篇首语:本文由编程笔记#小编为大家整理,主要介绍了大数据反爬日记01相关的知识,希望对你有一定的参考价值。
记录自己的反爬日记
既然要做反爬,就肯定得有有爬虫来爬取页面,这里前面已经写好了一个简单的爬虫,将爬取的数据通过python+flask+gunicorn+nginx部署到linux上面了,接下来通过采集爬虫对页面的请求日志进行分析
hadoop (因为是采用最近比较火的大数据技术,所以需要提前准备好大数据的相关环境)
hive(用于分析离线指标)
spark(用spark引擎来分析实时请求的日志)
Hbase(大数据的数据库)
filebeat+logstash(请求日志的采集工具)
kafka(高吞吐的实时的消息队列)
zookeeper
azkaban(用于任务的调度)
以上作为整个反爬的架构准备,本文主要讲逻辑开发,环境搭建可以参考网上的博文,后续可能会更新大数据框架的搭建
本次仅记录采集数据到kafka,通过spark进行数据etl+结构化输出
下个博客在进行爬虫分析

简单设计建模以下,后续可能会有改动,但是大致的方向就如上图所示,比较简单
补充:
关于数据采集方面,有很多选择,比如flume,或值filebeat可以直接发送到kafka,这里之所以这么选型主要是模拟的是一种大数据环境.
filebeat是logstash的一种轻量化实现,用于部署在承载着web程序的服务器上,减少服务器压力,将采集的日志转发到部署logstash的服务器上,由于lostash是重量级的java程序,所以应该部署在一个资源相对多的服务上专门作为处理数据转发的服务器(不参与业务服务)
数据源
python爬虫日记01
Python爬虫日记02-数据可视化_
采集工具
filebeat的搭建与配置

在程序根目录创建conf文件夹,并新建配置文件filebeat_logstash.yml
进行配置filebeat_logstash.yml
filebeat:
prospectors:
- input_type: log
paths:
- /usr/local/nginx/logs/user_access.log
output.logstash:
hosts: ["192.168.100.230:5044"]
/usr/local/nginx/logs/user_access.log 是我们采集的日志路径
hosts: [“192.168.100.230:5044”] 是我们转发到对应logstash所监听的端口 这里为了方便调试就在同一台机器进行实现,如果要在不同的服务器部署,需要开通对应的防火墙和通信
在程序根目录启动filebeat测试
./filebeat -e -c conf/filebeat_logstash.yml

这里报错是因为我们还没有启动logstash监听5044端口
部署logstash

在根目录创建myconfs目录,并新建配置文件
filebeat-logstash-kafka.conf
input
beats
port => "5044"
output
file
path => ['/logall/data/log/filebeat/filebeat-output.log']
启动logstash进行测试
bin/logstash -f myconfs/filebeat-logstash-kafka.conf

成功启动了监听
然后启动filebeat

也启动成功了
查看我们logstash的落地文件/logall/data/log/filebeat/filebeat-output.log
cat /logall/data/log/filebeat/filebeat-output.log
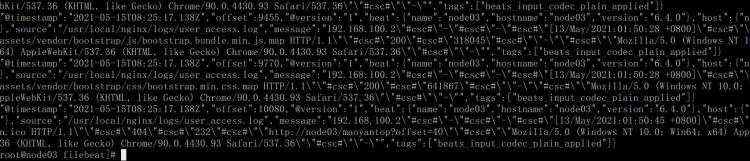
可以看到我们的数据已经同步过来了,我们的请求数据是以#cs#作为分割符进行拼接的,这个在之前一篇博客有nginx的配置
这里数据仅仅是落地到另一个文件而已,我们期望的是转发到kafka中,所以我们需要准备好kafka
对接kafka
kafka依赖于zookeeper,所以我们需要先启动zookeeper
这里准备了三台虚拟机,分别启动zk,进入zookeeper的根目录
bin/zkServer.sh start
分别启动了三台之后,查看zk状态
bin/zkServer.sh status
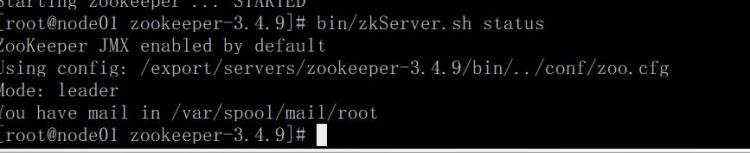
这样就是启动成功了
然后分别启动kafka
进入kafka的目录,采用后台启动的方式
nohup bin/kafka-server-start.sh config/server.properties 2>&1 &

这般则为启动成功
新建一个topic 在kafka的根目录下执行
bin/kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --replication-factor 1 --partitions 3 --topic spider_nginx_log
简单介绍以下这几个参数
kafka-topics.sh 这个是调用脚本,针对kafkatopic主题的
create 是告诉脚本创建topic
zookeeper 是指定我们kafka已经配置好的zookeeper,里面存放着一些元数据信息,包括历史的topic,一些offset等等…
replication-factor 指定我们数据的副本数量,这里测试,所以不需要太多副本
partitions 指定我们的分区,分区决定了我们数据的分散成都,也是kafka最大的特点之一,因为分区的存在,让kafka有很大的并行度支持大吞吐,当然支持大吞吐还有零拷贝这一大杀器
topic 指定我们创建的topic

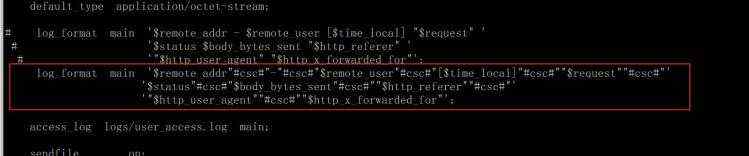
修改logstash的配置,之前落地的是文件,现在修改成输出到kafka
input
beats
port => "5044"
output
kafka
bootstrap_servers => "192.168.100.210:9092"
topic_id => "spider_nginx_log"
batch_size => 5
重新启动
bin/logstash -f myconfs/filebeat-logstash-kafka.conf
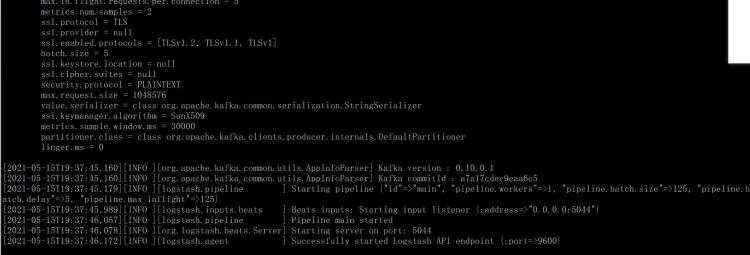
启动之前部署好的web程序Python爬虫日记02
监听kafka,消费一下topic,然后访问页面观察是否有数据
bin/kafka-console-consumer.sh --from-beginning --topic spider_nginx_log --zookeeper node01:2181,node02:2181,node03:2181

这边看到数据已经传入了,接下来配置spark对接kafka
1.在本地创建maven项目
使用的工具是IDEA
pom文件
<project xmlns&#61;"http://maven.apache.org/POM/4.0.0"
xmlns:xsi&#61;"http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation&#61;"http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>it.lukegroupId>
<artifactId>Spider_sparkartifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<scala.version>2.11.8scala.version>
<spark.version>2.2.0spark.version>
properties>
<dependencies>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version> 0.10.0.0version>
dependency>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>2.11.8version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>$spark.versionversion>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql-kafka-0-10_2.11artifactId>
<version>2.2.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
<version>$spark.versionversion>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka-0-10_2.11artifactId>
<version>2.2.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.11artifactId>
<version>$spark.versionversion>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.6.0version>
dependency>
dependencies>
<build>
<sourceDirectory>src/main/scalasourceDirectory>
<testSourceDirectory>src/test/scalatestSourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.0version>
<configuration>
<source>1.8source>
<target>1.8target>
<encoding>UTF-8encoding>
configuration>
plugin>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.0version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
<configuration>
<args>
<arg>-dependencyfilearg>
<arg>$project.build.directory/.scala_dependenciesarg>
args>
configuration>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>3.1.1version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<filters>
<filter>
<artifact>*:*artifact>
<excludes>
<exclude>META-INF/*.SFexclude>
<exclude>META-INF/*.DSAexclude>
<exclude>META-INF/*.RSAexclude>
excludes>
filter>
filters>
<transformers>
<transformer implementation&#61;"org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>mainClass>
transformer>
transformers>
configuration>
execution>
executions>
plugin>
plugins>
build>
project>
新建scala object
package it.luke.spark.spider_kafka
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.Seconds, StreamingContext
/**
* &#64;author luke
* &#64;date 2021/5/1521:17
*/
object KafkaStream
def main(args: Array[String]): Unit &#61;
/*
* 1.创建配置对象,生成sparkStream对象
* 2.配置kafka参数,连接kafka
* 3.读取kafka,解析数据,结构化,输出
*
* */
//sparkconf
var conf &#61; new SparkConf().setMaster("local").setAppName("my_spiderapp")
//本地测试
//创建stream对象
val scc &#61; new StreamingContext(conf, Seconds(2))
scc.sparkContext.setLogLevel("WARN") //提高日志输出级别,方便调试
//kafka 配置
//kafka topic
val topics &#61; Array("spider_nginx_log")
//kafka 其它参数
val kafkaParams &#61; Map[String, Object](
"bootstrap.servers" -> "node01:9092,node02:9092,node03:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "mygroup_spider_nginx_log",
"auto.offset.reset" -> "latest", //可以指定读取kafka的进度
"enable.auto.commit" -> (false: java.lang.Boolean)
)
/*createDirectStream(
ssc: StreamingContext,
locationStrategy: LocationStrategy,
consumerStrategy: ConsumerStrategy[K, V])
* */
val source &#61; KafkaUtils.createDirectStream(scc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams)
)
/*
* LocationStrategies.PreferConsistent,是一种分配策略,让每个executor参与分区
* ConsumerStrategies.Subscribe 是一种消费策略
* Subscribe为consumer自动分配partition&#xff0c;有内部算法保证topic-partitions以最优的方式均匀分配给同group下的不同consumer
* */
source.foreachRDD(rdd &#61;>
val asd: RDD[ConsumerRecord[String, String]] &#61; rdd
asd.map(_.value()).foreach(x&#61;>
var strings &#61; x.split("#csc#")
if(strings.length >2)
var obj&#61; req_obj(strings(0),
strings(2),
strings(3),
strings(4),
strings(5),
strings(6),
strings(7),
strings(8)
)
println(obj)
)
// println(req_obj.toString())
//提交offset
val offsets &#61; rdd.asInstanceOf[HasOffsetRanges].offsetRanges
source.asInstanceOf[CanCommitOffsets].commitAsync(offsets)
)
//启动streaming
scc.start()
//阻塞
scc.awaitTermination()
/*
* &#39;$remote_addr"#csc#"-"#csc#"$remote_user"#csc#"[$time_local]"#csc#""$request""#csc#"&#39;
&#39;$status"#csc#"$body_bytes_sent"#csc#""$http_referer""#csc#"&#39;
&#39;"$http_user_agent""#csc#""$http_x_forwarded_for"&#39;;
* */
case class req_obj(remote_addr: String,
remote_user: String,
time_local: String,
request: String,
body_bytes_sent: String,
http_referer: String,
http_user_agent: String,
http_x_forwarded_for: String
)

这里看到,数据已经从kafka对接过来了,spark是一种伪流式的引擎,因为我们需要指定每一批的接受间隔,
val scc &#61; new StreamingContext(conf, Seconds(2))
这里是每两秒处理一批,将数据封装到rdd里面进行处理
接下来要根据采集到的数据,分为两个方向,一个是离线分析,一个是实时分析
离线分析需要主要是展示一种未来或者过去的一种趋势作为分析,所以需要有一定的分析数据.
实时的话,是根据统计短时间内抓到的几批数据中,最有可能是爬虫的数据,进行打标,加入黑名单,并入库
后续就可以根据对接的数据,进行实时分析,根据自定义的策略抓爬虫了^
欢迎分享交流~









 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有