(点击上方的蓝色文字,可快速关注我们)
如今,我们去任何一个地方都要先问问有没有Wi-Fi,网络已经明显影响到我们的生活。
互联网生下来就是为了服务海量用户,在这个时代,几乎没有哪个应用再为单机而生。每个公司的每个产品将要面临的都是不可预知的用户海量请求。显然这个靠分布式程序来解决,比靠单机靠谱得多。然而不幸的是,如果一开始你的架构设计不可扩展,有再多的机器,有再多的云解决方案,对你来说至多是将单机程序跑在了一个虚拟的单机上。下面就让我们回到WOT2016 互联网运维与开发者大会现场,跟随滴滴出行首席架构师一起了解,分布时代架构设计和程序开发面临着哪些新挑战,以及滴滴出行的应对思路。

李令辉,滴滴出行首席架构师,于2014年中加入滴滴,经历了滴滴高速成长的阶段,见证了滴滴从一个打车软件变成一个出行平台。移动互联网资深从业者,对移动互联网技术发展趋势以及技术团队的组建有独道见解。他具有多年互联网架构的设计经验,擅长高性能高并发高可用的架构设计工作,主导了滴滴打车技术迭代中的核心服务架构升级。
分布式时代的困境
为单机而生的应用将不复存在
很少有一个应用能准确预测自己的用户量有多大,因此,一开始就为上亿用户去设计一个极为复杂的分布式架构,几乎是不可能的。因为这不仅会带来极高的成本,还会牺牲整个系统的灵活度。并不是每个公司都像谷歌一样,在创业初期就有面对世界上所有数据的雄心壮志,来开发一个分布式文件系统。大多数公司一定是从几台服务器起家,在用户不断增长,并发请求增加,业务越来越复杂的过程中,百临不得已将程序从单机搬到多台机器。把单个进程拆成多个服务的问题。
分布式开发工具的缺乏
每个人的工作量平白无故一个互联网的多个节点组成的,通过网络耦合的一个分布式环境。平白无故的被这种分布式带来的必然复杂性提高了。但是,真正的分布式开发工具还远未成熟。 程序员可以使用的工具还是古老的VI,四十年前的Emacs和十几年前的Eclipse等单机开发工具,服务之间的依赖关系完全无法管理,日志格式和日志内容无法保证一致和可追溯。上线,扩容,降级等运维工作和规范没有被很好的设计。 任何一次问题或者开发,都需要多人协作,效率极为低下。
重造车轮的解决方案
我们希望有更好的解决方案。看起来,业界解决方案百花争鸣。但实际上,大部分都是基于开源的RPC方案,比较成型的几个方案包括Erlang OTP, Scala Akka等。公司内通过各种定制的方案去耦合,去互相管理关系,互相依赖,把一个事工作起来。大一点的公司会强制的推行运维规范。而每个公司或者社区都对这种分布式环境用自己的理解。 这带来的后果是,大家都在开源社区的基础上重复造同样的东西,这个是成本很高的事情。
再者,很多解决方案都依赖于特定的业务场景来制定。比如通讯软件,对实时性要求很高,对可用性要求非常高,然而电商并不那么关心一个请求能不能快速返回,而是强调数据的一致性。所以每个业务特点决定了有不同的解决方案,而且很少有为分布式而生的方案,都是从单机方案演化或者渐变来的,这些问题都会让每一个在从中开发的人不得不知道全貌,对研发效率来讲是个巨大的伤害。分布式也确实个足够复杂的领域,很难有一揽子通用解决方案。
那么,在设计分布式系统架构时,应该考虑哪些方面?
分布式架构设计基本要素
容错
在分布式环境里,错误无处不在,并且无时无刻不在发生。而且,错误不只是机器故障,当几百人投入研发工作的时候,一定会有人犯错,而且每个人都会犯错,会常态的犯错。因此,研发团队不应该只想着如何避免错误的发生,而是如何在小错误下,不影响业务,保持服务健康运营。而一但不加考虑的对架构每个模块进行降级,势必带来一场巨大的灾难。
数据格式
数据格式实际面临的困境和依赖管理是一样的,因为每个人只负责单独的模块,而不会去关心整个业务用什么样的数据格式通信。究竟代码中到底多少是用来Verify Data的?又有多少是用来Pack/Unpack Data的?如果不统一就会陷入泥潭,工作效率低到无法接受,日志收集和监控也几乎没法实现。
路由层
关于路由层的解决方案没有高下之分,只要能解业务中的问题,降低运维成本和开发成本,就是好的方案。
但是,一定要尽量避免同时存在多种解决方案。函数调用是路由,反射是路由,URL是路由,RPC的IP+Port+Function也是路由。虽然说,并不是所有业务都能用统一的方法来路由的。路由的灵活性和规范性决定了运维难度,盲目追求灵活度平白无故的又把运维提的工作高一个量级。架构本质是控制复杂度,主要方法就是分而治之,解耦,耦合从本质上来说就是路由。
服务
为了满足用户新的要求,追上市场新的步伐,每个互联网公司的研发团队都不曾停下脚步,保证服务不断进化和升级。这同时也带来了许多问题:
如何稳定高效的迭代?
依赖刚迭代的服务的旧服务怎么办?
我想给某个服务/模块做AB Test怎么办?
多个模块可以同时做AB Test么?
如果不能,研发变成串行上线真的好么?
看待这些问题一定要从全局出发,而最重要的是接口的统一,形成一致的标准,让大家在一条共同的准绳上。
监控
现在大家所做的监控,基本都是在监控机器的状态。其实在几百台机器这样的较小规模下,这样做的意义并不大。真正应该监控的,应该是程序。而严控程序的状态,只能依赖日志。
因此,每个架构师都要考虑,如何设计可以监控服务的日志系统,要提供可监控的接口。是每个架构师要考虑你的服务是怎么被监控的,你要提供可监控的接口。至于采集间隔。一般来说规模越大,采集粒度越低,规模越小,采集粒度越高。
另外,监控的信息是Pull or Push?监控的结果全部需要人来处理么?日志是否可以用来作为系统之间交互的数据?这些问题都需要大家根据自己的业务场景不断探索。
你的运维方案完美吗?
每个公司的运维团队都在考虑这个问题。你的目的是为了降低你的成本,提高你的效率。请合理的计算你的成本和效率,就是你要把人算进去,而不是就算机器。大家可以通过以下几个维度来评估:
资源利用率如何?对大部分团队来说,研发的人力成本要远远高于机器成本,你要首先考虑的是你的人都并发起来了,而不是你的CPU都被吃掉了
解决方案是否简单?这对应着人才招聘的门槛。对于新人来说,总要让他快速的上手做一个项目,验证自己的能力,所以解决方案一定要相对简单。怎么扩容,怎么缩容,都应该有成型的一整套方案
开发测试上线流程是否需要人工介入?
小流量测试的支持如何?
回滚、限流、断流方案是否统一提供等等问题 ?
滴滴出行的分布式设构设计思路
Linux之所以强大,是因为每一个模块都只负责最简单的事情,面对输入和输出,而输入和输出的格式是确定的。分布式架构设计的思路也应如此,同样的规则,同样的用法组合在一起是可以发挥巨大作用的。
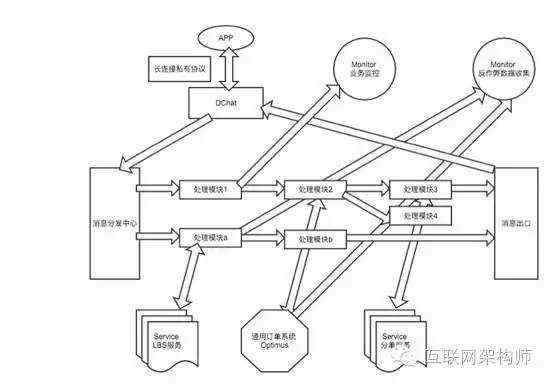
这样的架构设计带来的一个巨大好处是,信息流在进来的时候进入信息分发,信息分发把它分到合适的管道,那个管道处理完再放给下一个管道。每个管道都只做输入和输出的事情,实现高可用、高吞吐。这种方案很多云服务商都会提供。这样做的好处时是,我们只需要管理消息队列,可以在任意一个节点把流量复制走。在任何一个环节中可以拿到它所有的数据,不再依赖日志,只依赖输入、输出。而输入、输出是存在硬盘上的,数据不会丢失。
另一个优点是进程是异步传输的。同步模型一个很明显的缺点是在所有的层次中,一个进程在执行某个请求的时候如果需要一段时间才能返回信息,那么这个进程将会一直等待下去,直到收到返回信息才继续执行下去。在流量很大的时候,做一个重试可能某一个环节就会面临崩溃了,某个环节的连接数被打满。
而在这个方案中,连接就只有两三处,不需要等待数据回报,只需要确认收据接收,而且不需要逐条验证。成本很低,性能很高。
但这个架构设计显然不能解决所有的问题。比如用MySql作为存储等必须同步的服务时,需要给有状态的服务提供一个抽象层Seivice。上面的服务可以请求它。可以理解为在Linux中敲一个命令要读一个文件,那个文件是有状态的,是存在那里的,而这些模块是没有状态的。
这个设计要解决的问题不是简简单单的机器运维问题,而是人在研发过程中,如何避免我面临复杂环境中的险,解决由于粗糙的架构设计带来的效率低下,不可控,不稳定,手足无措的状态。
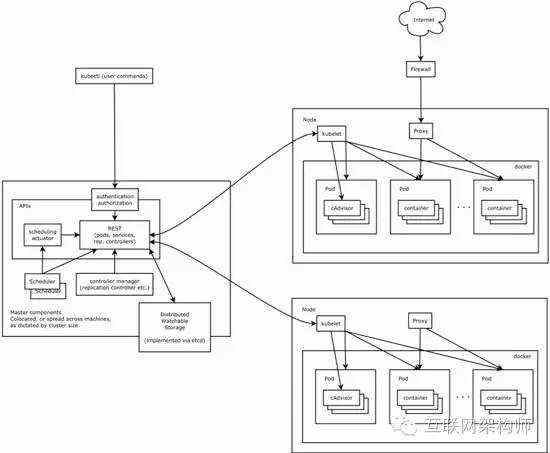
滴滴选择了Docker+Kubernetes作为分布集群管理解决方案,它的好处是可以直接提供资源管理,资源隔离,部署,升级,路由等等需求。但是,只有Kubernetes是不够的,Kubernetes只能管理那些无状态的事务。并不是所有的事情都可以完全抽象成无状态的,有状态的部分应该如何实现扩容,都要依据具体的业务场景,这是很难的设计。
最后要说的是,没有完美的方案,如果你自己要开发这个事情,建议大家最好用一种方案,不要每一个用一种。但是没办法,你就是不同的好几波人开发的,并且场景不一样,很有可能还是那个样子,如何解决有状态事务的快速扩容和运维管理,现在还没有最终的结论。希望和业务同仁共同探讨。
欢迎关注“互联网架构师”,我们分享最有价值的互联网技术干货文章,助力您成为有思想的全栈架构师,只聊架构,不聊其他!打造最有价值的架构师圈子和社区。
长按下方的二维码可以快速关注我们

如想加群讨论学习,请点击右下角的“加群学习”菜单入群。






 京公网安备 11010802041100号
京公网安备 11010802041100号