[1] Wang S , Clark R , Wen H , et al. DeepVO: Towards end-to-end visual odometry with deep Recurrent Convolutional Neural Networks[J]. IEEE, 2017.
针对以往的使用深度学习解决视觉里程计中,只在帧间预测pose,没有充分利用连续帧的问题,本文使用CNN+RCNN(LSTM)实现了充分利用序列帧的信息,实现了很好的效果。
- 1、整体结构
- 2、CNN部分
- 3、RNN部分
- 4、损失函数和优化
- 5、实验效果
1、整体结构
整体结构如图所示,在上方作者给出了传统方法的视觉里程计的流程,在下方是本文中的流程。可以看出输入是序列图,通过CNN网络,再通过RNN网络,最终预测出pose。而RNN系列可以看出有数据从上帧流向了下一帧,这也体现了本设计利用了上下文信息。

2、CNN部分
CNN结构图如下:

CNN的具体结构如下表所示:

在输入方面:
首先是两个RGB图像经过了预处理,将RGB图像减去训练集中RGB值的均值,然后将两个连续帧cat在一起,形成一个6通道的tensor,然后再输入进CNN网络,最终是在Conv6输出(后面属于RNN部分了)。
在激活函数上:
激活函数是除了Conv6外,每层卷积层后都是ReLU,所以总共有17层(9个卷积层和8个激活层)。
为什么要有CNN?
CNN部分的目的是为了产生一个有效的特征,这个有效特征会被送进后面的RNN进行序列学习,最终产生pose。
同时作者也解释了为什么输送进入RGB图,而不是比如光流图或者深度图等其他类型。首先因为使用RGB图像来训练,使得网络可以学习一种有效的特征表示,并降低维度。而且学习到的有效特征表示不仅将图像压缩成了紧凑的描述,也促进了连续的RNN训练过程。
3、RNN部分
RNN部分使用了LSTM,其结构图如下:

这是LSTM单元,实际上和最传统的LSTM一样的,可以看看这个理解 LSTM 网络。
实际上从上上上图可以看出,RNN使用了2个LSTM单元,并且有1000种隐藏状态。
4、损失函数和优化
损失函数定义为gt pose和估计的pose之间的欧氏距离:
pose=(pk,φk)pose=(p_k,φ_k)pose=(pk,φk)
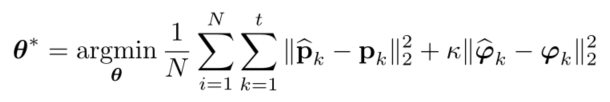
- k:权重因子,决定p和φ谁更重要
- φ:是欧拉角,不是四元数,因为四元数收到额外的单位约束,妨碍优化。而且在实验中发现四元数会降低方向估计的精度。
5、实验效果


5.3、测试结果










 京公网安备 11010802041100号
京公网安备 11010802041100号