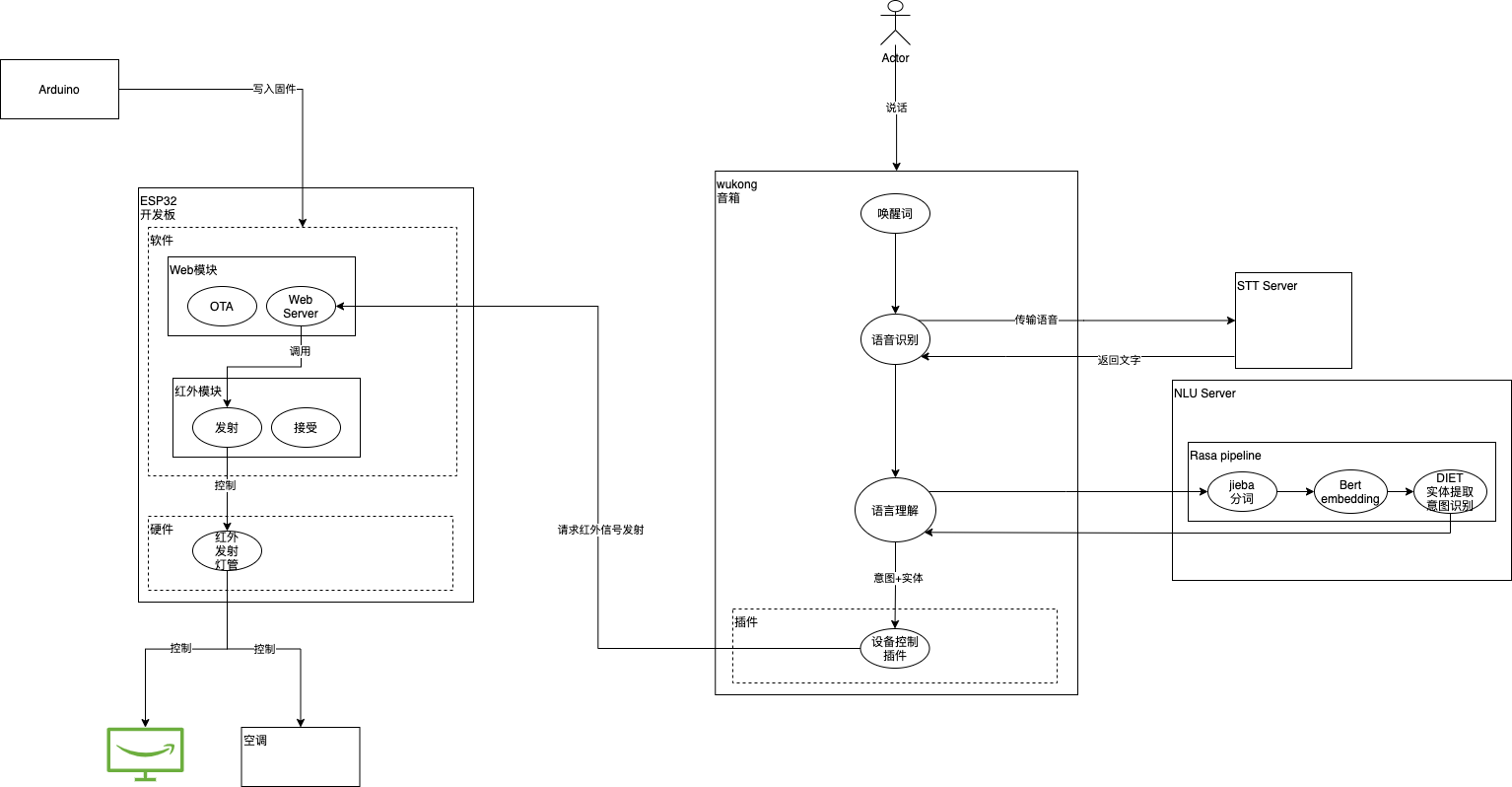
想持续了解后续内容,请关注公众号








 京公网安备 11010802041100号
京公网安备 11010802041100号