作者:夏至_krisyeol_582 | 来源:互联网 | 2023-08-19 16:42
备注:
Hive 版本 2.1.1
Table of Contents
- 一.Hive的实现原理
- 二Hive优化
- 2.1 选择合理的存储格式和压缩格式
- 2.2 MR Job优化
- 2.3 Join优化
- 2.3.1 MapJoin 优化
- 2.3.2 SMB Join 优化
- 2.4 数据倾斜
- 2.5 Hive的优化配置参数
一.Hive的实现原理
Hive的编译器将HQL转换成一组操作符(Operator)
操作符是Hive的最小处理单元
每个操作符代表一道HDFS操作或者MR Job 作业
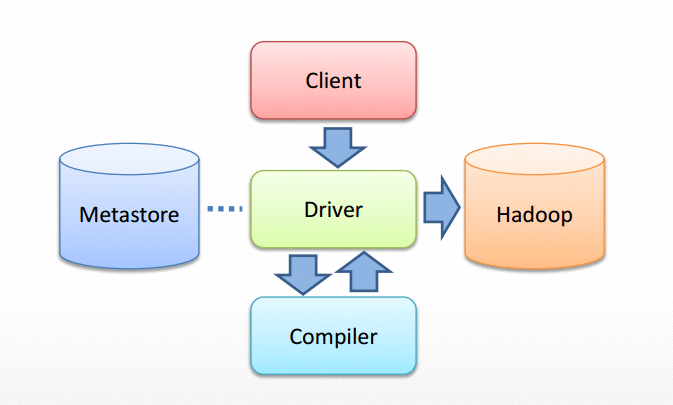
Hive的操作符
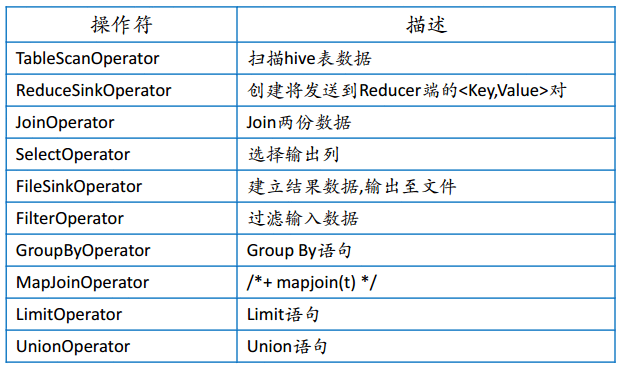
Hive编译器
Parser:
将SQL转换成抽象语法树
语法解析器:
将抽象语法树转换成查询块
逻辑计划生成器:
将查询块转换成逻辑计划
物理计划生成器:
将逻辑计划转换成物理计划
物理计划优化器:
物理计划优化策略
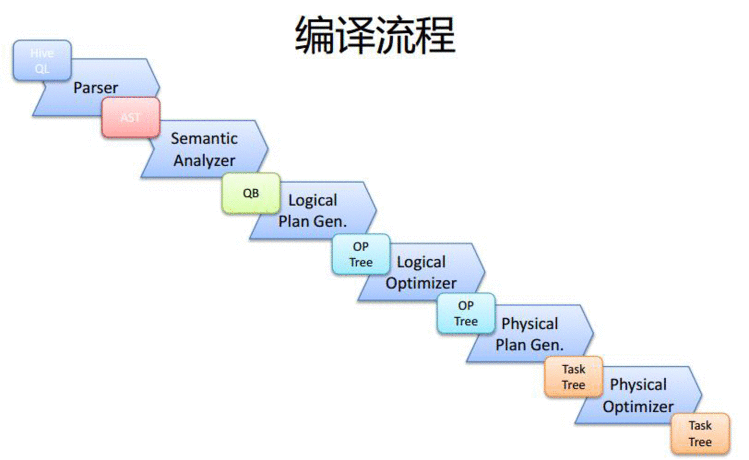
编译流程
利用Explain查看执行计划
语法:
:EXPLAIN [EXTENDED] query
输出:
- 查询语句的抽象语法树(AST)
- 执行计划丌同阶段间的依赖关系
- 每个阶段的描述
二Hive优化
优化的目的:提升查询性能,快速产出结果
Hive的优化思路:
- 编译器优化器优化:采用合理的优化策略,生成高效的物理计划
- MapReduce执行层优化:通过MR参数优化,提升Job运行效率
- HDFS存储层优化:采用合理的存储格式和合理的Schema设计,降低IO瓶颈
2.1 选择合理的存储格式和压缩格式
列存储,高压缩比,列剪枝,过滤无用字段IO
- Orc
- Parquet
压缩格式选择:snappy
2.2 MR Job优化
并行执行
Hive产生的MR Job默认是顺序执行的,如果Job之间无依赖可以并行执行
set hive.exec.parallel=true;
本地执行
虽然Hive能够利用MR处理大规模数据,但某些场景下处理的数据量非常小可以本地执行,不必提交集群
set hive.exec.mode.local.auto=true;
hive.exec.mode.local.auto.inputbytes.max(默认128MB)
hive.exec.mode.local.auto.input.files.max(默认4)
合并输入小文件
如果Job输入有很多小文件,造成Map数太多,影响效率
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat
合并输出小文件
set hive.merge.mapfiles=true; // map only job结束时合并小文件
set hive.merge.mapredfiles=true; // 合并reduce输出的小文件
set hive.merge.smallfiles.avgsize=256000000; //当输出文件平均大小小于该值,启动新job合并文件
set hive.merge.size.per.task=64000000; //合并之后的每个文件大小
控制Map/Reduce数
控制Map/Reduce数来控制Job执行的并行度
Num_Map_tasks= $inputsize/ max($mapred.min.split.size, min($dfs.block.size, $mapred.max.split.size))
Num_Reduce_tasks= min($hive.exec.reducers.max, $inputsize/$hive.exec.reducers.bytes.per.reducer)
JVM重用
JVM重利用可以使job长时间保留slot,直到作业结束
set mapred.job.reuse.jvm.num.tasks=10 //每个jvm运行10个task
推测执行
set hive.mapred.reduce.tasks.speculative.execution=true
set mapreduce.map.speculative=true
set mapreduce.reduce.speculative=true
一定要开启压缩
中间结果压缩,减少Job跟Job之间的IO开销
set hive.exec.compress.intermediate=true
set mapred.map.output.compression.codec=
最终结果压缩,减少存储空间
set hive.exec.compress.output=true
Set mapred.output.compression.codec=
2.3 Join优化
Hive的Join类型:
- Shuffle Join
- Broadcast Join(MapJoin)
- Sort-Merge-Bucket Join
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r4Mr5baa-1611020439271)(https://upload-images.jianshu.io/upload_images/2638478-7b767f2303382f84.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)]
2.3.1 MapJoin 优化
方式一(自动判断):
set.hive.auto.convert.join=true;
hive.mapjoin.smalltable.filesize // 默认值是25mb, 小表小于25mb自动启动mapjoin
方式二(手动显式):
select /+mapjoin(A)/ f.a,f.bfrom A t join B f on (f.a=t.a)
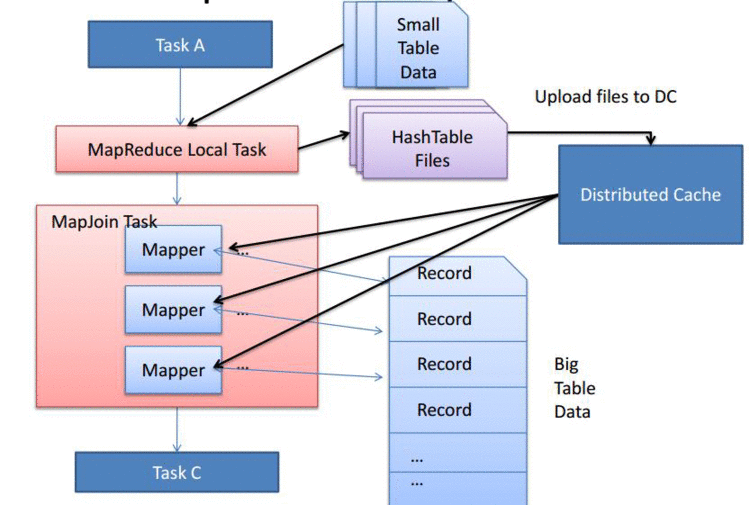
2.3.2 SMB Join 优化
使用方式:
hive.optimize.bucketmapjoin= true
和mapjoin一起工作,所有要Join的表都必须对Join key做了分桶,并且大表的桶数是小表的整数倍
由于对表设计有太多的限制,不太常用
2.4 数据倾斜
数据倾斜是指由于数据分布不均匀,个别值集中占据大部分数据量,导致某一个或者几个ReduceTask处理的数据量相对很大造成的Job运行非常慢,甚至OOM挂掉
在SQL上,一般是由于group by 或者join shuffle key丌均匀造成的
数据倾斜是业务数据问题导致的,如果从业务上下手避免是最好的
- 比如由于Null值引起的,或者某一个特殊的key造成的数据量特别大
- 先过滤掉特殊key的数据再进行处理
Hive自身的优化方案:
- 由group by 引起的数据倾斜:
hive.map.aggr=true //做map端预聚合,相当于Map端Combiner
hive.groupby.skewindata//将key的数据随机分发到Reduce端做聚合,然后再起一个Job对上一步的结果做聚合
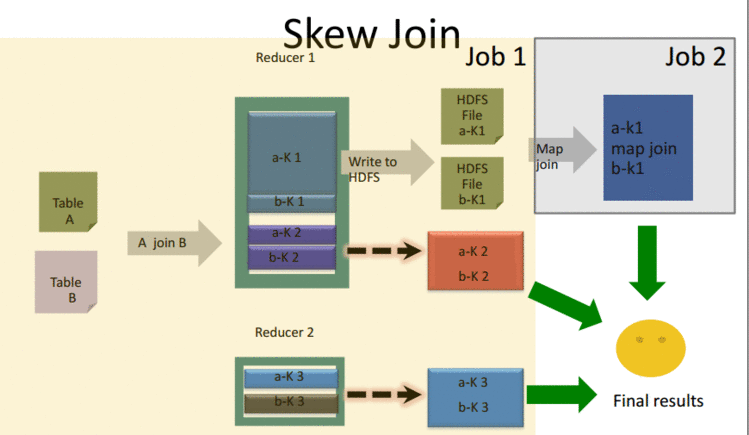
- 由Join引起的数据倾斜(Skew Join)
set hive.optimize.skewjoin= true
set hive.skewjoin.key= 100000
// 超过阈值就判断为skew key
2.5 Hive的优化配置参数
hive-site.xml中更改默认配置
在脚本中set变量
Hive的优化配置非常多,具体情况具体分析







 京公网安备 11010802041100号
京公网安备 11010802041100号