前言
大家好,我是程序员manor。作为一名大数据专业学生、爱好者,深知面试重要性,很多学生已经进入暑假模式,暑假也不能懈怠,正值金九银十的秋招
接下来我准备用30天时间,基于大数据开发岗面试中的高频面试题,以每日5题的形式,带你过一遍常见面试题及恰如其分的解答。
相信只要一路走来,日积月累,我们终会在最高处见。
以古人的话共勉:道阻且长,行则将至;行而不辍,未来可期!

本栏目大数据开发岗高频面试题主要出自大数据技术专栏的各个小专栏,由于个别笔记上传太早,排版杂乱,后面会进行原文美化、增加。
不要急着往下滑,默默想5min,看看这5道面试题你都会吗?
面试题 01、为什么要设计Segment?
面试题02、什么是AR、ISR、OSR?
面试题 03、什么是HW、LEO?
面试题04、什么是一次性语义?
面试题05、Kafka如何保证消费者消费数据不重复不丢失?


以下答案仅供参考:
文章目录
- 前言
- 面试题 01、为什么要设计Segment?
- 面试题02、什么是AR、ISR、OSR?
- 面试题 03、什么是HW、LEO?
- 面试题04、什么是一次性语义?
- 面试题05、Kafka如何保证消费者消费数据不重复不丢失?
- 总结
面试题 01、为什么要设计Segment?
•加快查询效率:将数据划分到多个小文件中,通过offset匹配可以定位某个文件,从小数据量中找到需要的数据
•提高删除性能:以Segment为单位进行删除,避免以每一条数据进行删除,影响性能
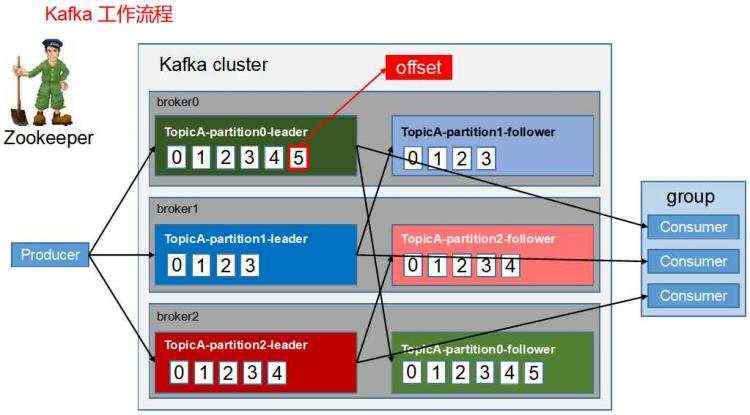
面试题02、什么是AR、ISR、OSR?
•AR:all replicas
–所有副本 = ISR + OSR
•ISR:In-sync-replicas
–表示正在同步的副本 =》 可用副本分区
–如果Leader故障,会从ISR中选举一个新的leader
•OSR:Out-sync-replicas
–表示不健康的副本 =》 不可用副本
–判断依据
#如果这个从副本在这个时间内没有与leader副本同步数据,认为这个副本是不正常的
参数设置: replica.lag.time.max.ms = 10000
面试题 03、什么是HW、LEO?
•HW:表示当前leader副本中所有Follower都已经同步的位置 + 1,高水位线
•LEO:表示当前leader副本最新的数据位置 + 1
•消费者能消费到的位置是HW:为了保证消费者消费分区数据的统一性
面试题04、什么是一次性语义?
•at-most-once:最多一次
•at-least-once:至少一次
•exactly-once:有且仅有一次
面试题05、Kafka如何保证消费者消费数据不重复不丢失?
•Kafka消费者通过Offset实现数据消费,只要保证各种场景下能正常实现Offset的记录即可
•保证消费数据不重复需要每次消费处理完成以后,将Offset存储在外部存储中,例如MySQL、Zookeeper、Redis中
•保证以消费分区、处理分区、记录分区的offset的顺序实现消费处理
•如果故障重启,只要从外部系统中读取上一次的Offset继续消费即可
总结
今天我们复习了面试中常考的Kakfa相关的五个问题,你做到心中有数了么?
其实做这个专栏我也有私心,就是希望借助每天写一篇面试题,督促自己学习,以免在吹水群甚至都没有谈资!
对了,如果你的朋友也在准备面试,请将这个系列扔给他,
好了,今天就到这里,学废了的同学,记得在评论区留言:打卡。给同学们以激励。









 京公网安备 11010802041100号
京公网安备 11010802041100号