ORM框架_关联字段_抽象模型类_CRUD操作
- CRUD的含义
- 数据写入
- 查询数据
- 更新数据
- 删除数据
- 关联字段
- 定义抽象模型类
- 设置默认排序
上一篇文章中,我们创建了数据库了,那么在django中,如何将这些数据进行增删改查呢?
CRUD的含义
crud 是指在做计算处理时的增加(Create)、读取(Read)、更新(Update)和删除(Delete)几个单词的首字母简写。crud主要被用在描述软件系统中数据库或者持久层的基本操作功能。
数据写入
写入数据库共有两种方式
from project.models import Project
// 我们在视图中通过 Project 对象创建指定数据,然后再调用 save 方法进行保存
class ProjectsViews(View):
def get(self, request, pk):
obj = Project(name="金融项目", leader="余少琪")
obj.save()
// 方式二
// 直接使用 Project.objects.create 方法创建数据,这种方式会直接往数据库写入数据
class ProjectsViews(View):
def get(self, request, pk):
Project.objects.create(name="xxx金融项目", leader="余少琪")
查询数据
查询多条数据
class ProjectsViews(View):
def get(self, request, pk):
qs = Project.objects.all()
- 使用模型类的
Project.objects.all() ,会将当前模型类对应的数据表中所有数据都读取出来 Project.objects.all() 返回的是 QuerySet对象(查询集对象)- QuerySet 对象类似于列表,具有惰性查询的特征,(在“用”数据时,才会执行sql语句)
查询单条数据
方式一:
class ProjectsViews(View):
def get(self, request, pk):
obj = Project.objects.get(id=1)
pass
- 使用
Project.objects.get() - 如果 get 查询的记录不存在,会抛出异常
- 如果 get 查询记录存在多条,如我们
Project.objects.get(name="ysq") ,数据库中查询出来多条数据,也会抛出异常 - 结合第三点,因此我们最好使用具有唯一约束的对象进行查询
- 如果使用指定条件查询的记录数据为1,会返回这条记录对应的模型实例对象,可以使用模型对象.字段名去获取相应的字段值
方式二:
class ProjectsViews(View):
def get(self, request, pk):
obj = Project.objects.filter(id=1)
pass
- 使用
Project.objects.filter() ,返回 QuerySet 对象 - 如果查询条件不存在,不会报错,会返回空的 QuerySet 对象
- 如果使用指定条件查询的记录数量超过1条,会将符合条件的模型对象包裹到 QuerySet 对象中返回
- 如果使用指定条件查询的记录为1条,会返回这条记录对应的模型实例对象,可以使用模型对象.字典名称去获取相应的字段值
tips:什么是 QuerySet 对象,它拥有哪些特性?
首先, QuerySet 类似于 python中的列表。
- 支持通过数值 (正整数)获取索引值
- 支持切片操作(正整数)
- 获取第一个模型对象:
Project.objects.filter(name="yushaoqi").first() - 获取最后一个模型对象:
Project.objects.filter(name="yushaoqi").last() - 获取长度:
len(Project.objects.filter(name="yushaoqi")) 、Project.objects.filter(name="yushaoqi").count() - 判断查询条件是否为空:
Project.objects.filter(name="yushaoqi").exits() - 支持迭代操作(for循环,每次循环返回模型对象)
更新数据
class ProjectsViews(View):
def get(self, request, pk):
project_obj = Project.objects.get(id=1)
project_obj.name = "猪猪框架"
project_obj.leader = '可爱的猪猪'
project_obj.save()
更新之后我们来查询一下数据,可以看到虽然我们数据更新了,但是此时他也自动更新了 update_time , 如果我们不想要更新 这个时间呢,应该怎么处理?

可以使用 save(update_fields=['xxx', 'xxx']) 方法,指定更新参数
class ProjectsViews(View):
def get(self, request, pk):
project_obj = Project.objects.get(id=1)
project_obj.name = "猪猪框架"
project_obj.leader = '可爱的猪猪'
project_obj.save(update_fields=['name', 'leader'])
pass
- 由此可见,我们可以查询数据之后,然后再将原先的数据赋值
- 一定要使用 save() 方法才能保存数据
- 通常直接调用 save(), 会更新时间,如果我们不想更新的话,可以使用
save(update_fields=['xxx', 'xxx']) 方法
更新多条数据
// 同时更新多条数据
class ProjectsViews(View):
def get(self, request, pk):
Project.objects.filter(name__contains="项目").update(leader="珍惜")
pass
删除数据
删除单条数据
class ProjectsViews(View):
def get(self, request, pk):
project_obj = Project.objects.get(id=1)
project_obj.delete()
pass
- 删除单条数据,可使用
delete() 直接删除
删除多条数据
class ProjectsViews(View):
def get(self, request, pk):
Project.objects.filter(name__contains="项目").delete()
pass
- 删除多条数据时,可以通过 filter 筛选出需要筛选出的数据,然后同样调用
delete() 方法进行删除
关联字段
什么是关联字段?
关联字段说白点,就是如果想将两个表的数据关联起来,就需要2个表各有1个字段将2个表关联起来,这个字段就是关联字段。
如果数据库中做过多表联查的小伙伴就不难理解,如需同时查询多张表时,那么不同表中的需要关联查询的字段,就是我们的关联字段。
假设我们现在有两张表
班级表:ID、班级名称

学生表:ID、学生名称、班级ID

假设我们需要查询某个班级中的所有学生,这个时候,我们应该怎么查询,是不是先需要从班级表中获取到该班级的所属ID,因此学生表中的 class_id,对应的是班级表中的ID,并且ID相同,这就是关联字段 。
那么我们了解了关联字段之后,结果之前所学习的场景,之前我们创建了项目表,现在我们要创建一个接口表,我们来实战一下。
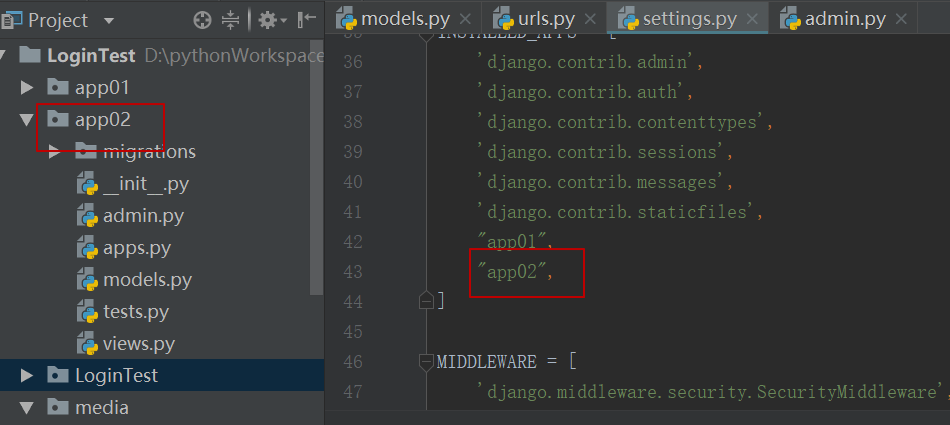
- 我们需要创建一个命名为
interfaces的子应用,其中 interfaces 对应 project应用。
python manage.py startapp interface .
- 创建完成之后,我们需要在 setting.py 文件中的
INSTALLED_APPS 注册子应用
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'rest_framework',
'project',
"interfaces",
]
- 在子应用中,创建
model.py 模型类
class InterFaces(models.Model):
id = models.IntegerField(primary_key=True, verbose_name="id主键", help_text="id主键")
name = models.CharField(verbose_name="接口名称", help_text="接口名称", max_length=20, unique=True)
tester = models.CharField(verbose_name="测试人员", help_text="测试人员", max_length=20)
projects = models.ForeignKey('project.Project', on_delete=models.CASCADE, verbose_name="所属项目", help_text="所属项目")
create_time = models.DateTimeField(auto_now_add=True)
update_time = models.DateTimeField(auto_now=True)
可以看到,我们接口表中的 projects 我们定义为外键字段,这里我们运用到了 ForeignKey。
ForeignKey
- 使用
ForeignKey时,第一个参数作为必传参数,指定需要关联的父表模型类
(1)第一个参数值可以直接使用父表模型类引用
(2)或者可以使用 “子应用名称.父表模型类名称” 推荐这种写法 ForeignKey 需要使用 on_delete 指定级联删除策略
(1)CASCADE:当父表数据删除时,相对应的从表数据会被自动删除
(2)SET_NULL:当父表数据删除时,相对应的从表数据会被自动设置为null值
(3)SET_DEFAULT:当父表数据删除时,相对应的从表数据会被设置为默认值,还需要额外指定 defalut=True
定义抽象模型类
ok,到目前为止,我们一共定义了两个模型类,分别为 Project、InterFaces,他们都会设计到 创建时间、更新时间。那么当我们每个模型都需要这两个字段的时候,每个模型都写会有些冗余,因此我们可以封装一个工具类,将这一块抽离出来,单独封装一个公共模型类来继承它。
我们在主路径下方创建一个 util文件夹,并且创建 base_model.py文件
from django.db import models
class BaseModel(models.Model):
create_time = models.DateTimeField(auto_now_add=True)
update_time = models.DateTimeField(auto_now=True)
class Meta:
abstract = True
注意,通常我们定义模型类的时候,我们生成迁移文件的时候,会将该模型类也生成迁移文件,但是这个既然是公共模型类,显然我们是不需要生成数据库表的,因此我们可以在 内部类 Meta 中使用 abstract 参数,设置成 True。
abstract = True,那么当前模型类,为抽象模型类 ,在迁移时不会创建表,仅仅是为了供其他类继承

定义了公共类之后,我们继承 BaseModel 即可。
class InterFaces(BaseModel):
id = models.IntegerField(primary_key=True, verbose_name="id主键", help_text="id主键")
name = models.CharField(verbose_name="接口名称", help_text="接口名称", max_length=20, unique=True)
tester = models.CharField(verbose_name="测试人员", help_text="测试人员", max_length=20)
projects = models.ForeignKey('project.Project', on_delete=models.CASCADE, verbose_name="所属项目", help_text="所属项目")
create_time = models.DateTimeField(auto_now_add=True)
update_time = models.DateTimeField(auto_now=True)
class Meta:
db_table = 'tb_interfaces'
verbose_name = "接口表"
verbose_name_plural = "接口表"
设置默认排序
我们可以在内部 Meta 类中定义 ordering,可以定义排序规则,默认我们设置成 ‘id’排序, 这里最好每个类都加上,否则会有一个告警信息。
class Meta:
db_table = 'tb_interfaces'
verbose_name = "接口表"
verbose_name_plural = "接口表"
ordering = ['id']


 京公网安备 11010802041100号
京公网安备 11010802041100号