小李:老王,早上又吃鸡蛋灌饼不加肠啊!
老王:是啊,我的肠又被捐出去了!小李,看你脸色,这又是昨天加班了。
小李:可别提了,昨天logstash机器又顶不住了,还被运维给鄙视了一番,看来我得学习学习你那牛叉的数据接入系统了,上线以来都没出过问题。
老王:好啊,我给你讲一讲,巴拉巴拉....
周围的人:这人不是有什么大病吧....
老王:我还是抓紧吃完去公司给你讲吧
小李:好吧!
一提到把kafka数据落地到hdfs,大家最先想到的一定是logstash,由于logstash很笨重,当数据量很大时,我们经常会遇到资源不够用的问题,也没办法精确控制hdfs生成文件的大小。为了不影响后续hive分析的性能,我们经常还需要把一些小文件进行合并(小文件是hdfs中不得不面对的问题),这不仅拉长了链路,也会造成不必要的资源浪费。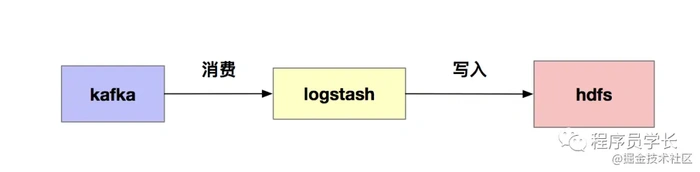
为了避免资源浪费,降低数据接入链路,我们实现了一个数据接入系统。主要优点如下所示。
1.通过配置文件可以快速实现数据接入需求(针对kafka->hdfs的场景)。
2.实现精确消费一次(Exactly-once),即保证数据不丢不重复。
3.可以手动配置生成文件的大小。
整体架构如下图所示。
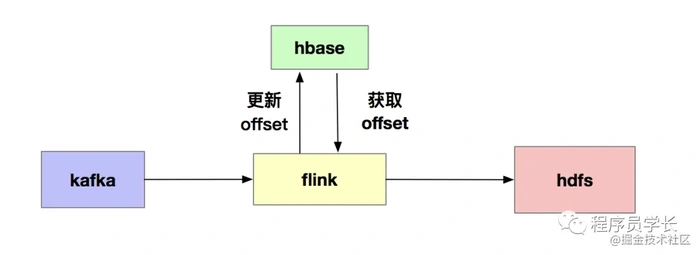
我们使用目前很火的flink消费kafka(关于flink和spark的优缺点大家自行百度),然后定时的更新offset到hbase中,以满足精确消费一次的场景。我们的flink任务也很简单,主要有两个算子组成kafkasource和parquetsink,如图所示。
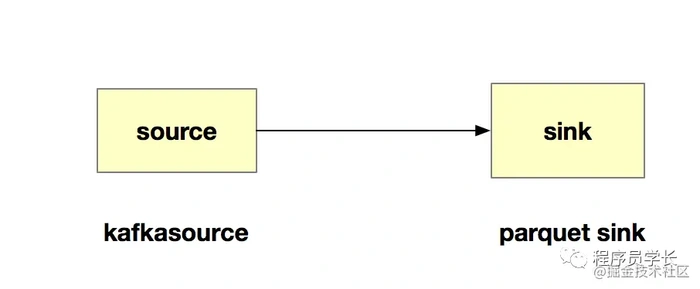
1.kafkasource
这里的kafkasource主要是用来消费kafka的数据,不过这里有一点需要注意,我们在消费kafka的时候,需要从hbase读取相应的offset信息,如果没读到offset信息,表明这个任务是第一次启动,我们从该消费组的位置读。如果读到了offset信息,为了避免重复消费,我们需要从该offset位置开始读(因为该offset之前的数据已经成功落地到hdfs上了)。 这里为了实现这个功能,我们需要重新实现flink自带的FlinkKafkaConsumerBase类,我们需要在内部添加从hbase读取offset的逻辑。
long offset = offsetManager.getPartitionOffset(seedPartition.getTopic(), seedPartition.getPartition());
if (offset != -1) {
subscribedPartitionsToStartOffsets.put(seedPartition, offset);
} else {
subscribedPartitionsToStartOffsets.put(seedPartition, startupMode.getStateSentinel());
}

这样我们就可以实现在flink checkpoint失败时,从hbase中读取offset信息,来控制kafka从哪个位置开始消费。这里还有一点需要注意,我们在任务启动时,也需要添加这块代码逻辑。你可以自己思考一下。
2.parquetsink
parquetsink这里主要是实现往hdfs写入数据,我们从parquet源码里可以把写数据成parquet文件的逻辑copy出来,自己实现往hdfs写parquet文件。这里就不重点强调了,这里主要看一下和hbase的交互流程。
我们这里主要是重写CheckpointedFunction里的snapshotState方法,该方法每次在checkpoint的时候,都会被调用。所以我们在该方法里实现文件的生成和更新hbase中offset的工作。这里首先会判断生成文件的大小是否已经满足我们设置的大小,如果没有满足,我们就不做处理。如果满足我们设置的文件大小,我们会把这个临时文件上线,然后更新hbase中offset的信息。关键代码逻辑如下图所示。
val isSuccess = commitPendingToStable(writerState.getParentPath, writerState.getFileName)
if (isSuccess) {
offsetManager.saveOffset(partitionInfo.getTopic, partitionInfo.getPartition, writerState.getEndOffset + 1)
}
到目前为止,我们已经把关键点都聊完了。我们来总结一下。看一下整体的执行流程。
在任务执行中,flink定时执行checkpoint,假设为10s,然后就会调用 snapshotState方法去检测文件大小是否满足我们配置的大小,如果不满足,不做处理。如果满足,我们把文件上线,然后提交offset到hbase。这就代表着hbase中存储的offset表示我们已经成功落地的数据。如果checkpoint失败或者任务挂掉,由于我们重启或者checkpoint失败恢复任务时,我们是从hbase中读取offset信息,因此可以保证精确一次消费,保证落地的数据不丢失不重复。
今天我们就聊到这里,更多有趣知识,欢迎关注公众号[程序员学长]。如果对本文有什么疑问点,欢迎留言讨论。









 京公网安备 11010802041100号
京公网安备 11010802041100号