4
Part
Spark Streaming 基于HDFS的实时计算开发
Ⅰ
Socket和HDFS文件的原理
Ⅱ
关于集群同步的一些注意事项
Ⅲ
编写本地源数据并创建HDFS文件目录
Ⅳ
编写基于HDFS源端的WordCount实时处理程序
Ⅴ
上传本地文件并展示实时结果
Socket和HDFS文件:
Socket:
第二章的wordcount例子已经演示过了。
StreamingContext.socketTextStream ()
HDFS文件:
基于HDFS文件的实时计算,其实就是监控一个HDFS目录,只要其中有新文件出现,就实时处理。相当于处理实时的文件流。
streamingContext.fileStream<KeyClass, ValueClass, InputFormatClass>(dataDirectory)streamingContext.textFileStream[KeyClass, ValueClass, InputFormatClass](dataDirecto
streamingContext.fileStream<KeyClass, ValueClass, InputFormatClass>(dataDirectory)
streamingContext.textFileStream[KeyClass, ValueClass, InputFormatClass](dataDirecto
Spark Streaming会监视指定的HDFS目录,并且处理出现在目录中的文件。要注意的是,所有放入HDFS目录中的文件,都必须有相同的格式;必须使用移动或者重命名的方式,将文件移入目录;一旦处理之后,文件的内容即使改变,也不会再处理了;基于HDFS文件的数据源是没有Receiver的,因此不会占用一个cpu core,所以可以写成local[1]。
关于集群同步的时间问题:
修改主机时间,使源数据节点时间必须与计算节点时间保持同步:
# sudo date -s 2020-01-14# sudo date -s 08:00:00
# sudo date -s 2020-01-14
# sudo date -s 08:00:00
修改hadoop配置文件:
# sudo vi hadoop-env.sh......... export HADOOP_OPTS="$HADOOP_OPTS-Duser.timezOne=GMT+08".........
# sudo vi hadoop-env.sh
.........
export HADOOP_OPTS="$HADOOP_OPTS-Duser.timezOne=GMT+08"
# sudo vi yarn-env.sh......... YARN_OPTS="$YARN_OPTS -Duser.timezOne=GMT+08".........
# sudo vi yarn-env.sh
YARN_OPTS="$YARN_OPTS -Duser.timezOne=GMT+08"
# sudo vi hbase-env.sh.........export TZ="Asia/Shanghai"........
# sudo vi hbase-env.sh
export TZ="Asia/Shanghai"
........
创建本地源数据并创建HDFS文件目录
本地创建源数据文件:
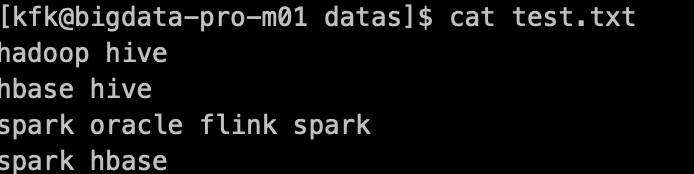
# vi test.txthadoop hivehbase hivespark oracle flink sparkspark hbase
# vi test.txt
hadoop hive
hbase hive
spark oracle flink spark
spark hbase
查看文件:
创建输入流数据源目录:
[kfk@bigdata-pro-m01 hadoop-2.7.0]$ bin/hdfs dfs -mkdir -p /user/spark/datas/sparkstreaming
//Javaimport org.apache.spark.SparkConf;import org.apache.spark.streaming.Durations;import org.apache.spark.streaming.api.java.JavaDStream;import org.apache.spark.streaming.api.java.JavaPairDStream;import org.apache.spark.streaming.api.java.JavaStreamingContext;import scala.Tuple2;import java.util.Arrays;public class HDFSWordCountJava { public static void main(String[] args) throws Exception{ SparkConf cOnf= new SparkConf().setMaster("local[1]").setAppName("HDFSworkWordCount"); JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(3)); //每隔3秒处理数据 String filePath = "hdfs://bigdata-pro-m01.kfk.com:9000/user/spark/datas/sparkstreaming"; JavaDStream<String> lines = jssc.textFileStream(filePath); JavaDStream<String> words = lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator()); JavaPairDStream<String,Integer> pair = words.mapToPair(word -> new Tuple2<>(word,1)); JavaPairDStream<String,Integer> wordcount = pair.reduceByKey((x,y) -> (x + y)); wordcount.print(); jssc.start(); jssc.awaitTermination(); }}
//Java
import org.apache.spark.SparkConf;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.util.Arrays;
public class HDFSWordCountJava {
public static void main(String[] args) throws Exception{
SparkConf cOnf= new SparkConf().setMaster("local[1]").setAppName("HDFSworkWordCount");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(3)); //每隔3秒处理数据
String filePath = "hdfs://bigdata-pro-m01.kfk.com:9000/user/spark/datas/sparkstreaming";
JavaDStream<String> lines = jssc.textFileStream(filePath);
JavaDStream<String> words = lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator());
JavaPairDStream<String,Integer> pair = words.mapToPair(word -> new Tuple2<>(word,1));
JavaPairDStream<String,Integer> wordcount = pair.reduceByKey((x,y) -> (x + y));
wordcount.print();
jssc.start();
jssc.awaitTermination();
}
//Scalaimport org.apache.spark.SparkConfimport org.apache.spark.streaming.{Durations, StreamingContext}object HDFSWordCountScala { def main(args: Array[String]): Unit = { val cOnf= new SparkConf().setMaster("local[1]").setAppName("HDFSworkWordCount") val jssc = new StreamingContext(conf, Durations.seconds(3)) val filePath: String = "hdfs://bigdata-pro-m01.kfk.com:9000/user/spark/datas/sparkstreaming" //sparkstreaming目录下新增的所有文件都会被处理 val lines = jssc.textFileStream(filePath) val words = lines.flatMap(line => line.split(" ")); val pair = words.map(word => (word,1)) val wordcount = pair.reduceByKey((x , y) => x + y) wordcount.print() jssc.start() jssc.awaitTermination() }}
//Scala
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Durations, StreamingContext}
object HDFSWordCountScala {
def main(args: Array[String]): Unit = {
val cOnf= new SparkConf().setMaster("local[1]").setAppName("HDFSworkWordCount")
val jssc = new StreamingContext(conf, Durations.seconds(3))
val filePath: String = "hdfs://bigdata-pro-m01.kfk.com:9000/user/spark/datas/sparkstreaming" //sparkstreaming目录下新增的所有文件都会被处理
val lines = jssc.textFileStream(filePath)
val words = lines.flatMap(line => line.split(" "));
val pair = words.map(word => (word,1))
val wordcount = pair.reduceByKey((x , y) => x + y)
wordcount.print()
jssc.start()
jssc.awaitTermination()
启动程序
上传HDFS文件
bin/hdfs dfs -put /opt/datas/test.txt /user/spark/datas/sparkstreamingbin/hdfs dfs -copyFromLocal /opt/datas/test.txt /user/spark/datas/sparkstreaming/1.txt
bin/hdfs dfs -put /opt/datas/test.txt /user/spark/datas/sparkstreaming
bin/hdfs dfs -copyFromLocal /opt/datas/test.txt /user/spark/datas/sparkstreaming/1.txt
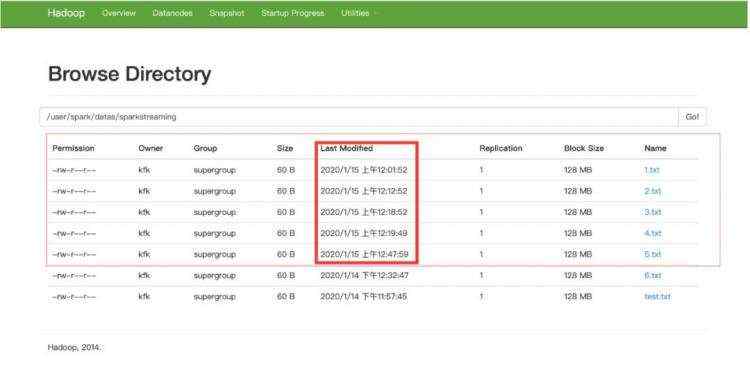
这里为什么上传了这么多文件没有执行成功呢?这是因为开始没有同步集群时间导致Last Modified异常(20200114测试的),计算节点无法实时读取数据。最后修改时间后重启namenode和datanode服务,重新上传6.txt文件才被计算节点处理。
3. 打印结果
总结一下,在实际企业中HDFS用于实时数据的传输比较少,这是因为数据落地到HDFS分布式文件系统需要一段时间,从而影响了时效性,所以分布式存储文件多用于大数据离线处理。而数据实时性处理还是要Kafka这种响应快速的中间件来映射。
微信号 : BIGDT_IN
● 扫码关注我们












 京公网安备 11010802041100号
京公网安备 11010802041100号