1.ORM的多对多的使用
1>语法与实例
2>聚合与分组
3>F与Q查询
4>事务
2.模板之自定义
1>初始化
2>filter
3>simple_tag
4>inclusion_tag
3.COOKIE和session--原理与比较,方法,无COOKIE时访问需要登陆页面的跳转处理
4.django中间件--请求流程,5种方法的使用与流程图
1.ORM的多对多的使用
1>ORM多对多的语法
#正向查询(表里有外键字段):获取作者对象,对多对多关系表中的book_id做操作
author_obj = models.Author.objects.last()#设置多对多关系
#方式一:
author_obj.books.set([1,2])#方式二:
ret= models.Book.objects.filter(id__in=[1, 4, 16])
# author_obj.books.set(ret)
author_obj.books.set([*ret])#清空多对多关系
author_obj.books.set([])
#增删多对多的关系
#方式一:删ID
author_obj.books.remove(4)
author_obj.books.add(4)
#方式二:删对象
author_obj.books.remove(models.Book.objects.get(id=4))
author_obj.books.add(models.Book.objects.get(id=16))
#清空所有多对多的关系
author_obj.books.clear()
#创建一个新的书籍对象,并且和当前的作者做关联
author_obj.books.create(title='高等英语',publisher_id=3,price=150)#反向查询(表里无外键字段) 获取书籍对象,对多对多关系表中的author_id进行操作
book_obj = models.Book.objects.last()
print(book_obj.author_set,book_obj.author_set.all())
#app01.Author.None
book_obj.author_set.add(4)
2>ORM的实例操作
models.py
class Book(models.Model):title&#61;models.CharField(max_length&#61;32) #创建的属性是字符串 ---> title字段price&#61;models.IntegerField()publisher &#61; models.ForeignKey(&#39;Publisher&#39;) #创建的属性是一个主表Publisher对象 -->publiserh_id字段def __str__(self):return f&#39;<书籍:{self.title} - 价格:{self.price}-出版社:{self.publisher}>&#39;class Author(models.Model):author_name&#61;models.CharField(max_length&#61;32)books&#61;models.ManyToManyField(to&#61;&#39;Book&#39;) #django自动生成第三张表def __str__(self):return f&#39;<作者:{self.author_name},books{self.books}>&#39;views.py
def author_list(request):author_obj &#61; models.Author.objects.all()return render(request,&#39;author_list.html&#39;,{&#39;author_obj&#39;:author_obj})class Addauthor(View):def get(self,request):books &#61; models.Book.objects.all()return render(request,&#39;author_add.html&#39;,{&#39;base&#39;:&#39;base.html&#39;,&#39;books&#39;:books})def post(self,request):new_name&#61;self.request.POST.get(&#39;author_name&#39;)# bood_id &#61;self.request.POST.get(&#39;book&#39;) bood_id &#61;self.request.POST.getlist(&#39;book&#39;) # getlist:键值对应的是一个列表的时候需要用getlistprint(bood_id)#[&#39;1&#39;, &#39;2&#39;, &#39;3&#39;]#创建作者对象author_obj&#61;models.Author.objects.create(author_name&#61;new_name)#建立作者和书籍得关系#print(models.Author.books,type(models.Author.books))#
author_obj.books.set(bood_id)return self.get(request)class Editauthor(View):def get(self,request,edit_id):books &#61; models.Book.objects.all()author_obj &#61; models.Author.objects.filter(id&#61;edit_id).first()return render(request,&#39;author_edit.html&#39;,{&#39;books&#39;:books,&#39;author_obj&#39;:author_obj,&#39;base&#39;:&#39;base.html&#39;})def post(self,request,edit_id):#获取修改的对象new_name &#61; self.request.POST.get(&#39;author_name&#39;)book_id &#61; self.request.POST.getlist(&#39;book&#39;)author_obj &#61; models.Author.objects.filter(id&#61;edit_id).first()#方式一author_obj.author_name &#61;new_nameauthor_obj.save()#方式二# author_obj &#61; models.Author.objects.filter(id&#61;edit_id)# author_obj.update(author_name&#61;new_name)#author_obj.first().books.set(book_id)
author_obj.books.set(book_id)return redirect(reverse(&#39;author&#39;))
3>ORM的聚合和分组
from django.db.models import Sum,Avg,Max,Min,Count
#聚合 aggregate终止语句
ret &#61; models.Book.objects.aggregate(Sum(&#39;price&#39;),Count(&#39;price&#39;),max&#61;Max(&#39;price&#39;))
print(ret,type(ret))
#{&#39;max&#39;: 255, &#39;price__sum&#39;: 1928, &#39;price__count&#39;: 11}
#查Book的对象的所有内容,拼接一个Count(&#39;author&#39;)字段,相当于把聚合结果放到对象中
ret &#61; models.Book.objects.annotate(Count(&#39;author&#39;)).values()
for i in ret:print(i)#每个出版社价格最低的书
ret2 &#61; models.Publisher.objects.annotate(Min(&#39;bk__price&#39;)).values()
print(ret2)#values按指定字段去分组
ret3&#61;models.Book.objects.values(&#39;publisher__name&#39;).annotate(min&#61;Min(&#39;price&#39;)).values(&#39;publisher__name&#39;,&#39;min&#39;)
# ret3&#61;models.Book.objects.values(&#39;publisher__name&#39;).annotate(min&#61;Min(&#39;price&#39;)).values() 错误 ,分组之后只能取分组相关的字段
for i in ret3:print(i)
#SELECT &#96;app01_publisher&#96;.&#96;name&#96;, MIN(&#96;app01_book&#96;.&#96;price&#96;) AS &#96;min&#96; FROM &#96;app01_book&#96; INNER JOIN &#96;app01_publisher&#96;
# ON (&#96;app01_book&#96;.&#96;publisher_id&#96; &#61; &#96;app01_publisher&#96;.&#96;id&#96;) GROUP BY &#96;app01_publisher&#96;.&#96;name&#96; ORDER BY NULL;#查询大于一个作者的书
ret &#61; models.Book.objects.annotate(count&#61;Count(&#39;author&#39;)).filter(count__gt&#61;1).values()
for i in ret:print(i)#根据作者的数量排序
ret &#61;models.Book.objects.annotate(count&#61;Count(&#39;author&#39;)).order_by(&#39;count&#39;)#查询每个作者出书的总价格
ret &#61; models.Author.objects.annotate(Sum(&#39;books__price&#39;)).values()
4>ORM的F,Q查询和事务
from django.db.models import F,Q#F 用来取表中动态的字段
#查询库存小于销量的书籍 比较动态的字段
ret &#61; models.Book.objects.filter(inventory__lt&#61;F(&#39;sale&#39;)).values()
# print(ret)
ret1 &#61; models.Book.objects.update(sale&#61;F(&#39;sale&#39;)*2)#Q 可以将查询条件变成 或的 关系
#逗号连接的条件都是 and的关系
ret &#61; models.Book.objects.filter(id__gte&#61;7,title&#61;&#39;史记&#39;).values()
print(ret)#使用Q查询可以 使用 与 或 非三种关系
ret2 &#61; models.Book.objects.filter(Q(id__lt&#61;2)|Q(id__gte&#61;13)).values()
print(ret2)
ret3 &#61; models.Book.objects.filter(Q(id__lt&#61;2) & Q(id__gte&#61;13)).values()
print(ret3)
ret4&#61;models.Book.objects.filter(~Q(Q(id__lt&#61;2)|Q(id__gte&#61;13))).values()
for i in ret4:print(i)
#事务 出现异常数据库不进行任何操作
from django.db import transaction
try:with transaction.atomic():models.Book.objects.update(price&#61;F(&#39;price&#39;)&#43;50)models.Book.objects.get(id&#61;100) #异常models.Book.objects.update(price&#61;F(&#39;price&#39;)-30)
except Exception as e:print(e)
2.模板之自定义filter,simple_tag,inclusion_tag
1>初始化步骤
a.在app下创建一个名为templatetags(名字不可变)的python包
b. 在templatetags下创建python文件 名字可随意 my_tags
c.导入并实例化
my_tags.py
from django import templateregister&#61;template.Library() #register 固定的名字
2>filter的使用
my_tags.py
&#64;register.filter(name&#61;&#39;ddb&#39;)
def add_str(value,arg):ret&#61;f&#39;{value}_{arg}&#39;return rethtml
#加载文件
{% load my_tags %}
{#{{ &#39;alex&#39;|add_str:&#39;xxxb&#39; }}#}
#使用文件定义的函数
{{ &#39;alex&#39;|ddb:&#39;xxxb&#39; }}
#浏览器:alex_xxxb views.py
def tag_test(request):return render(request,&#39;tag_test.html&#39;)
3>simple_tag的使用
my_tags.py
#装饰器后面要加括号,否则在pychram中可以使用但是会漂黄
&#64;register.simple_tag()
def string_join(*args,**kwargs):ret &#61; &#39;_&#39;.join(args) &#43; &#39;*&#39;.join(kwargs.values())return rethtml
{% load my_tags %}
{% string_join &#39;dddd&#39; &#39;sdfsdf&#39; k1&#61;&#39;erwer&#39; k2&#61;&#39;2131&#39; %}
#浏览器:dddd_sdfsdferwer*2131
4>inclusion_tag的使用
my_tags.py
&#64;register.inclusion_tag(&#39;pagination.html&#39;)
def pagination(total,page):return {&#39;total&#39;:range(1,total&#43;1),&#39;page&#39;:page}author_list.html
#需要使用代码段的页面
{% load my_tags %}{% pagination 6 1%}pagination.html
#代码段的渲染{% for num in total %}{% if num &#61;&#61; page %}
流程演示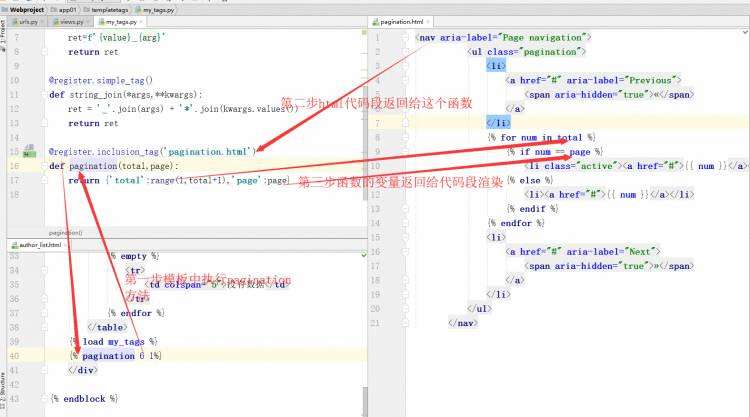
3.COOKIE和session
1>COOKIE
保存在浏览器本地的一组键值对,是服务器让浏览器进行设置的,由服务器决定是否设置,浏览器访问服务器的时候有COOKIE可以自动登陆
COOKIE的本质:用来保持服务器与客户端的会话状态
设置COOKIE:服务器对请求的url(例如http://127.0.0.1:8000/app01/login/) 设置了一个响应头的键值对 Set-COOKIE: is_login&#61;1; Path&#61;/,随后访问的url都会在request请求头中携带这个设置的COOKIE值
删除COOKIE:服务器对请求的url(例如http://127.0.0.1:8000/app01/logout)设置了一个响应头的键值对 Set-COOKIE is_login&#61;""; expires&#61;Thu, 01-Jan-1970 00:00:00 GMT; Max-Age&#61;0; Path&#61;/,随后访问的url的request请求头将没有COOKIE值
COOKIE的方法
普通COOKIE ret是httpresponse对象
设置:ret.set_COOKIE(key,value&#61;&#39;&#39;,max_age&#61;None path&#61;&#39;/&#39;)
字段解释:key:COOKIE键 value:COOKIE值 ,max_age:x秒 COOKIE超时时间 ,path:COOKIE生效的路径
取COOKIE:request.COOKIES.get(&#39;键&#39;)
加密COOKIE
设置:ret.set_signed_COOKIE(&#39;is_login&#39;,&#39;abc&#39;,salt&#61;&#39;xxxx&#39;)
salt:加密盐
取COOKIE:request.get_signed_COOKIE(&#39;is_login&#39;,salt&#61;&#39;xxxx&#39;,default&#61;&#39;&#39;,max_age&#61;5)
删除COOKIE
#对浏览器中的COOKIE 键与值进行删除
ret.delete_COOKIE(&#39;is_login&#39;)
#实例
def login_required(func):def inner(request,*args,**kwargs):# is_login &#61; request.COOKIES.get(&#39;is_login&#39;)is_login &#61; request.get_signed_COOKIE(&#39;is_login&#39;,salt&#61;&#39;xxxx&#39;,default&#61;&#39;&#39;,max_age&#61;5)# 对于加密的来说,不加default参数会获取不到COOKIE的值而抛出异常KeyError at / app01 / publisher_list /&#39;is_login&#39;print(is_login)if is_login !&#61;&#39;abc&#39;:returnurl&#61;request.path_infoif returnurl:return redirect((f&#39;{reverse("login")}?return_url&#61;{returnurl}&#39;))return redirect(reverse(&#39;login&#39;))else:ret &#61; func(request,*args,**kwargs)return retreturn innerdef login(request):error_msg&#61;&#39;&#39;if request.method &#61;&#61; &#39;POST&#39;:username &#61; request.POST.get(&#39;username&#39;,&#39;&#39;)password &#61; request.POST.get(&#39;password&#39;,&#39;&#39;)if username &#61;&#61; &#39;alex&#39; and password &#61;&#61; &#39;123&#39;:return_url&#61;request.GET.get(&#39;return_url&#39;)if return_url:ret &#61; redirect(return_url)else:ret &#61; redirect(reverse(&#39;publisher&#39;))# ret.set_COOKIE(&#39;is_login&#39;,&#39;1&#39;,max_age&#61;5,path&#61;&#39;/app01/pub_list/&#39;)#不加密的COOKIE 超时时间5秒,COOKIE生效的路径ret.set_signed_COOKIE(&#39;is_login&#39;,&#39;abc&#39;,salt&#61;&#39;xxxx&#39;) #加密的COOKIEreturn reterror_msg &#61; &#39;用户名或密码错误&#39;return render(request,&#39;login.html&#39;,{&#39;error_msg&#39;:error_msg})
def logout(request):
#删除COOKIE
ret &#61; redirect(reverse(&#39;login&#39;))
ret.delete_COOKIE(&#39;is_login&#39;)
return ret
2>session
COOKIE的缺陷:本身最大支持4096的字节,本身的键值全都保存在客户端不安全
session:浏览器只保存服务器分发的sessionid,也就是键, session_data(值)保存在服务器中,没有长度限制.服务器根据sessionid识别用户和保持会话时间
session的设置
#request.session.setdefault(&#39;is_login&#39;,1)
request.session[&#39;is_login&#39;]&#61;&#39;1&#39;
request.session.set_expiry(5) #只删除浏览器的COOKIE 每次新连接的时候都使用新的COOKIE,数据库中的数据还保存,相当于一个新的客户端取连接
session的获取
print(request.session)
#
is_login &#61; request.session.get(&#39;is_login&#39;)
#request.session[&#39;is_login&#39;]
session的删除
del request.session[&#39;is_login&#39;] #浏览器和数据库session值都在,只是在程序逻辑中删除了KEY
request.session.delete()#删除数据库session值,不删除浏览器的COOKIE(sessionid),但每次重新访问url的时候都会重新得到一个新的sessionid,数据库也会有此ID相对应的值
request.session.flush() #同时删除浏览器的COOKIE(sessionid)和数据库session值
session的配置
SESSION_ENGINE &#61; &#39;django.contrib.sessions.backends.db&#39;
SESSION_COOKIE_AGE &#61; 1209600
4.django的中间件
1>django的请求流程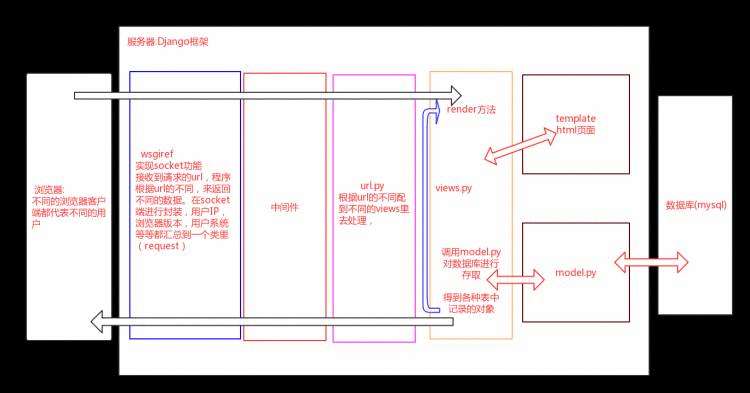
2>django中间件的5种方法
a.process_request
#注册自定义的中间件
#settings.py
MIDDLEWARE &#61; [&#39;django.middleware.security.SecurityMiddleware&#39;,&#39;django.contrib.sessions.middleware.SessionMiddleware&#39;,&#39;django.middleware.common.CommonMiddleware&#39;,&#39;django.middleware.csrf.CsrfViewMiddleware&#39;,&#39;django.contrib.auth.middleware.AuthenticationMiddleware&#39;,&#39;django.contrib.messages.middleware.MessageMiddleware&#39;,&#39;django.middleware.clickjacking.XFrameOptionsMiddleware&#39;,&#39;app01.middlewares.mymiddleware.MD1&#39;,&#39;app01.middlewares.mymiddleware.MD2&#39;,
]#mymiddleware.py
from django.utils.deprecation import MiddlewareMixin
from django.shortcuts import HttpResponse
class MD1(MiddlewareMixin):def process_request(self,request):print(&#39;MD1 reuqest内存地址&#39;,id(request))print(&#39;MD1的process_request&#39;)# return HttpResponse(&#39;MD1的process_request&#39;) 如果返回,后面的流程不执行了 包括MD2中的process_requestclass MD2(MiddlewareMixin):def process_request(self,request):print(&#39;MD2的process_request&#39;)# return HttpResponse(&#39;MD2的process_request&#39;)#views.py
def index(request):print(&#39;index request内存地址&#39;,id(request))print(&#39;这是index视图&#39;)return HttpResponse(&#39;视图index中的ok&#39;)
#执行时间
在视图函数执行之前
#参数
request(请求对象) 与视图中的request是一个对象
#执行顺序
按照settings中注册的顺序, 顺序执行
#返回值
正常流程:返回一个None
response对象,哪个process_request 只要return response对象之后 直接不执行后面的流程,按照注册顺序决定返回顺序#无返回值的执行结果
&#39;&#39;&#39;
MD1 reuqest内存地址 1815873977760
MD1的process_request
MD2的process_request
index request内存地址 1815873977760
这是index视图
&#39;&#39;&#39;
#当MD1与MD2都有返回值时的执行结果
&#39;&#39;&#39;
MD1 reuqest内存地址 2104042671576
MD1的process_reques
&#39;&#39;&#39;
#当MD2有返回值,MD1无返回值时的执行结果
&#39;&#39;&#39;
MD1 reuqest内存地址 2118239296984
MD1的process_request
MD2的process_request
&#39;&#39;&#39;
b.process_response
class MD1(MiddlewareMixin):def process_request(self,request):# print(&#39;MD1 reuqest内存地址&#39;,id(request))print(&#39;MD1的process_request&#39;)# return HttpResponse(&#39;MD1的process_request&#39;)def process_response(self,request,response):print(&#39;MD1 response内存地址&#39;,id(response))print(&#39;MD1的process_response&#39;)return responseclass MD2(MiddlewareMixin):def process_request(self,request):print(&#39;MD2的process_request&#39;)# return HttpResponse(&#39;MD2的process_request&#39;)def process_response(self,request,response):print(&#39;MD2 response内存地址&#39;, id(response))print(&#39;MD2的process_response&#39;)return response#执行时间
在视图函数执行之后#参数
request(请求对象),与视图中的request时一个对象
response(响应对象):视图返回的响应对象#执行顺序
按照注册的顺序 倒叙返回response对象#返回值
response对象:必须返回#正常流程的执行结果
&#39;&#39;&#39;
MD1的process_request
MD2的process_request
这是index视图
视图 2103546390848
MD2 response内存地址 2103546390848
MD2的process_response
MD1 response内存地址 2103546390848
MD1的process_response
&#39;&#39;&#39;
process_request与process_response流程图
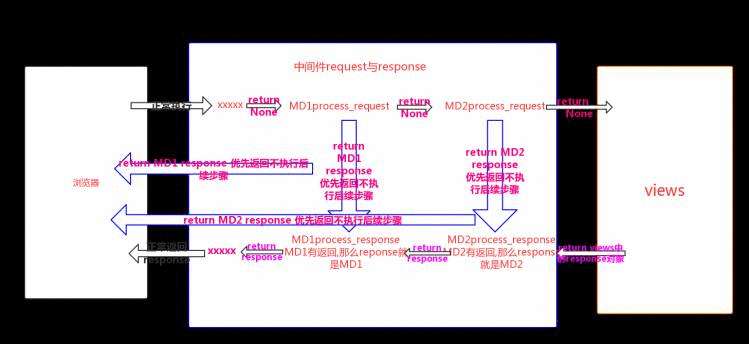
c.process_view
class MD1(MiddlewareMixin):def process_request(self,request):print(&#39;MD1的process_request&#39;)def process_response(self,request,response):print(&#39;MD1的process_response&#39;)return responsedef process_view(self,request,view_func,view_args,view_kwargs):print(view_func)print(view_args)print(view_kwargs)print(&#39;MD1的process_view&#39;)# return HttpResponse(&#39;MD1 process view&#39;)class MD2(MiddlewareMixin):def process_request(self,request):print(&#39;MD2的process_request&#39;)def process_response(self,request,response):print(&#39;MD2的process_response&#39;)return responsedef process_view(self,request,view_func,view_args,view_kwargs):print(&#39;MD2的process_view&#39;)#执行时间
在视图函数执行之前,在process_request之后,在路由匹配之后#参数
request :
请求对象 和视图的参数是一个
view_func&#xff1a;视图函数
view_args&#xff1a;视图函数的位置参数
view_kwargs&#xff1a;视图函数的关键字参数#执行顺序
按照中间件注册顺序,顺序执行#返回值
None:正常流程
response对象 : 如果中间件中的process_view有return response对象,后续的process_view 以及视图都不执行, 直接按照process_response倒叙返回#正常流程执行结果
&#39;&#39;&#39;
MD1的process_request
MD2的process_request
(&#39;1&#39;,)
{&#39;xxx&#39;: 222}
MD1的process_view
MD2的process_view
这是index视图
MD2的process_response
MD1的process_response
process_request,process_response与process_views流程图
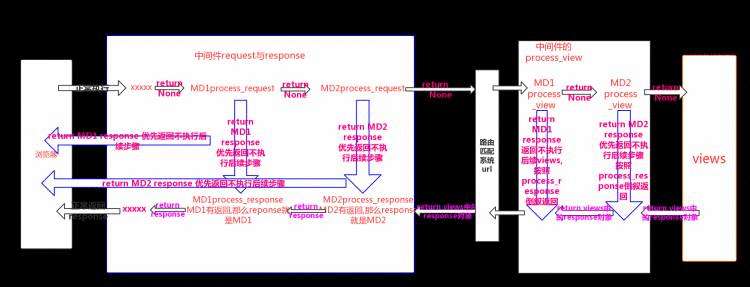
d.process_template_response
mymiddleware.py
class MD1(MiddlewareMixin):def process_request(self,request):print(&#39;MD1的process_request&#39;)def process_response(self,request,response):print(&#39;MD1的process_response&#39;)return responsedef process_view(self,request,view_func,view_args,view_kwargs):print(&#39;MD1的process_view&#39;)def process_template_response(self,request,response):print(&#39;MD1的process_template_response&#39;)return responseclass MD2(MiddlewareMixin):def process_request(self,request):print(&#39;MD2的process_request&#39;)def process_response(self,request,response):print(&#39;MD2的process_response&#39;)return responsedef process_view(self,request,view_func,view_args,view_kwargs):print(&#39;MD2的process_view&#39;)def process_template_response(self, request, response):print(&#39;MD2的process_template_response&#39;)return response
views
def index(request,*args,**kwargs):print(&#39;这是index视图&#39;)ret &#61; HttpResponse(&#39;视图index中的ok&#39;)def pro_template():return HttpResponse(&#39;这是xxxx&#39;)ret.render &#61;pro_templatereturn ret
#执行时间
在视图执行之后
触发条件:视图返回响应对象之后有一个render的方法#参数
request(请求对象),与视图中的request时一个对象
response(响应对象):视图返回的响应对象#执行顺序
按注册顺序倒叙执行#返回值
必须返回response对象#正常流程执行结果
&#39;&#39;&#39;
MD1的process_request
MD2的process_request
MD1的process_view
MD2的process_view
这是index视图
MD2的process_template_response
MD1的process_template_response
MD2的process_response
MD1的process_response
&#39;&#39;&#39;
e.process_exception
class MD1(MiddlewareMixin):def process_request(self,request):print(&#39;MD1的process_request&#39;)def process_response(self,request,response):print(&#39;MD1的process_response&#39;)return responsedef process_view(self,request,view_func,view_args,view_kwargs):print(&#39;MD1的process_view&#39;)def process_template_response(self,request,response):print(&#39;MD1的process_template_response&#39;)return responsedef process_exception(self,request,exception):print(exception)print(&#39;MD1的process_exception&#39;)class MD2(MiddlewareMixin):def process_request(self,request):print(&#39;MD2的process_request&#39;)def process_response(self,request,response):print(&#39;MD2的process_response&#39;)return responsedef process_view(self,request,view_func,view_args,view_kwargs):print(&#39;MD2的process_view&#39;)def process_template_response(self, request, response):print(&#39;MD2的process_template_response&#39;)return responsedef process_exception(self, request, exception):print(exception)print(&#39;MD2的process_exception&#39;)return HttpResponse(str(exception))
#执行时间
触发条件:视图层面有错误之后去执行#参数
request(请求对象和视图的参数一样)
exception:错误对象#执行顺序
按照中间件注册顺序倒叙执行#返回值
None:正常报错
response对象:之后的中间件的process_excetion方法都不行了,之后倒叙执行所有中间件的process_response#执行结果
&#39;&#39;&#39;
MD1的process_request
MD2的process_request
MD1的process_view
MD2的process_view
这是index视图
invalid literal for int() with base 10: &#39;aaa&#39;
MD2的process_exception
MD2的process_response
MD1的process_response&#39;&#39;&#39;
五种方法完整的中间件的流程图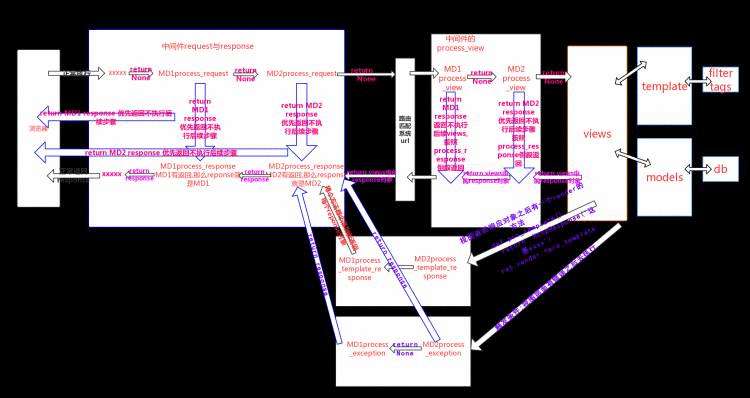
3>django的生命周期
&#39;&#39;&#39;
1.浏览器发起url请求,wsgi接收请求的url进行socket封装(用户IP,浏览器版本,用户系统等等汇总到一个request类中)
2.经过所有的中间件(5种方法都存在的情况):a.顺序执行每个注册的中间件的process_request,正常流程返回None,一旦有某个process_request返回了response后面的流程都不走,直接返回给浏览器.b.路由系统匹配url之后,顺序执行每个process_view,正常流程返回None,一旦某个process_view返回了None,后面的流程都不走,直接倒叙执行每个process_response,最后返回浏览器.c.views视图与model(db处理)和template(filter和tags处理)进行交互之后,拿到对象用httpresponse对象返回给 process_reponse ,倒叙执行每个process_response,最后返回给浏览器d.如果视图返回对象之后有一个render方法,可以触发process_template_response,倒叙执行每个process_template_response,必须返回一个response给process_response,倒叙执行每个process_response,最后返回给浏览器f.如果视图层面有异常会触发process_exception且不会去执行process_template_response,倒叙执行每个process_exception,一但有一个process_exception返回了response,后续的process_exception都不执行,直接返回给process_response去倒叙执行每个process_response,最后返回给浏览器.
&#39;&#39;&#39;







 京公网安备 11010802041100号
京公网安备 11010802041100号