作者:荷-蘭水 | 来源:互联网 | 2023-06-11 19:22
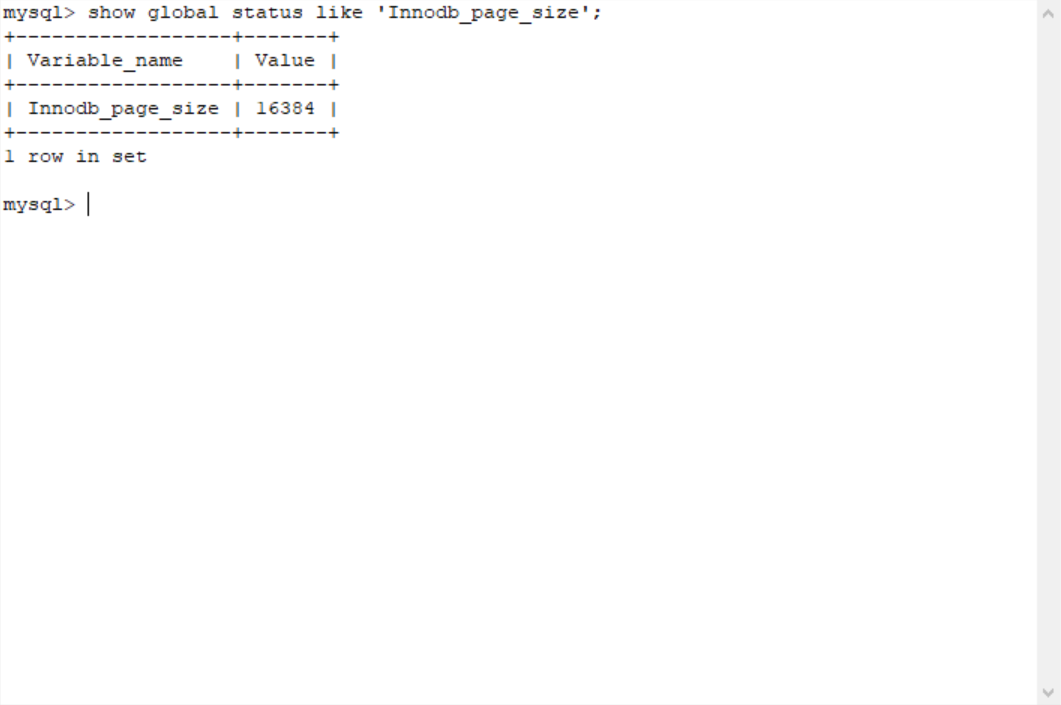
什么是索引 在关系数据库中,索引是一种对数据库表中一列或多列的值进行排序 的一种存储结构(数据结构),索引解决的问题是查询速度慢 。容易产生理解偏差的点解释一下:
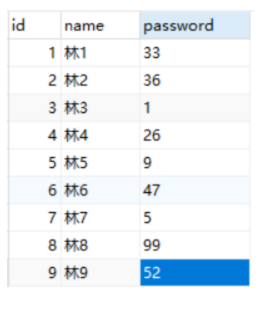
索引是针对表来说的,不是针对数据库来说的(建表的sql语句中的index就是索引)。 InnoDB存储引擎不是MySQL自己的,而是Innobase Oy公司开发的,该公司后被甲骨文公司并购 索引的数据结构演进 链表结构 假设用户表中有字段id,name,password。我们需要对这个表进行查询。
select * from user where password = 33 ; select * from user where password = 36 ; select * from user where password = 1 ; select * from user where password = 26 ; select * from user where password = 9 ; select * from user where password = 47 ; select * from user where password = 5 ; select * from user where password = 99 ; select * from user where password = 52 ;
假设表中有1000万条数据,现在要查询第1000万条数据,这样就需要查找1000万次。顺序查找的问题是存储数据的结构是线性的,也就是说想要查询第2条数据,我需要知道第1条数据是什么 。大家可能会考虑到为什么不要数组,直接通过下标就可以查到数据,问题是数组是固定长度的,那么数组长度定义为多少合适呢?
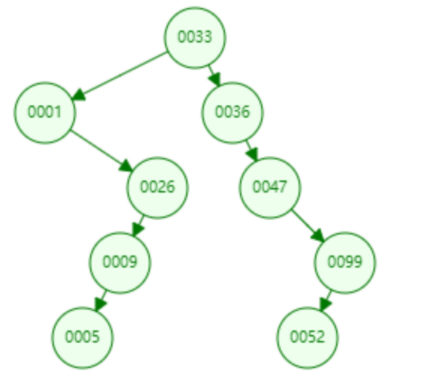
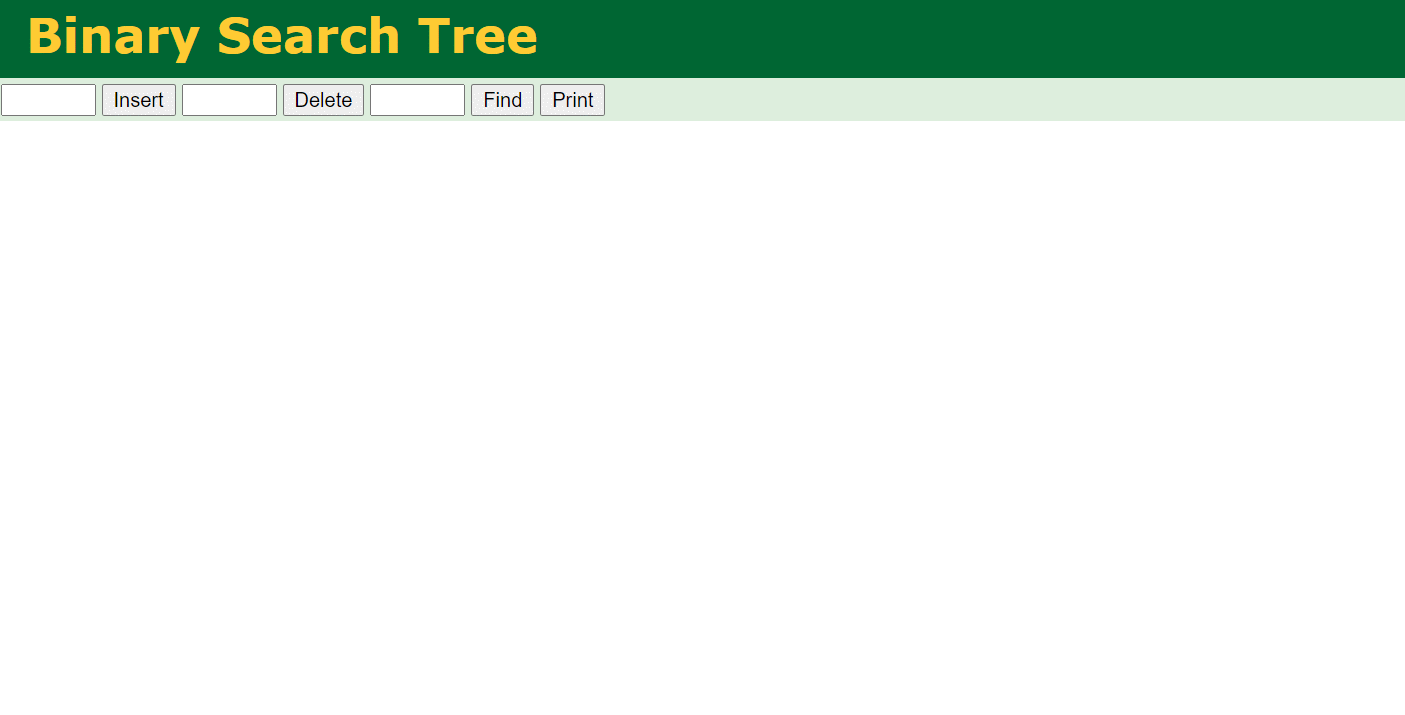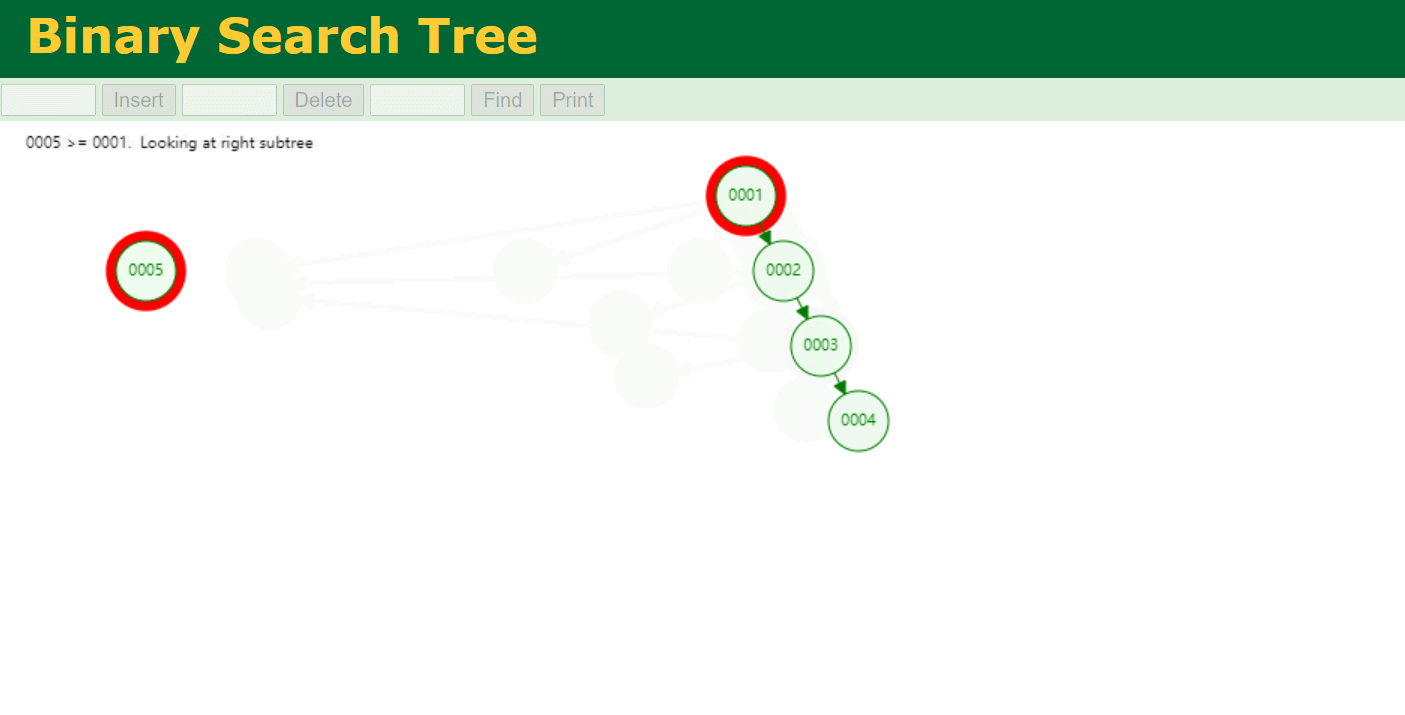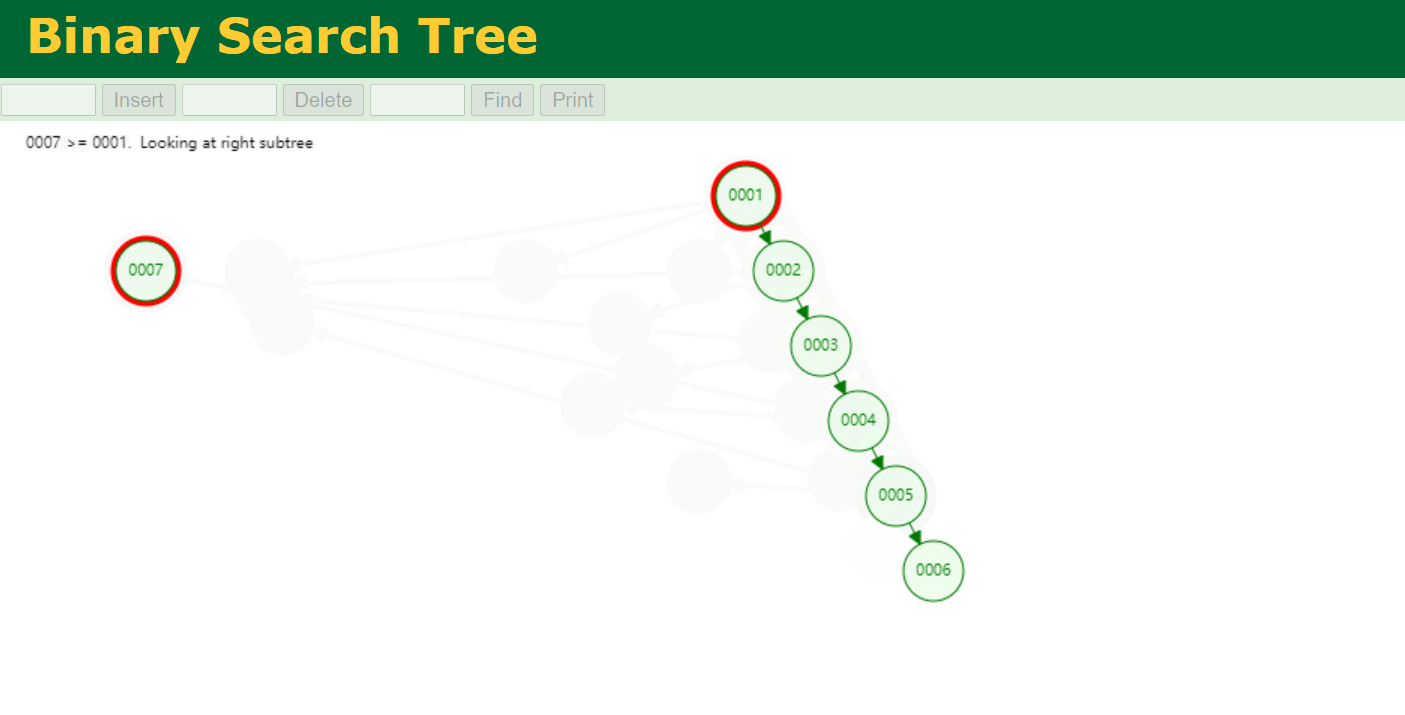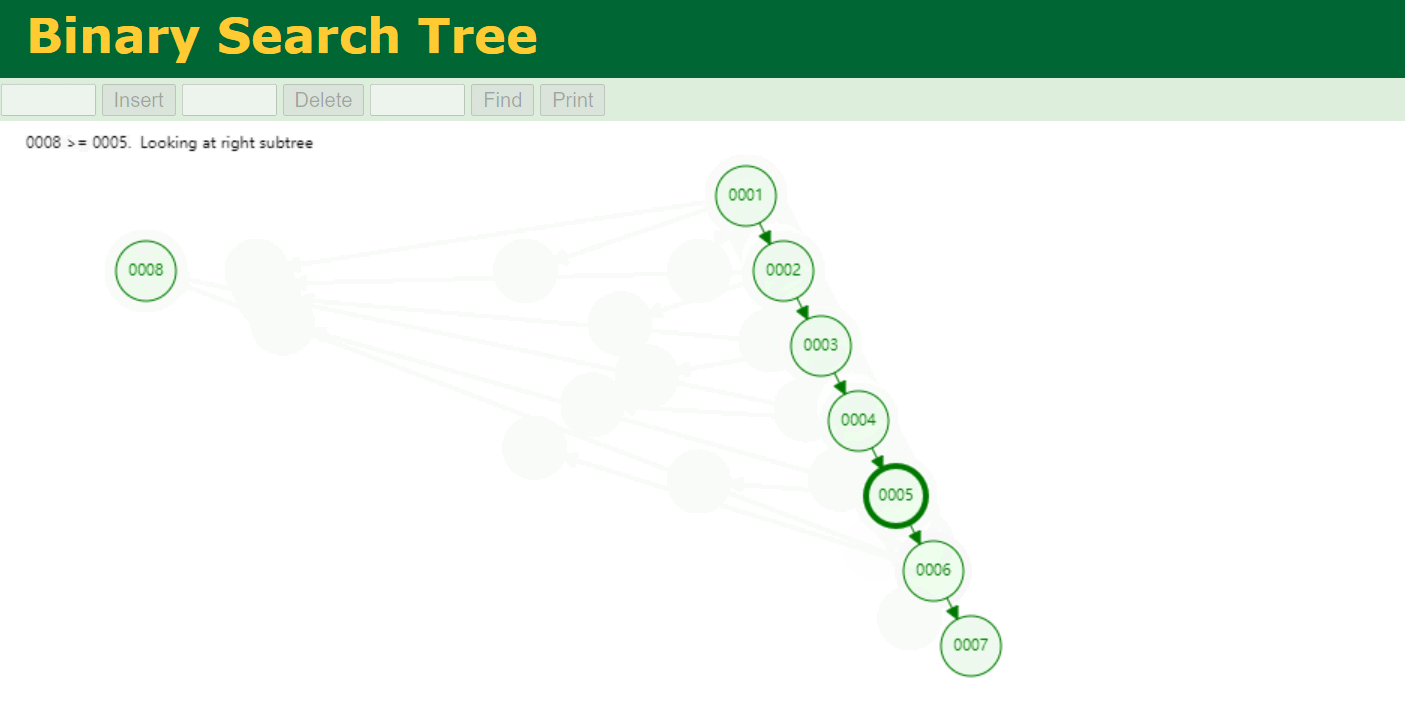
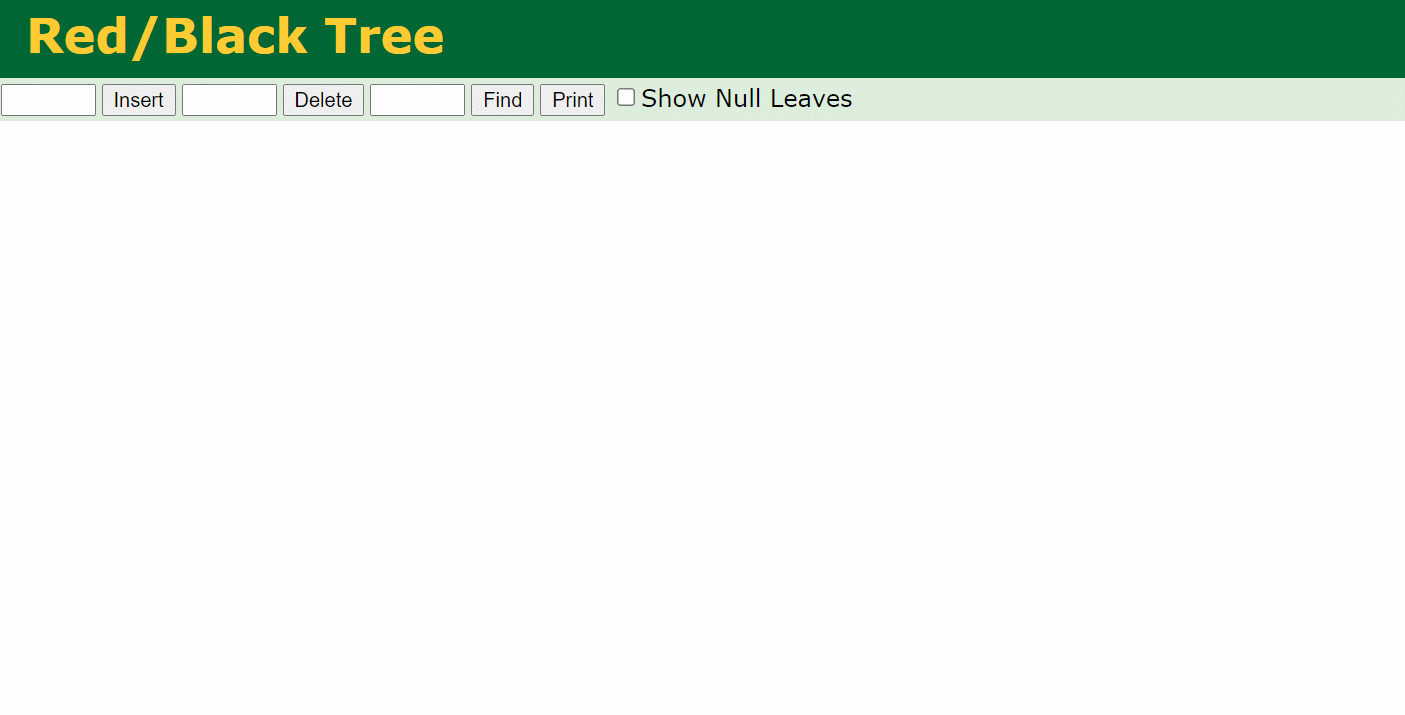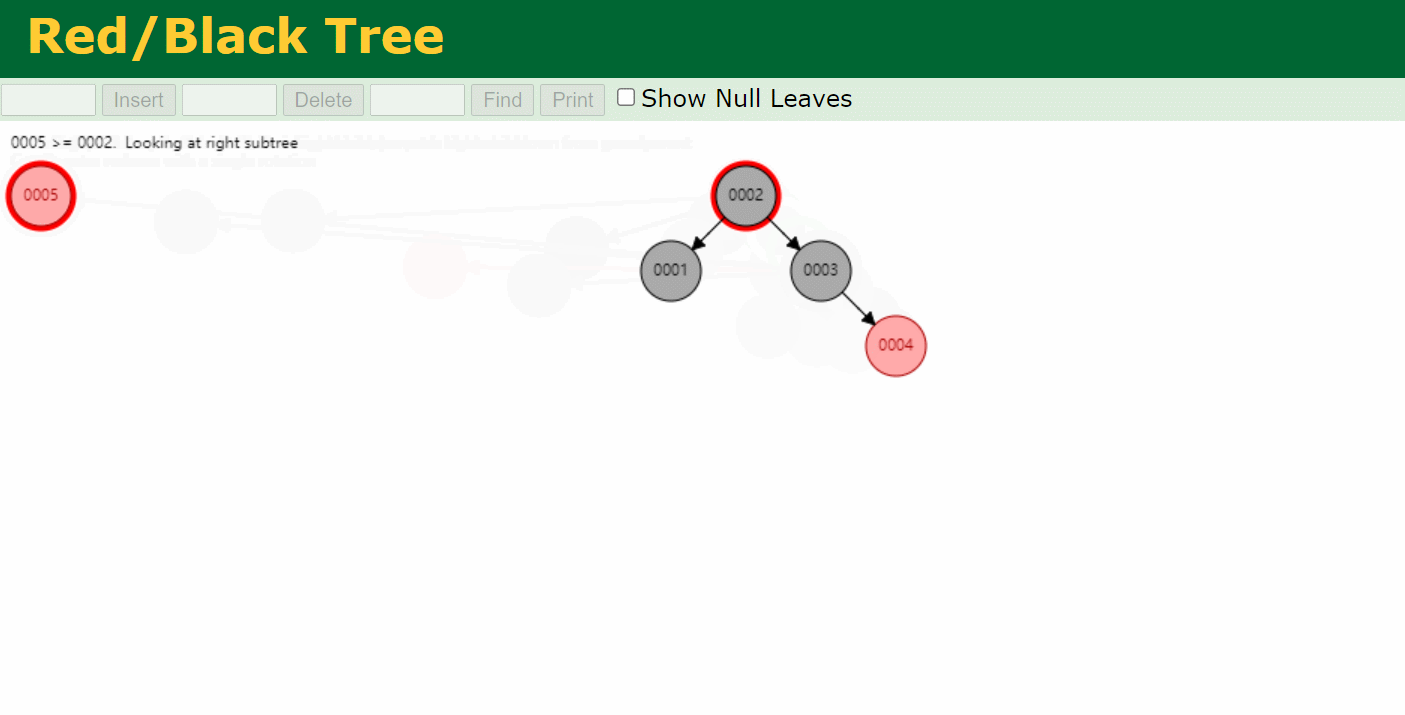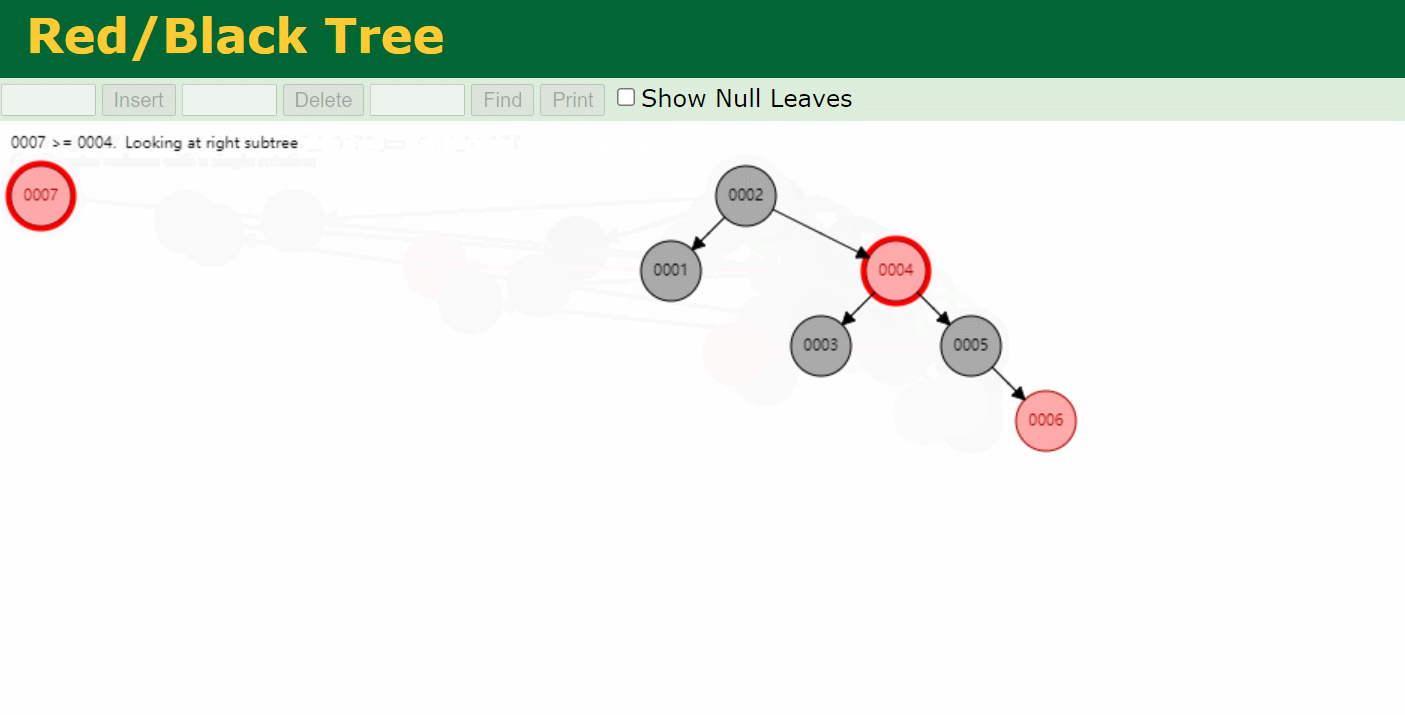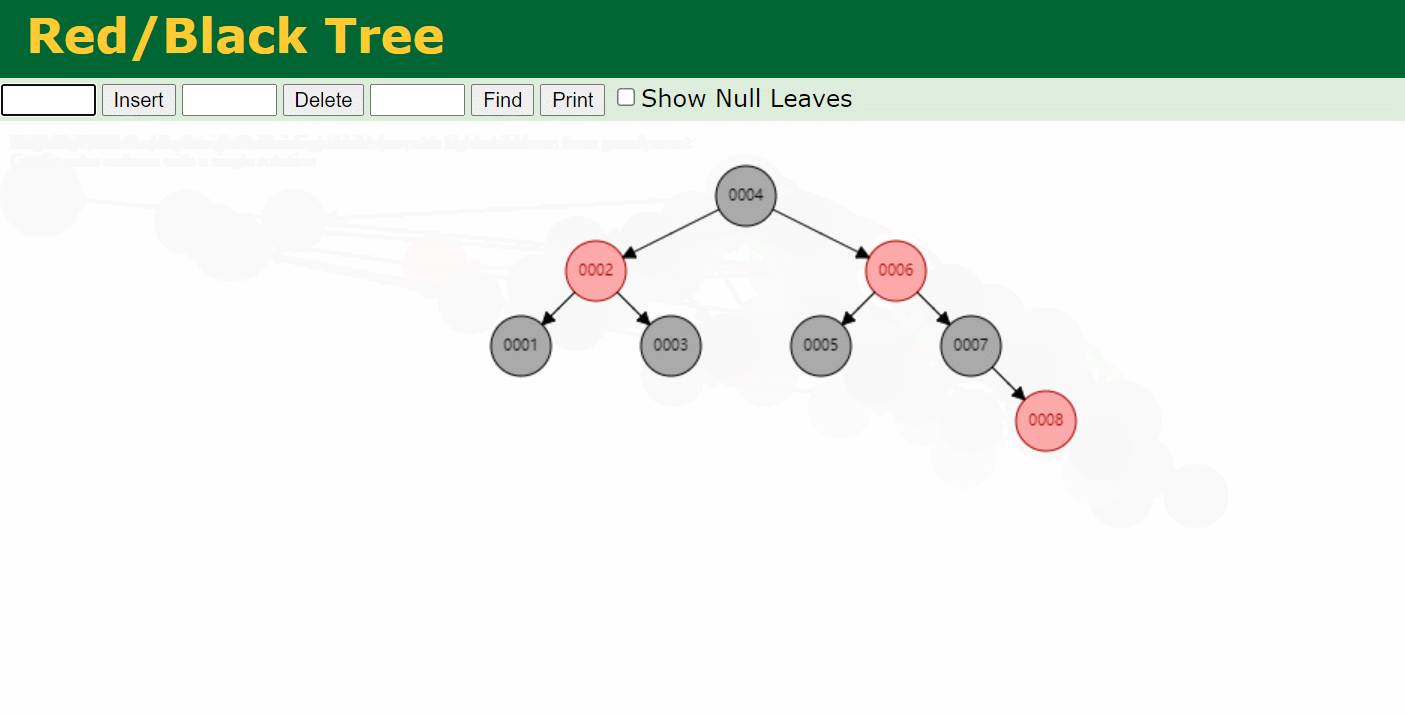
二叉树 要解决链表问题,我们可以使用树来解决,先来看下二叉树,二叉树与链表的区别是链表就一条搜索路径,二叉树有两条搜索路径。上表中对应的二叉树如下。二叉搜索树 通过增加了一条搜索路径,提高了查询效率,查找的效率取决于树的深度(高度) 。
select * from user where password = 33 ; select * from user where password = 36 ; select * from user where password = 1 ; select * from user where password = 26 ; select * from user where password = 9 ; select * from user where password = 47 ; select * from user where password = 5 ; select * from user where password = 99 ; select * from user where password = 52 ;
假设有1~9个数字要存储在二叉树中。由于二叉树的特点是,任一节点的左子节点都小于父节点,右子节点都大于父节点。当插入的数据是单向递增或递减时,二叉树就会变成线性结构,查询效率与链表就一致了 。
红黑树
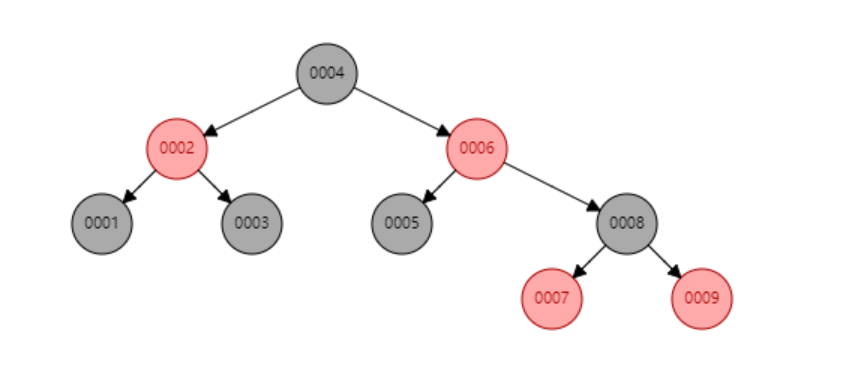
为了解决二叉树变链表的问题,出现了红黑树。红黑树会做一个平衡 。平衡后树的高度就变成了4层,相比于二叉树,效率更高。
B树
B+树
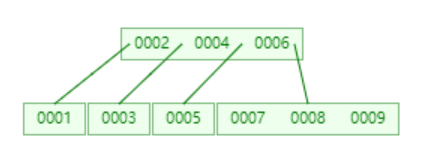
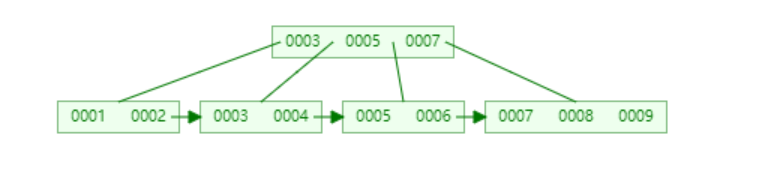
B树中的每个节点都包含指针和数据两部分 ,数据所占据的位置是较大的,我们是否可以考虑第一层第二层只存放指针,将数据都放到第三层。这样单个叶子节点可以存放的指针数量是 1170(16 * 1024 /(8+6))左右,那么高度为3的B+树就可以存储11701170 16个数据(假设索引使用的是bigint类型(java中占8个字节),6是一个指针需要的空间)
细心的小伙伴会发现实际B&#43;树的叶子节点之间会有一个单向的箭头&#xff0c;实际这里的箭头是双向的&#xff0c;图不对。这个箭头代表的是前后叶子节点的存储位置。索引是排序后的数据结构&#xff08;大家可以观察第二行就是有序的&#xff09;。比如查询语句select * from table where num <5&#xff1b;查询时直接取5左边的数据即可&#xff0c;及大提高了效率。
可能有人会有这样的疑问&#xff1a;**为什么不把所有的索引放第一层&#xff0c;这样只要两层不就好了吗&#xff1f;**原因如下
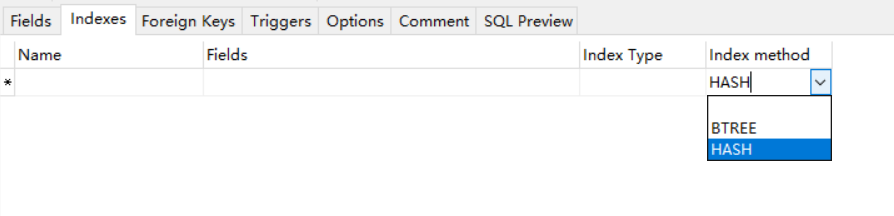
如果第一层有几百M数据&#xff0c;一次磁盘io也加载不了那么多数据 ram中使用是折半查找&#xff0c;几千万数据也不会很快 哈希
既然哈希效率这么快&#xff0c;为什么没有人使用呢&#xff1f;主要有两个原因&#xff1a;
使用场景少&#xff0c;实际场景范围查询更多 哈希会有哈希冲突 最左前缀原理 最左前缀原理就是当表设置了组合索引&#xff0c;那么必须满足最左边字段在前的规定&#xff0c;下面通过实际案例来看。
可以这么思考&#xff1a;索引这么好&#xff0c;为什么不每个字段都加个索引&#xff1f;实际加索引就会生成一颗索引树。大量的索引树是非常占用存储空间的。所以实际场景中一般都是组合索引用的比较多一点。假设上表中创建了组合索引&#xff08;name,password&#xff09;。那么以下sql是否会走这个组合索引的SQL。
select * from user where name &#61; ? and password &#61; ? ; select * from user where password &#61; ? and name &#61; ? ; select * from user where name &#61; ? ;
第一个SQL会走索&#xff1a;左边是name&#xff0c;后面是password&#xff0c;完美用上 第二个SQL不走索引&#xff1a;虽然两个字段都有&#xff0c;但是name在后 第三SQL会走索引&#xff1a;组合索引只要满足组合中的第一个字段即可 聚集索引与非聚集索引 实际场景中&#xff0c;表中虽然有些业务字段可以当做主键&#xff0c;但是一般不这么做。一般都是添加一列作为数据的主键 。这个主键也叫聚集索引&#xff0c;是用来生成主键树的。innodb下这个主树上存有数据的&#xff0c;回主树的过程就称为回表。
如果建表时没有设置主键&#xff0c;那么数据库就尝试查找某个字段没有重复的&#xff0c;用这个字段生成主树。如果没有这样的字段&#xff0c;数据库会为我们生成一个rowid&#xff08;隐藏列&#xff09;&#xff0c;使用隐藏列来生成主树。
学习时思考过的问题及答案 为什么线性结构不用二分查找&#xff1a;因为数据是读到内存里&#xff0c;数据量大的情况下内存放不放的下是个问题 红黑树&#xff0c;二叉平衡树层级高。两千万数据大概32层&#xff0c;32次IO是否能接收&#xff1a;磁盘IO是非常耗时的操作&#xff0c;是从文件中读数据到内存中 B树采用空间换时间&#xff1a;将原来32层变成3层。增加了每次读到内存里数据的多少&#xff0c;减少了树的高度&#xff08;即减少了时间&#xff09; 辅助索引为什么不存所有数据&#xff1f;存两份一样的数据没有意义&#xff0c;还要考虑两棵树的数据同步问题 回表会增加几次IO&#xff1a;具体看主树的层级&#xff0c;如果三层就是3次








 京公网安备 11010802041100号
京公网安备 11010802041100号