本文翻译自 dask-tutorial 项目
这是使用 dask
并行化现有代码库或构建复杂系统的一种简单方法。这也将有助于我们对后面的部分进行理解。
在这里,我们将讨论 dask 背后的一些概念,以及代码的延迟执行。如果您渴望继续学习本教程,则无需阅读这些材料,但它可能有助于理解 dask 背后的概念,这些内容如何与您可能已经在使用的技术相适应,以及如何理解可能出问题的事情。
序幕
作为 Python 程序员,您可能已经执行了某些 技巧 来启用大于内存数据集的计算、并行执行或延迟/后台执行。也许用这种措辞,我们的意思不清楚,但一些例子应该会使事情更清楚。Dask 的重点是让简单的事情变得简单,让复杂的事情成为可能!
在详细的介绍之外,我们可以总结 Dask 的基础知识如下:
所有这些都可以让您充分利用计算资源,但以一种非常熟悉的方式进行编程:用于构建基本任务的 for 循环、Python 迭代器以及分别用于多维数据和表格数据的 NumPy (数组) 和 Pandas (数据框)。
本笔记本的其余部分将带您了解这些编程范式中的第一个。这比一些用户想要的要详细,他们可以跳到迭代器、数组和数据框部分;但是会有一些数据处理任务不容易适应这些抽象,需要回退到这里的方法。
我们在笔记本的末尾包含了一些示例,表明 Dask 的构建方式背后的想法实际上并不那么新颖,并且有经验的程序员之前会在其他情况下遇到过部分设计。这些例子留给感兴趣的人。
Dask 是一个图执行引擎
Dask 允许您为要执行的计算构建一个处方 (recipe)。这听起来可能很奇怪,但一个简单的示例将证明您可以在使用非常普通的 Python 函数和 for 循环进行编程时实现这一点。我们在之前的笔记本已看到这一点。
from dask import delayed
@delayed
def inc(x):
return x + 1
@delayed
def add(x, y):
return x + y
在这里,我们使用了延迟注释来表明我们希望这些函数延迟运行 —— 保存输入集并仅在需要时执行。 dask.delayed
也是一个可以做到这一点的函数,没有注释,保持原始函数不变,例如
delayed_inc = delayed(inc)
下面代码看起来像是普通代码
x = inc(15)
y = inc(30)
total = add(x, y)
x
、y
和 total
都是延迟对象。它们包含如何进行计算的处方。
调用延迟函数会创建一个可以交互检查的延迟对象 (x
, y
, total
)。制作这些对象在某种程度上等同于构造诸如 lambda
或函数包装器 (见下文)。每个都有一个描述任务图的简单字典,一个关于如何执行计算的完整规范。
我们可以将对象 total
对应的计算链可视化如下;圆圈是函数,矩形是数据/结果。
total.visualize()
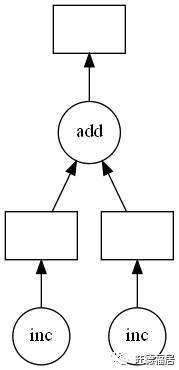
但到目前为止,还没有实际执行任何函数。这演示了 Dask 的图创建部分 (在本例中为 delayed()
) 和 Dask 的图执行部分之间的划分。
要运行可视化中的 “图” 并实际获得结果,请执行以下操作:
# 执行所有任务
total.compute()
47
为什么要关心这个?
通过在执行任何操作之前构建我们想要执行的计算规范,我们可以将规范传递给 执行引擎 进行评估。在 Dask 中,该执行引擎可以在集群的许多节点上运行,因此您可以访问所有机器上的全部 CPU 内核和内存。Dask 将智能地执行您的计算,以尽量减少内存中保存的数据量,同时并行化构成图形的任务。请注意,在下面的动画图中,四个工作负载 (worker) 正在处理 (简单) 图形,执行首先垂直向上进行分支,以便在移动到新分支之前可以删除中间结果。
使用 delayed
和普通的 pythonic 循环代码,可以构建非常复杂的图形并将其传递给 Dask 执行。查看 simulated complex ETL 工作流的一个很好的例子。
练习
我们将 delay
应用于真实的数据处理任务,尽管是一个简单的任务。
考虑使用 pd.read_csv
读取三个 CSV 文件,然后测量它们的总长度。我们将考虑如何使用普通 Python 代码执行此操作,然后使用延迟为该过程构建一个图,最后使用 Dask 执行此图,以获得超过 2 的加速因子 (只有三个输入要并行化)。
%run prep.py -d accounts
import pandas as pd
from pathlib import Path
filenames = [Path("data", f"accounts.{i}.csv") for i in [0, 1, 2]]
filenames
常规,串行版本
%%time
a = pd.read_csv(filenames[0])
b = pd.read_csv(filenames[1])
c = pd.read_csv(filenames[2])
na = len(a)
nb = len(b)
nc = len(c)
total = sum([na, nb, nc])
print(total)
Wall time: 449 ms
3000000
接下来,使用循环重复此操作,而不是写出所有变量。
csvs = [delayed(pd.read_csv)(f) for f in filenames]
ns = [delayed(len)(c) for c in csvs]
total = delayed(sum)(ns)
%time total.compute()
Wall time: 467 ms
3000000
注意
延迟对象支持各种操作:
x2 = x + 1
如果 x
是延迟结果 (如上面的 sum
),那么 x2
也是。支持的操作包括:
基本上任何可以被表述为 lambda 表达式的操作。
不支持 的操作包括:
变异
setter 方法
迭代 (for)
bool (谓词)
附录:更多细节和示例
以下示例表明,在处理大数据时,Dask 所做的事情与正常的 Python 编程并没有太大区别。这些示例仅供专家使用,典型用户可以继续使用教程中的下一个笔记本。
示例 1:简单单词计数
本目录包含一个名为 README.md
的文件。您将如何计算该文件中的单词数?
最简单的方法是将所有数据加载到内存中,在空白处拆分并计算结果数。这里我们使用正则表达式来拆分单词。
import re
splitter = re.compile("\w+")
with open("README.md", "r") as f:
data = f.read()
result = len(splitter.findall(data))
result
747
这种方法的问题在于它不能扩展 —— 如果文件非常大,它和生成的单词列表可能会填满内存。我们可以很容易地避免这种情况,因为我们只需要一个简单的总和,并且每一行都完全独立于其他行。现在我们评估每条数据并立即再次释放空间,因此我们可以对任意大的文件执行此操作。请注意,时间效率 (time-efficientcy) 和内存 (memory) 占用之间通常存在权衡:下面的代码使用很少的内存,但对于未填充大量内存的文件可能会更慢。通常,人们希望块足够小,不会给内存带来压力,但足够大以有效使用 CPU。
result = 0
with open("README.md", "r") as f:
for line in f:
result += len(splitter.findall(line))
result
747
示例 2:后台执行
有许多任务需要一段时间才能完成,但实际上并不需要太多的 CPU,例如任何需要通过网络进行通信或来自用户输入的任务。在典型的顺序编程中,需要在进程完成时停止执行,然后继续执行。这对用户体验来说是可怕的 (想象一下缓慢的进度条会锁定应用程序并且无法取消),并且浪费时间 (CPU 可能在此期间一直在做有用的工作)。
例如,我们可以按如下方式启动进程并获取它们的输出:
import subprocess
p = subprocess.Popen(command, stdout=subprocess.PIPE)
p.returncode
任务在一个单独的进程中运行,返回码将保持 None
直到它完成,随即变为 0
。要返回结果,我们需要 out = p.communicate()[0]
(如果该过程未完成,这会阻塞)。
lazy_url = "http://www.cma.gov.cn/"
import threading
import queue
import urllib
def get_webdata(url, q):
u = urllib.request.urlopen(url)
q.put(u.read())
q = queue.Queue()
t = threading.Thread(target=get_webdata, args=(lazy_url, q))
t.start()
将结果取回此线程。如果工作线程没有完成,将等待。
result = q.get()
考虑:如果 get_webdata
函数中出现异常,您会看到什么?您可以取消注释上面的加注线,然后重新执行两个单元格。怎么了?有什么方法可以调试执行以找到错误的根本原因吗?
import threading
import queue
import urllib
def get_webdata(url, q):
u = urllib.request.urlopen(url)
raise ValueError
q.put(u.read())
q = queue.Queue()
t = threading.Thread(target=get_webdata, args=(lazy_url, q))
t.start()
result = q.get()
练习3:延迟执行
Python 中有很多方法可以指定要执行的计算,并 稍后 运行。
有时我们使用字符串推迟计算
def add(x, y):
return x + y
x = 15
y = 30
z = "add(x, y)"
eval(z)
45
我们可以使用 lambda 或其他“闭包”
x = 15
y = 30
z = lambda: add(x, y)
z()
45
functools.partial
中发生了非常相似的事情
import functools
z = functools.partial(add, x, y)
z()
45
Python 生成器默认延迟执行。许多 Python 函数都期望这样的可迭代对象。
def gen():
res = x
yield res
res += y
yield res
g = gen()
运行一次:我们得到一个值并在生成器中停止执行。再次运行,执行完成
next(g)
15
next(g)
45
Dask 图
任何 Dask 对象,例如上面的 total
,都有一个属性来描述产生该结果所需的计算。确实,这正是我们一直在谈论的图,可以可视化。我们看到它是一个简单的字典,其中键是唯一的任务标识符,值是计算的函数和输入。
delayed
是创建 Dask 图的一种方便的机制,但喜欢冒险的人可能希望利用直接构建图字典所提供的全部灵活性。详细信息可以在这里找到。
total.dask
# https://stackoverflow.com/questions/3229419/how-to-pretty-print-nested-dictionaries
def pretty(d, indent=0):
for key, value in d.items():
print('\t' * indent + str(key))
if isinstance(value, dict):
pretty(value, indent+1)
else:
print('\t' * (indent+1) + str(value))
pretty(dict(total.dask))
sum-be86c391-f402-4066-adbe-410fa740bca4
(, ['len-5bbbceb2-e768-4486-95a6-5dbc11b83cb4', 'len-acc9f19e-e36c-4923-9e8b-6c3def2a8246', 'len-3cb9cff5-8e5e-4253-990d-1ef3204d7210'])
read_csv-1f46d63f-eb2f-4f94-b4e7-b78c341b7a35
(, WindowsPath('data/accounts.0.csv'))
len-5bbbceb2-e768-4486-95a6-5dbc11b83cb4
(, 'read_csv-1f46d63f-eb2f-4f94-b4e7-b78c341b7a35')
read_csv-1f7bbab6-548d-41db-af2e-f874165b543b
(, WindowsPath('data/accounts.1.csv'))
len-acc9f19e-e36c-4923-9e8b-6c3def2a8246
(, 'read_csv-1f7bbab6-548d-41db-af2e-f874165b543b')
read_csv-7732e495-f96e-4c17-b9a1-c42de8fdf962
(, WindowsPath('data/accounts.2.csv'))
len-3cb9cff5-8e5e-4253-990d-1ef3204d7210
(, 'read_csv-7732e495-f96e-4c17-b9a1-c42de8fdf962')
参考
dask-tutorial
https://github.com/dask/dask-tutorial
Dask 教程
相关文章
使用 Dask 并行抽取站点数据


![Python3爬虫入门:pyspider的基本使用[python爬虫入门]](https://img1.php1.cn/3cdc5/324f/339/9d0ec9721f26646a.jpeg)




 京公网安备 11010802041100号
京公网安备 11010802041100号