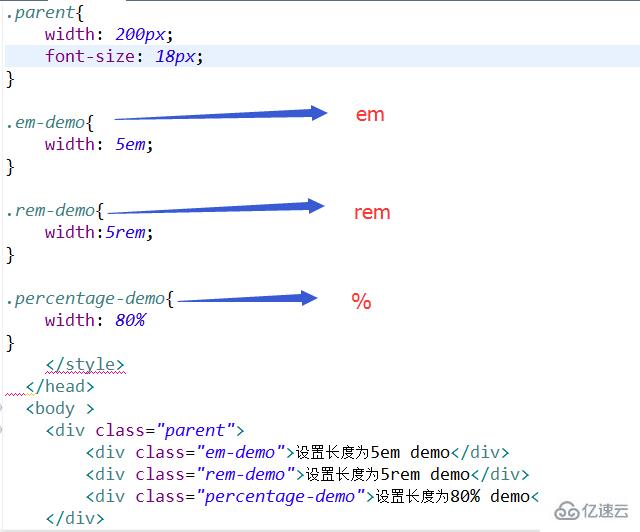
前面从图像处理等切入点, 对 CNN (卷积神经网络) , 从普通神经网络, 到卷积, 池化, 到卷积神经网络, 及BP算法都有有了一点认识了, 当然我其实对图像这块也没有太大兴趣哦, 单纯就是想了解一下而已, 因此, CNN 部分的BP算法推导就没有很仔细去推演, 还有关于梯度消失 的问题也没有谈讨, 就是想纯粹入门了解一波, 估计工作我应该也不太用得到. 作为科普还是可以的哦.
现在来了解一波 RNN (递归神经网络), 主要的切入点呢, 是NLP (自然语言处理) 这方面的, 我是感觉 nlp 有点东西, 涉及词向量表示, 概率计算, 深度神经网络这些,. 但感觉我学不会呀.也写不出代码, 不过, 还是要了解一波的, 毕竟, CNN都了解过了, RNN 岂能停止不前?
当然, 还是要一步步来, 先从最基本的语言模型来整起
小目标
就两个小目标的理解
- 初识 一个新的 NLP 任务
- Language Modeling (自然语言建模)
- 入门一个新的神经网络模型 (Recurrent Neural Networks) 递归神经网络, 坚持 RNN
Language Modeling
材料是英文的, 我这水平, 翻译不太准确, 还是就还原为英文了和中英混合吧, 感觉是有一点 low.
- language modeling is the task of predicting what word comes next (预测下一个词语会是啥)
例如, the students opened ther __ (books, laptops, exams, minds) 根据前面的句子, 预测后面的句子应该是啥.
more formally (从严格的数学证明来看), given a sequence of words \(x^{1}, x^{2}...x^{t}\) compute the probability, distribution of the next word \(x ^({t+1})\) (x 是个向量)
\(P(x^{(t+1)} | x^1, x^2 ... x^t)\). 上标表示状态, 不表示次方哈, 我写的问题.
where the \(x^{(t+1)}\) can be any word in the vocabulary \(V = (w_1, w_2, ..w_v)\) 也是来自词典 V 的哈.
- A system that dose this called a Language Model.
简而言之, 语言模型就是, 已知前一段句子, 求下一个词的是什么, 而这个词是来自于某已知的词典, 而这词典的每个单词的出现概率是不一样的 (概率之和为 1) 这样的概率分布.
是不是感觉, 用自然语言来描述这样个过程还是蛮绕的, 真的不如这个 条件概率描述更直观 \(P(x^{(t+1)} | x^1, x^2 ... x^t)\).
如果能搞定这 \(x^{(t+1)}\) 的概率分布, 这就是 Language Model. RNN 就是为这样的场景提出了一中解决方案.
You can also think of a Language Model as a system that assign probability to a piece of text.
For example, if we have some text \(x^1, x^2...x^t\), then the probability of this text (according to the Language Model) is :
\(P(x^1, x^2, x^3 ...x^T) = P(x^1) P(x^2|x^1) P(x^3|x^2, x^1)...P(x^T|x^{(T-1)}, x^{(T-2)}...x^2, x^1)\)
\(=\prod\limits_{(t=1)} ^T P(x^t|x^{(t-1)}...x^2, x^1)\)
this is what our LM provides. And We use Language Models every day. 比如我们用的输入法提示, 搜索引擎提示等这样的自动补齐操作.
N-Gram LM
引入
在深度学习, RNN 出现以前呢, 比较常见的有这样一种称为 N-Gram 的语言模型. 举栗说明, 这里还是以上面的:
the students opened their __
Definition: A n-gram is a chunk of n consecutive (连续不断的) words.
- uni-grams: "the", "students", "open", "their"
- bi-grams: "the students", "students open", "open their"
- tri-grams: "the students open", "students open their"
- 4-grams: "the students opened their"
Idea: Collect statistics about how frequent different n-grams are, and use these to predict next word.
就是通过这种 n-gram 来做一个频率统计呗, 频率越高, 则出现的概率越大呀, 就预测下一个词了呀. (其实不是这样的, 嗯还是举个栗子来说明下吧.)
过程 n-gram
First we make a simplifying assumption (简单版本的假设): \(x^{(t+1)}\) depends on the preceding n-1 words.
先做这样个数学上的假设, (真实中不一定存在的哈, 这里是为了演示 n-gram):
\(P(x^{(t+1)}|x^t, x^{(t-1)}...x^1) = P(x^{(t+1)}|x^t, ..x^{(t-n+2)})\)
表示要预测第 t+1 个单词, 并不从第一个单词开始算起, 而是从 后面往前看 n-1 个单词. (离它最近的几个来看)
条件概率: P(B|A) = P(AB) / P(A) => P(B|A) P(A) = P(AB)
\(=\frac {P(x^{(t+1)}, x^t, x^{(t-1)}, ...x^{(t-n+2)})} {P(x^t, x^t, x^{(t-1)}, ...x^{(t-n+2)}}\)
- 分子 \(P(x^{(t+1)}, x^t, x^{(t-1)}, ...x^{(t-n+2)})\) 是一个联合概率, 表示 prob of a n-gram
- 分母\(P(x^t, x^t, x^{(t-1)}, ...x^{(t-n+2)})\) 表示一个边缘概率, 即 prob of (n-1) gram
似乎说为是边缘概率, 好像也不太妥哦, 待定, 先这样, 后面查下资料再说吧. 这样就求解出了, next word 的所有出现词的概率, 即往后看 n-1 个词的话, 假设这里是 要往后看最近的 3个, 则 4-gram 与 3-gram 的所有可能相除即可得到概率.
简化思想: 将这一个复杂的序列概率问题, 在特定假设上, 转为一个相对容易求解问题, 关键在于像胡适先生所谈名言, 我也一直牢记于心的: 大胆假设, 小心求证.
于是这样一来, 就转为了 P(next) = P(n-gram) / P((n-1)-gram)
然后再接着来考虑, 如何求 n-gram 和 (n-1) - gram 即可. (By counting them in some large corpus 语库 of text
\(=\frac{x^{(t+1)}, x^t, x^{(t-1)}, ...x^{(t-n+2)}} {x^t, x^t, x^{(t-1)}, ...x^{(t-n+2)}}\)
栗子 n-gram
Suppose we are learning a 4-gram Language Model.
"as the proctor started the clock, the **students opened their __**"
要预测下一个单词是啥, 理论应该也要看前面部分, 但现在呢, 我们不看, 假设 每个单词只是取决于 它前面的 n-1 个.
这里假设是看 4-gram, 即看其前面的 3个单词, 也就是只看 "students opened their" 这3个单词. 而根据上面的简化公式:
\(P(w|students\ opened \ their) = \frac {count(students\ opened \ their \ w)} {count(students\ opened\ their )}\)
For example, that is in the corpus (语料库中):
- 分母: "students opened their" 出现了 1000 次
- 分子: "students opened their books 出现了 400 次 => P(books | students opened their) = 0.4
- 分子: "students opened their exams 出现了 100 次 => P(books | students opened their) = 0.1
于是我们用 n-gram 得到此处概率最大应该为 books, 但从整个语句意思来看, 显然 exams 更加符合题意.
结论: n-gram 来作为 Language Model 显示是不能的哦, 至少无法结合上下文来理解题意, 但还是有可取之处.
基于窗口的 LM
还是那个老的问题: How to build a neural Language Model?
Recall the Language Modeling task:
Input: sequence of words : \(x^1, x^2, ... x^t\)
output: prob dist of the next word \(P(x^{(t+1)} | x^t, x^{(t-1)}, ...x^2, x^1)\) 上标表示状态哈.
How about a window-based neural model ?
We saw this applied to Named Entity Recognition in Lecture 3:
就假设输入是这样一组词: "museums in Paris are amazing. 然后呢, 对于每个词都给它变成向量, 作为输入层, 然后给它 乘一个权值矩阵 W 在构造一个隐含层... 完全跟神经网络一样的做法.
还是以之前的 "the students opened their __" 为例,
首先要做的呢, 就是将每个词进行 OneHot 编码为向量, \(x^1, x^2, x^3, x^4\) 不是次方哈, 就是几个向量, 然后再 embedding.
embedding.
先不细讲, 大致理解为, 将单词通过某种形式, 转为一些低维向量, 而且这些向量有保持了这些词的一些相关特性, 挺神奇的东西, 后面单独来补充, 先暂时理解, 跟 onehot 编码是不同的东西哦,有种说法是 万物皆 embedding.
然后, 刚也说了, concatenated word embeddings 为:
\(e = \{e^1, e^2, e^3, e^4\}\) 即将原来很多维的 onehot 编码, 给变为低纬度的向量表示, 有点类似于 "降维" 的字面意思. 但这可能不是1 ->1 对应的.总之就将 这个整个看作一个 向量 e, 这就可作为, 咱神经网络的 输入层向量.
再然后, 根据神经网络的套路, 构造隐含层呀. (hidden layer)
\(h = f(We + b1)\) 真的不想再解释, 隐含层, 神经元计算的过程, 加权求和这样的基础概念了.
最后就是一个 softmax 的 输出层
\(\hat y = softmax( Uh + b_2) \in R^v\)
这就是 这种 fixed window 的 语言模型, 结合神经网络. 当然 应用不仅仅于此, 比如时序类的, 如股票价格, 销量预测啥的, 不都可以这样子干嘛, 懂这种套路, 再来看很多问题, 就豁然开朗.
n-gram VS fixed window
主要理解这种固定窗口的相对于 n-gram 来说, 有2个主要优势:
- No sparsity (稀疏) problem (分子, 分母会出现为 0 的情况)
- Don‘t need to store all observed n-gram (也不同像 n-gram 那样将 gram给作为 key 在存储起来)
它就相对优雅, 直接将 onehot 的词给进行 embedding, 然后只要存储权值矩阵 W 和 输出层的 U 及其 bias 即可.
- fixed window is to small 不能太大, 看太广的单词, 这样 W 就会很大了.
- 同样单词, 出现在不同位置, 可能没有很好的对比性.
总之呢, 这种滑动窗口的特点是, 窗口是要固定, 这样, 其实一想就明白, 不能灵活改变, 这必定造出来 人工智障 的哦
So, we need a neural architecture (结构设计) that can process any length input.
语言模型就先到这里吧, 然后接下来就正式来整整 递归神经网络 RNN了.
递归神经网络 - 语言模型






 京公网安备 11010802041100号
京公网安备 11010802041100号