1 DDD
Domain Driven Design(领域驱动设计, DDD),不是一种架构,而是一种架构方法论,是一种拆解业务、划分业务、确定业务边界的方法,是一种领域设计思想。
核心思想:建立领域模型,领域模型处于架构的核心位置。
核心目标:避免业务逻辑的复杂度与技术实现的复杂度混淆在一起。
DDD包括战术设计和战略设计两部分。
战略设计:侧重于高层次、宏观上去划分和集成限界上下文。
战术设计:关注更具体使用建模工具来细化上下文。
为什么要用DDD:
2 Strategic DDD(战略设计)
2.1 简介
Bounded Context(限界上下文):用来界定领域边界。
Context Mapping(上下文映射图、上下文图):用来描述系统关系。主要有以下几种关系:
Shared Kernel(共享内核)
Customer/Supplier(客户/供应商)
Conformist(追随者)
Anticorruption Layer(防腐层)
Open Host Service(公开主机服务)
Published Language(发布语言):通常与Open Host Service一起使用,用于定义开放主机的协议。
Ubiquitous Language(通用语言)
团队统一的语言,是能够简单、清晰、准确的描述业务规则和业务含义的语言。
2.2 Bounded Context(界限上下文,BC)
2.2.1 从一个段子开始
开始之前,先说思考一个问题:早上起床,妈妈让小明衣服能穿多少穿多少,那么小明是应该多穿衣服呢,还是少穿衣服呢?如果没有所处的环境,我们其实无法判断。因为如果是在夏天,妈妈的意思是让小明少穿衣服;如果是在冬季,妈妈意思是让小明多穿衣服。在程序的世界中,Bounded Context就是为了确定领域边界,让每一个事物的表达精确。
2.2.2 举个例子
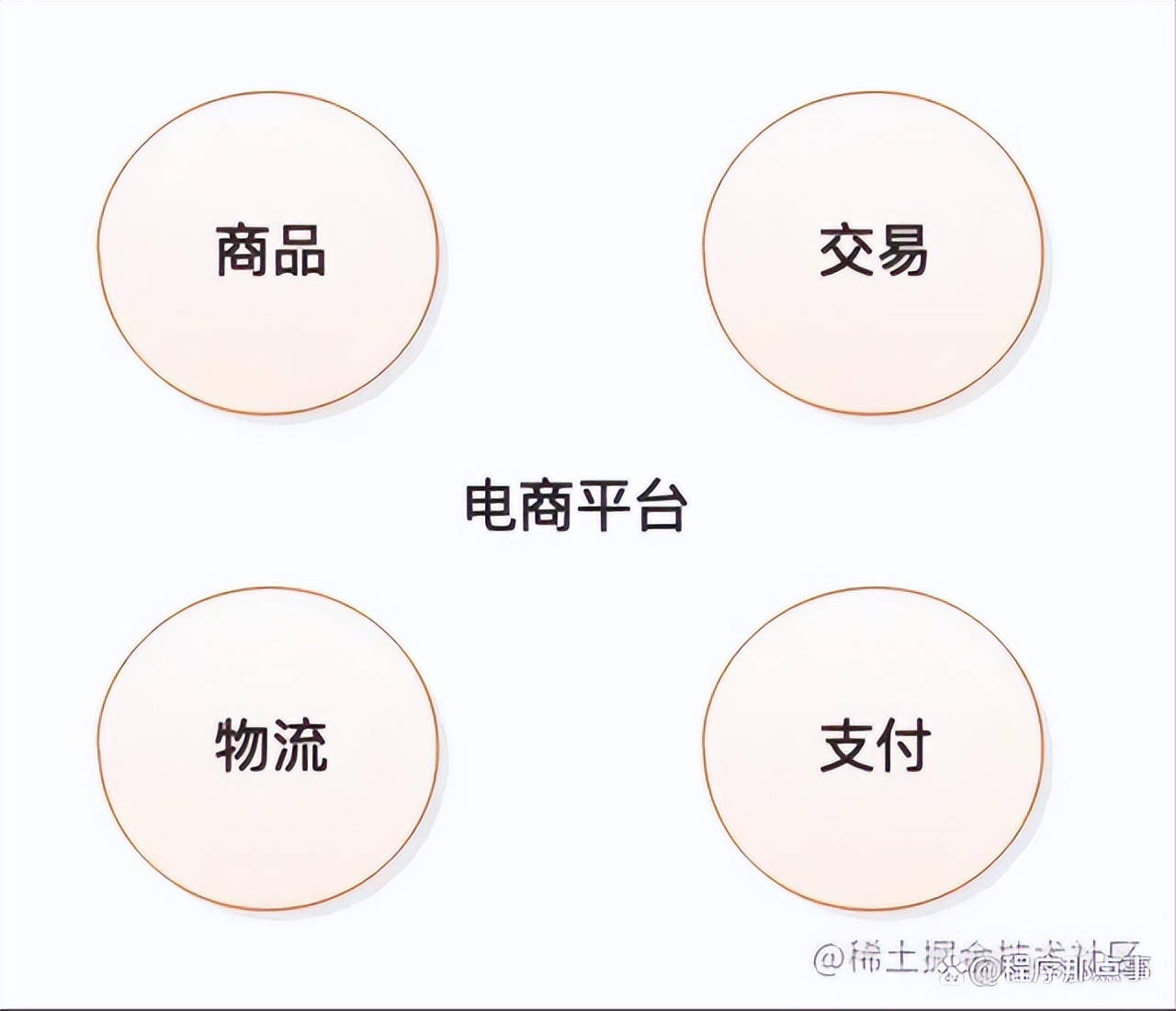
如果我们要设计一个电商平台,那么我们需要就要有商品、交易、支付、物流等模块,这些模块其实就是一个个的领域。在不同领域中,同样一个事物的因为关注点不同,其含义也不同,但是在确定的上线文中,其含义就是确定的。例如:
在商品领域我们关注商品的基本信息(名字、品牌、型号、价格等),在交易领域我们关注交易流程(订单创建、支付结果、履约过程等),但同样是商品,在交易领域中我们称之为订单明细或交易明细;所以当我们在交易领域谈及商品的时候,我们指的是订单的明细(商品),而且一般只关注交易履约状态,顺其自然的不会那么在意商品属性。
同样是一个用户,在用户领域我们关注其基本信息、账号密码等,但是在权限领域,我们关注的是其拥有的菜单、功能权限,关注其角色。
以上示例这直接反映在代码层面时,其差异是非常明显的,当在确定领域内讨论问题是,其指代性也很强。
在不同场景中,我们对同一个事物的称呼也有较大差异。例如,商品、货物:同样一个东西,在交易领域叫做商品,在物流领域叫货物。渠道商品、后端商品:在进销存管理中,在销售测叫做渠道商品(可以通过多个渠道售卖,例如在淘宝、京东上卖);在采购侧叫做后端商品。
2.2.3 什么是Bounded Context
Bounded Context定义领域边界,以确保每个上下文含义在它特定的边界内都具有唯一含义。Bounded Context定义了模型的适用范围,使团队所有成员能够明确地知道什么应该在模型中实现,不应该在模型中实现。注意:处于不同界限上下文中,领域模型一定不可以共用。例如:上面示例中的商品/货物、商品/订单明细不可以使用同一个模型,不过这对于有经验的开发者而言也是显而易见的。
2.2.4 领域拆分
继续之前电商平台的示例,电商平台可以分为商品、交易、支付、物流几个领域,如图:
随着业务发展,这些领域可以进一步拆分出多个子领域出来,例如:商品可以拆分为:类目、库存、商品等领域;交易可以拆分为:交易、促销、优惠券、售后等领域;支付可以拆分为:支付核心、支付路由、支付渠道等领域。如图:
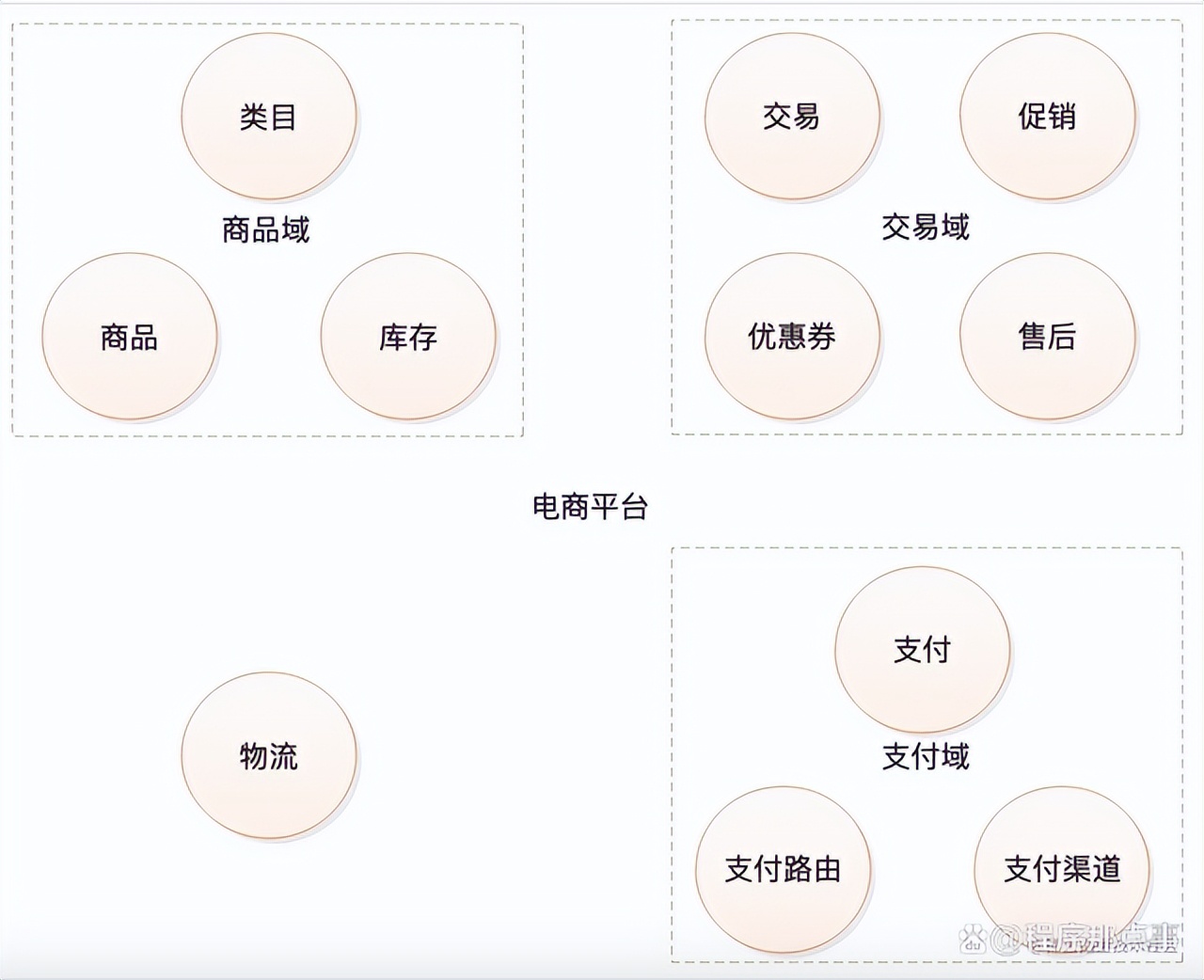
随着业务的继续发展,这里的所有领域、子域都有可能面临再次拆分的可能。熟悉微服务开发的小伙伴,看到这里应该就很清楚了,一个领域可以是一个独立的微服务,而实际上微服务正是领域拆分的结果。如果不考虑技术异构、团队沟通等因素,一个限界上下文理论上就可以设计为一个微服务。
上面领域拆分的过程其实就是划分Bounded Context的过程,每一个Bounded Context就是一个领域。
2.2.5 领域
领域根据核心程度不同,分为Core Domain、Supporting Domain、Generic Domain。
Core Domain(核心领域):公司的业务核心。例如电商业务中,商品、购物车、交易、促销、优惠、支付等都属于核心领域
Generic Domain(通用领域):通用的领域,没有个性化的需求,甚至是各个公司都类似的功能或市场上可以直接购买到,可以被多个子域使用的领域,例如:用户、权限、认证、人脸识别等。
Supporting Domain(支撑领域):一般是只不是系统中的最核心模块,但是也不是通用的组件和服务,但是对核心业务起到了支撑的作用的模块。
2.2.6 Ubiquitous Language(通用语言)
通用语言是:团队统一的语言,是能够简单、清晰、准确的描述业务规则和业务含义的语言。通用语言的价值:
解决各岗位的沟通障碍问题,确保业务需求的正确表达。
如果没有通用语言,因为业务、产品、开发、测试的角色和术语不同,经常会遇到battle了很久,结果说的是同一个事情。
如果没有通用语言,产品、开发、测试经常不能达成一致,导致开发的内容和业务诉求不同。
通用语言贯穿于整个设计过程,能准确的把业务需求转化为代码。
通用语言中的名词一般可以给领域对象命名。例如:订单、商品可以对应到领域中的一个实体。
通用语言中的动词一般对应一个动作或领域事件。例如:订单已支付,订单已发货都对应一个领域事件。
2.3 Context Map(上下文映射图)
Context Map描述的是各个系统之间关系的总体视图,有以下几种关系:
2.3.1 Shared Kernel(共享内核)
在电商场景中,购买不同品类的商品,其流程也会有非常大的差异。例如:买卖实物商品的流程一般是:买家付款、卖家发货、买家确认收货;买卖酒店房间的流程一般是:买家付款、卖家预留客房、买家入驻、买家退房结单;买卖旅游线路的流程一般是:买家付款、卖家确认、服务履约。
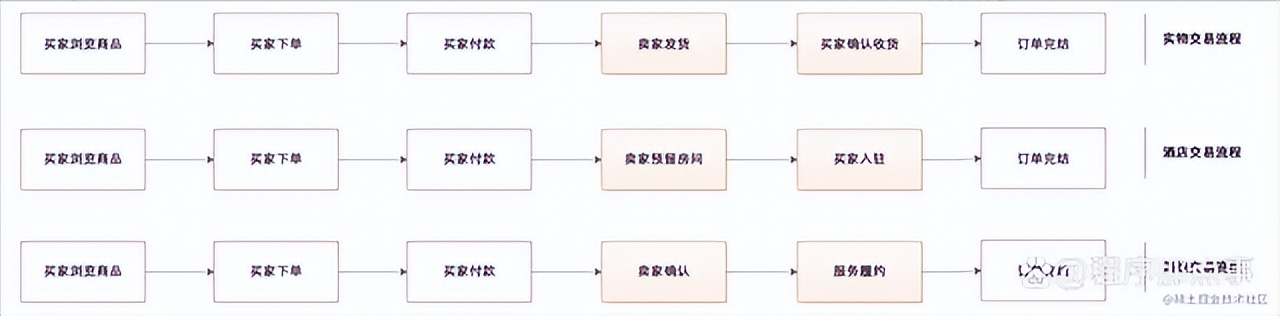
这些业务场景、交易流程虽然有较大的的差异,但是他们可以共同复用核心的交易流程,如下图所示:
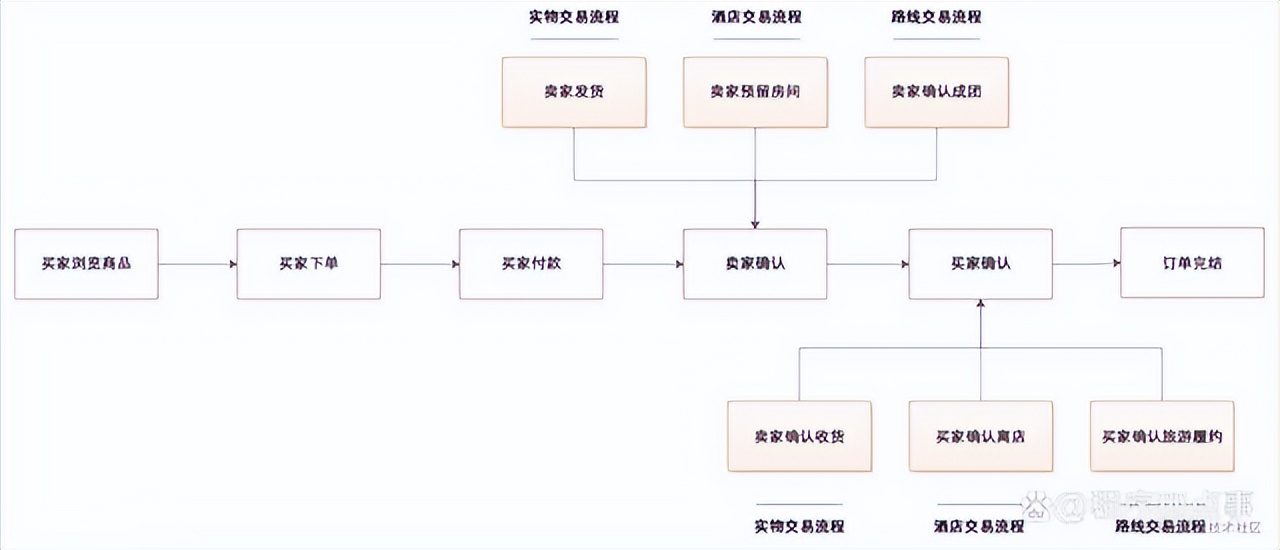
可以不使用共享内核么?或者说共享内核对于系统架构来说有什么好处?
复用。用同一套抽象的交易流程即可完成对不同场景的业务支持,可以极大地节省开发成本。
扩展。如果没有复用流程,各个业务场景分别搞一套,那么如果过一段时间要支持促销、优惠券、套餐等,就需要在各个业务线分别开发一遍。
维护。如果在其中一套流程中发现有问题需要迭代优化,那么另外两套流程很可能也要调整。
其实还有很多好处,具体可以参考中台架构的优势,这里就不在一一讨论了。上面这个示例并不是纯粹YY的思想实验,在我之前的工作经历中有一段经历是做旅游的公司进行线上转型,同时遇到了以上的几种场景。
如上示例,从多个团队或业务中剥离的共享的子集,就是共享内核。
2.3.2 Customer/Supplier(客户/供应商)
分布式开发中随处可见,即接口提供者就是Supplier(或Provider),接口消费者就是Customer(或Consumer)。
2.3.3 Conformist(追随者)
有些场景中,一个系统(例如:A)的状态变化会直接影响另一个系统(例如:B)的结果,并且当A系统状态变化了以后B系统状态必须变化,这种系统关系即为Conformist。例如:支付系统已经完成了支付,支付订单的状态已经变成「已支付」,那么交易系统的订单状态也必须变化,变成「买家已付款」。
2.3.4 Anticorruption Layer(防腐层)
如果依赖的系统设计的不友好,不适合当前系统的场景,降低系统间依赖和耦合,就需要使用防腐层(Anticorruption Layer)模式。
2.3.5 Open Host Service(公开主机服务)
就是将系统的一组服务暴露出去,给其他系统使用。例如微服务开发中的给其他系统使用接口(Service)。
3 Tactical DDD(战术设计)
3.1 战术设计内容
3.1.1 Aggregate(聚合) & Aggregate Root(聚合根)
定义:在领域模型中,我们将紧密联系的个体聚合在一起,按照组织内统一的业务规则完成特定的业务功能,这就是聚合。例如,在电商中,主订单、订单明细他们的业务规则相同,而且基本上都是一同操作的,对订单进行操作的时候,基本上都会同时修改主订单和订单明细,那么主订单和订单明细就是一个聚合。在这个聚合中,操作的入口基本都是主订单,所以主订单就是这个聚合的聚合根。
注意:聚合内的内容具有一致性,即:需要在事务中修改一个聚合的内容。如果没有一致性要求,那么应该就不属于一个聚合。通过唯一标识来引用其他聚合或实体。如果聚合创建复杂,推荐使用工厂方法来屏蔽内部复杂的创建逻辑。在传统数据模型中,一般认为每个实体都是对等的,可以单独修改任意一个实体;在DDD中,聚合内对象的修改必须按照统一的业务规则来完成,聚合是数据修改、持久化的基本单元。
示例:交易系统中的订单包括主单、明细,他们就是一个聚合,主单就是这个聚合的聚合根。商品系统中的商品包括Item(商品)、SKU(商品的库存单元),他们也是一个聚合,其中Item就是一个聚合根。
聚合设计的原则:设计小聚合。小聚合可以降低数据冲突,规避业务过大。通过唯一标识引用其他聚合。聚合内保持数据强一致,聚合外保持数据最终一致。通过应用层实现跨聚合调用。
3.1.2 Entity(实体)
定义:有一对象拥有唯一标识(一般是id),在经历各种状态变化后,唯一标识依然保持不变,对这种对象而言,重要的是具有延续性的唯一标识,而不是属性。领域中这种对象称为实体。实体一般对应业务对象,拥有属性和业务行为。实体是基础的领域对象(Domain Object)。
示例:DB表中的数据加载到内存中以后就变成一个实体,我们都是通过db主键来区别不同的记录。
3.1.3 Value Objects(值对象)
定义:无唯一标识的简单对象。其唯一标志不重要,重要的是其属性,其描述的是领域中的一个信息,这种对象称为值对象。值对象是属性集合,是对实体信息的描述。值对象也是基础的领域对象(Domain Object)
示例:订单对象中的商品信息、地址信息就是值对象。
3.1.4 Domain Services(领域服务)
一些重要的领域行为或操作,可以归类为领域服务。它既不是实体,也不是值对象的范畴。
3.1.5 Domain Events(领域事件)
领域事件是对领域内发生的活动进行的建模。
3.1.6 Factory(工厂模式)
在创建对象时,有些聚合需要实体或值对象较多,或者关系比较复杂,为了确保聚合内所有对象都能同时被创建,同时避免在聚合根中加入与其本身领域无关的内容,一般会将这些内容交给Factory处理。Factory的主要作用:封装聚合内复杂对象的创建过程,完成聚合根、实体、值对象的创建。
3.1.7 Repository Model(仓储模式)
为了避免基础层数据处理逻辑渗透到领域层的业务代码中,导致领域层和基础层形成紧密耦合关系,引入Repository层。Repository分为Interface和Implement,领域层依赖Repository接口。
3.1.8 Modules(模块)
在创建系统的时候,我们一般会根据负责的内容,将一个系统划分为多个模块,每个模块一般和子领域对应。
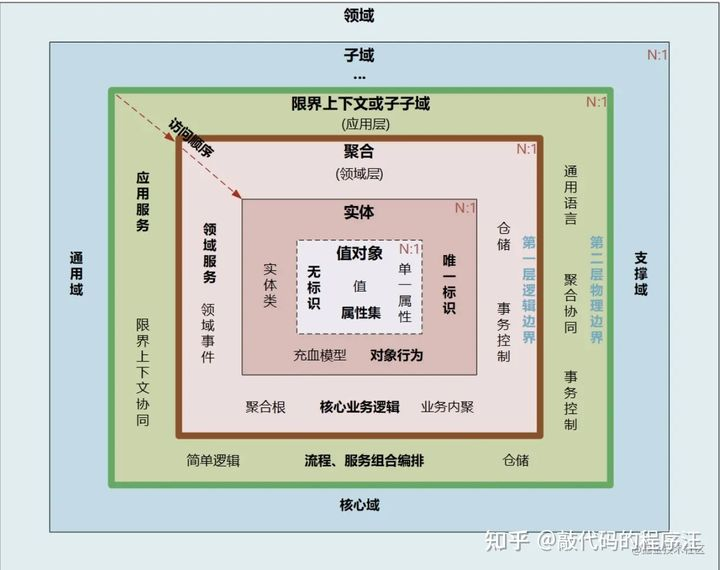
4 DDD的分层架构和构成要素
4.1 分层架构
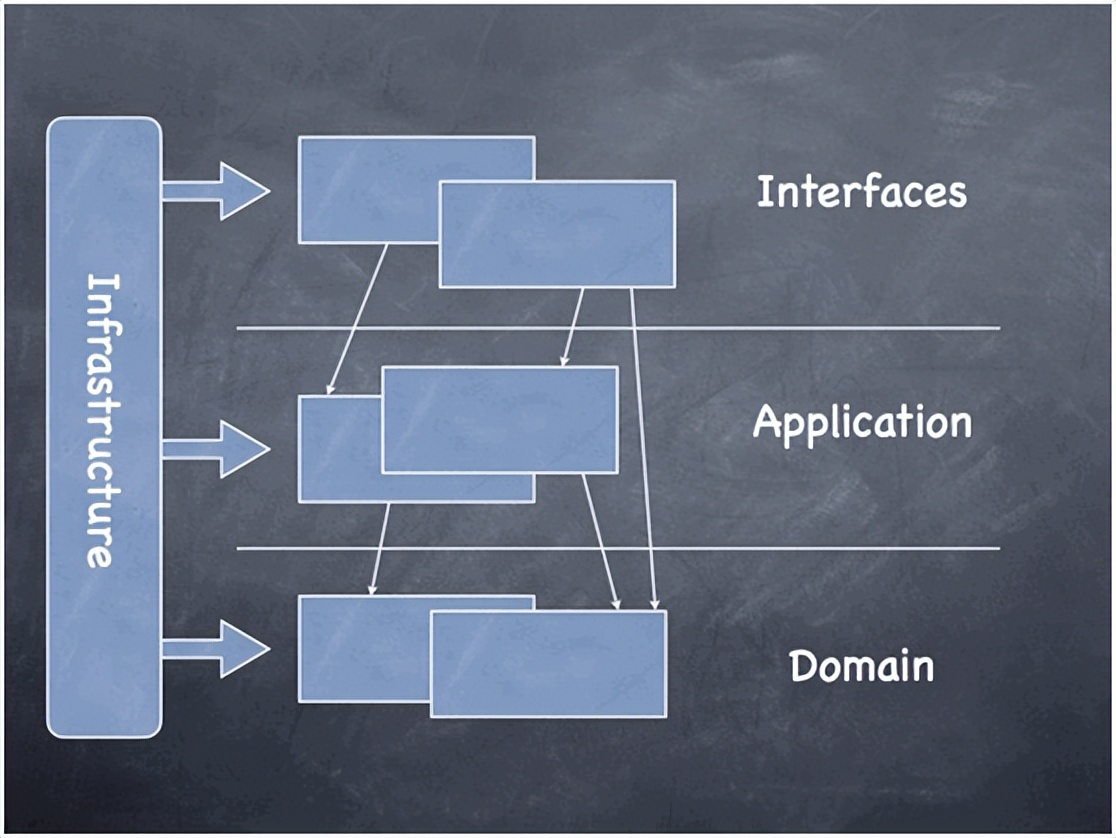
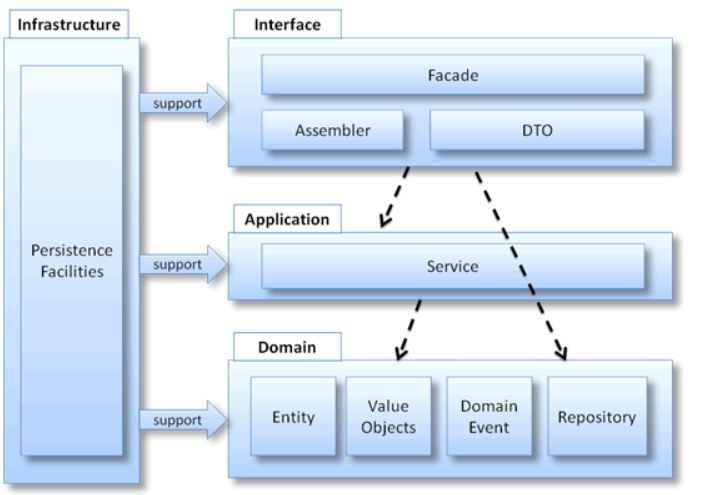
整个架构分为四层,其核心就是领域层(Domain),所有的业务逻辑应该在领域层实现,具体描述如下:
用户界面/展现层,负责向用户展现信息以及解释用户命令。
应用层,很薄的一层,用来协调应用的活动。它不包含业务逻辑。它不保留业务对象的状态,但它保有应用任务的进度状态。
领域层,本层包含关于领域的信息。这是业务软件的核心所在。在这里保留业务对象的状态,对业务对象和它们状态的持久化被委托给了基础设施层。
基础设施层,本层作为其他层的支撑库存在。它提供了层间的通信,实现对业务对象的持久化,包含对用户界面层的支撑库等作用。
4.2 构成要素
实体(Entity),具备唯一ID,能够被持久化,具备业务逻辑,对应现实世界业务对象。
值对象(Value Object),不具有唯一ID,由对象的属性描述,一般为内存中的临时对象,可以用来传递参数或对实体进行补充描述。
领域服务(Domain Service),为上层建筑提供可操作的接口,负责对领域对象进行调度和封装,同时可以对外提供各种形式的服务。
聚合根(Aggregate Root),聚合根属于实体对象,聚合根具有全局唯一ID,而实体只有在聚合内部有唯一的本地ID,值对象没有唯一ID
工厂(Factories),主要用来创建聚合根,目前架构实践中一般采用IOC容器来实现工厂的功能。
仓储(Repository),封装了基础设施来提供查询和持久化聚合操作。
5 从领域划分到系统落地
以电商平台为例,DDD战略设计指导微服务落地如下图所示。
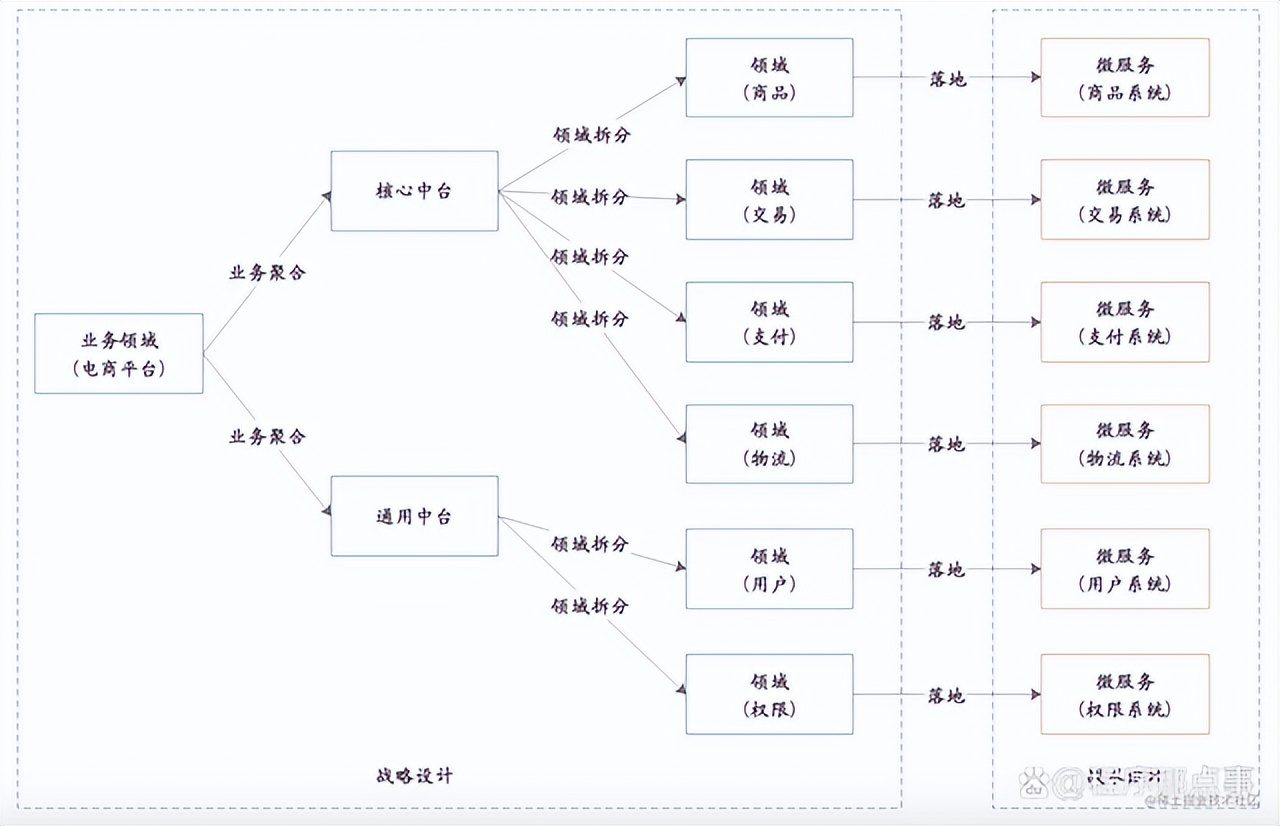
将电商领域进行细分,然后将业务相近、耦合紧密的领域聚合在一起,落地成我们的业务系统。
每个领域都有很多内容,下面以商品领域为例,我们将商品领域进行进一步细分,可以分为类目、属性、属性值、SPU、Item、SKU,然后关系紧密的内容据合在一起,形成一个个的聚合。
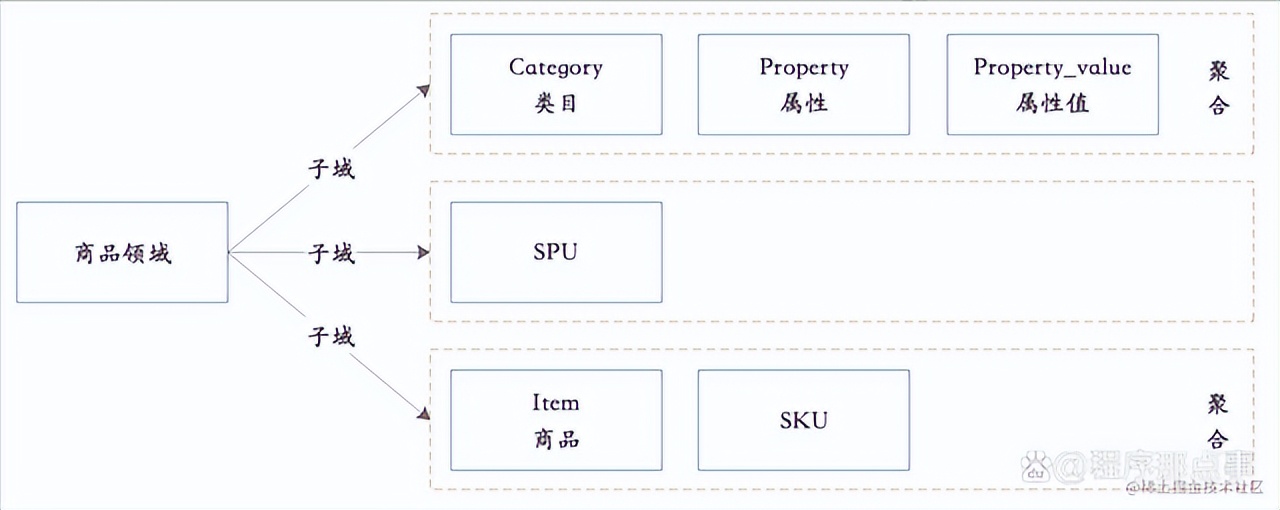
6 领域模型
6.1 贫血模型(Anemic Model)
贫血模型是值领域对象中:只数据没有行为。即:模型中只有属性、set、get方法,逻辑放在业务逻辑层(Service/Manager)中。只有数据没有行为的对象不是真正的对象,所以贫血模型是一种反模式,和面向对象设计相违背。领域对象只是作为保存状态或者传递状态使用,在业务逻辑层处理所有的业务逻辑,对于细粒度的逻辑处理,通过增加一层Facade达到门面包装的效果。
一般在使用Spring的项目中,这种贫血模型随处可见,以下是使用贫血模型后,典型的系统结构图:
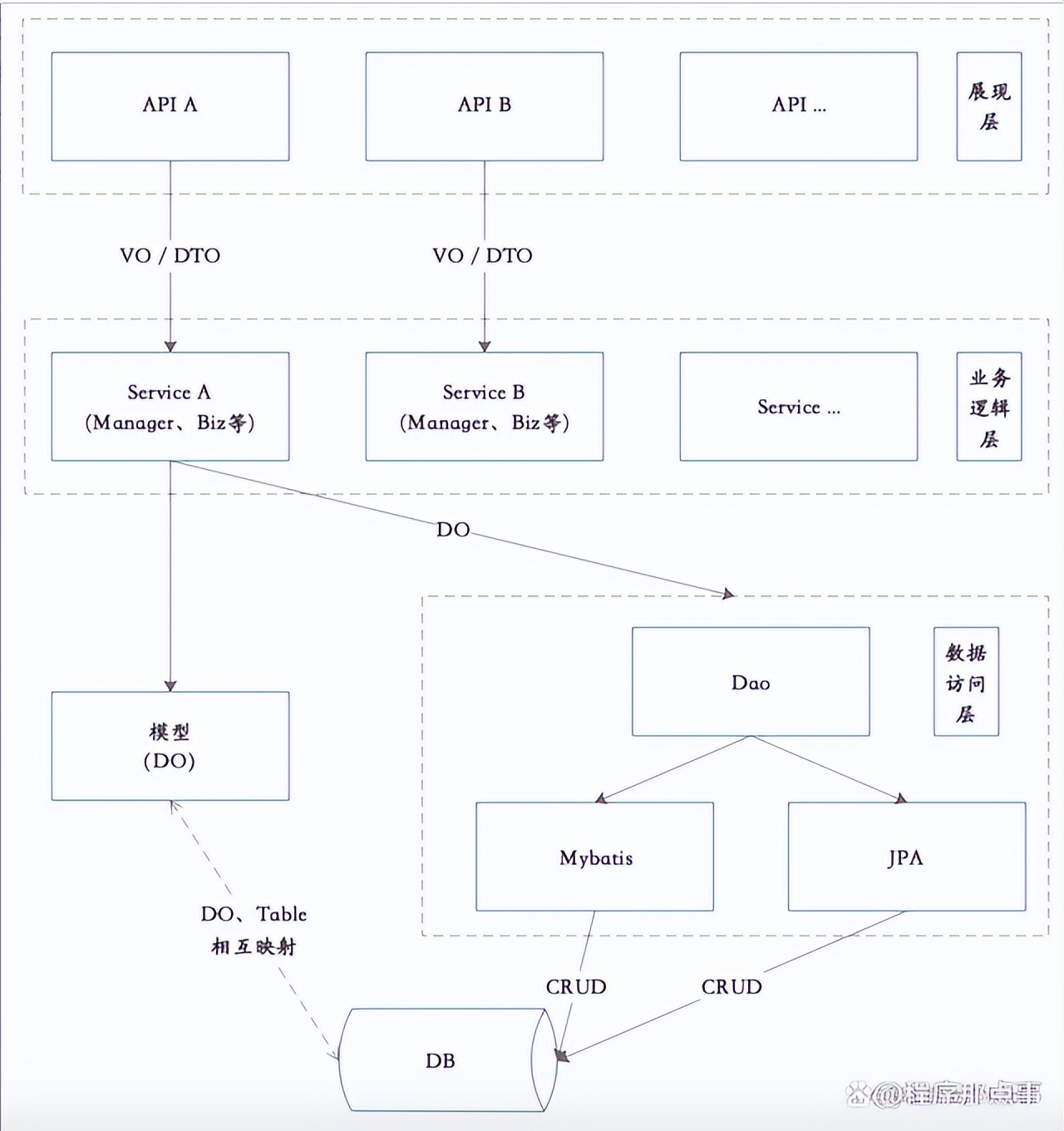
这种系统结构层次简单清晰,即:Consumer/Api -> Service -> Manager/Biz -> Dao -> Mybatis -> DB。贫血的领域对象起的作用是:只传递数据,不包含任何业务逻辑。在[DDD-Domain Primitive](DDD-Domain Primitive.md)中有一些简单的小例子,介绍了领域对象如果不包含逻辑,将会在持续的迭代升级中,给开发、维护工作带来大量成本。
6.2 充血模型
面向对象设计的本质是:“一个对象是拥有状态和行为的”,充血模型就是那种即拥有属性、又拥有操作的类。修改一个用户信息,然后保存,在贫血模型的场景中示例代码如下:
user.setXXX();userManager.save(user);
在充血模型的场景中,代码如下所示:
user.setXXX()user.save();
典型的系统结构图:
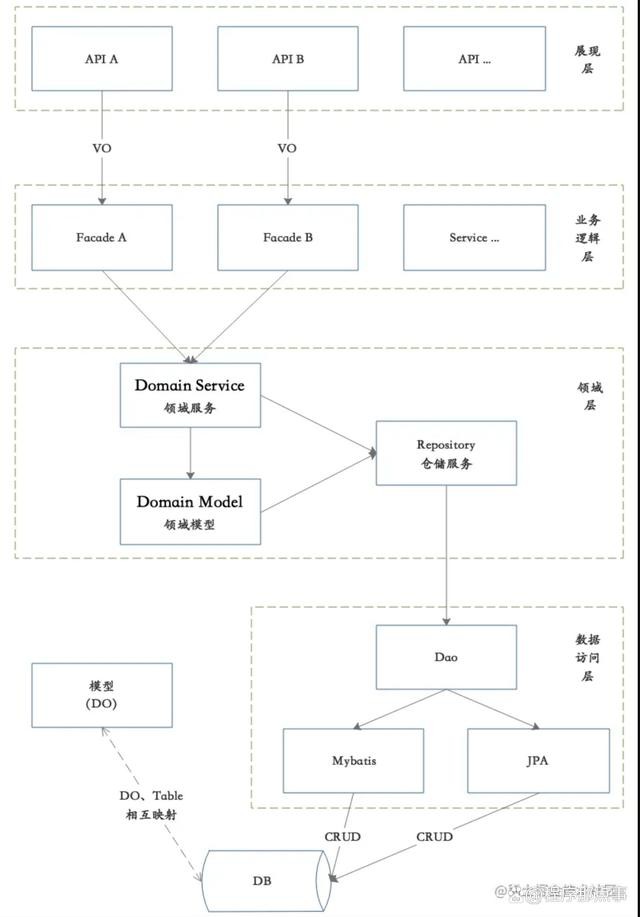
优点:是面向对象的;Service符合单一职责。缺点:那些逻辑放在Domain Object中,那些逻辑放在Service中,比较含糊。编码成本也比较高,事务控制的成本也会增加。
7 CQRS模式
7.1 CQRS简介
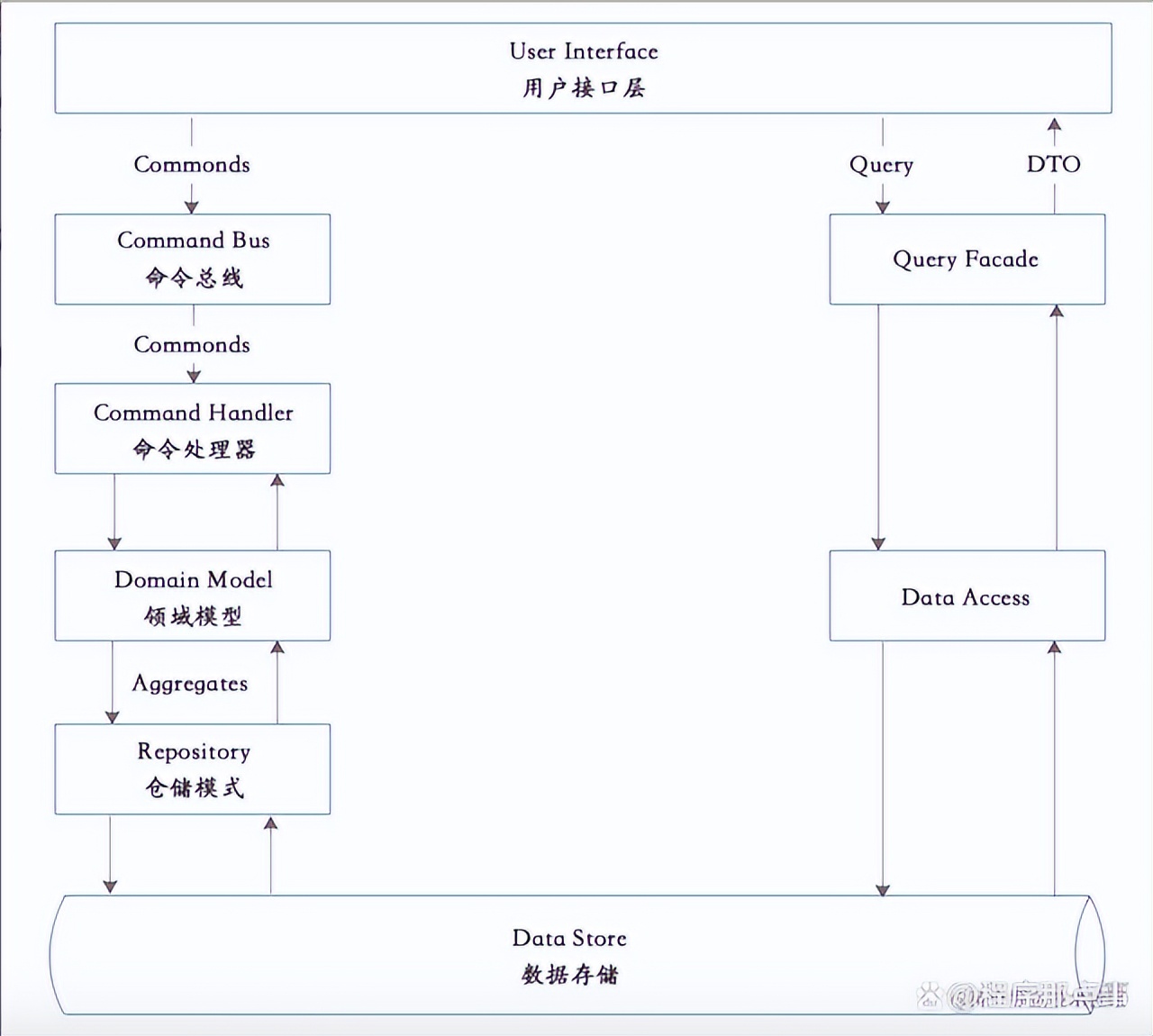
CQRS(Command Query Responsibility Segregation)是将Command(命令)与Query(查询)分离的一种模式。其基本思想在于:任何一个方法都可以拆分为命令和查询两部分:
Command:不返回任何结果(void),但会改变对象的状态。Command是引起数据变化操作的总称,一般会执行某个动作,如:新增,更新,删除等操作。操作都封装在Command中,用户提交Commond到CommandBus,然后分发到对应的CommandHandler中执行。Command执行后通过Repository将数据持久化。事件源(Event source)CQRS,Command将特定的Event发送到EventBus,然后由特定的EventHandler处理。
Query:返回查询结果,不会对数据产生变化的操作,只是按照某些条件查找数据。基于Query条件,返回查询结果;为不同的场景定制不同的Facade。
7.2 CQRS三种模式
7.2.1 单数据库的CQRS
7.2.2 读写分离的CQRS
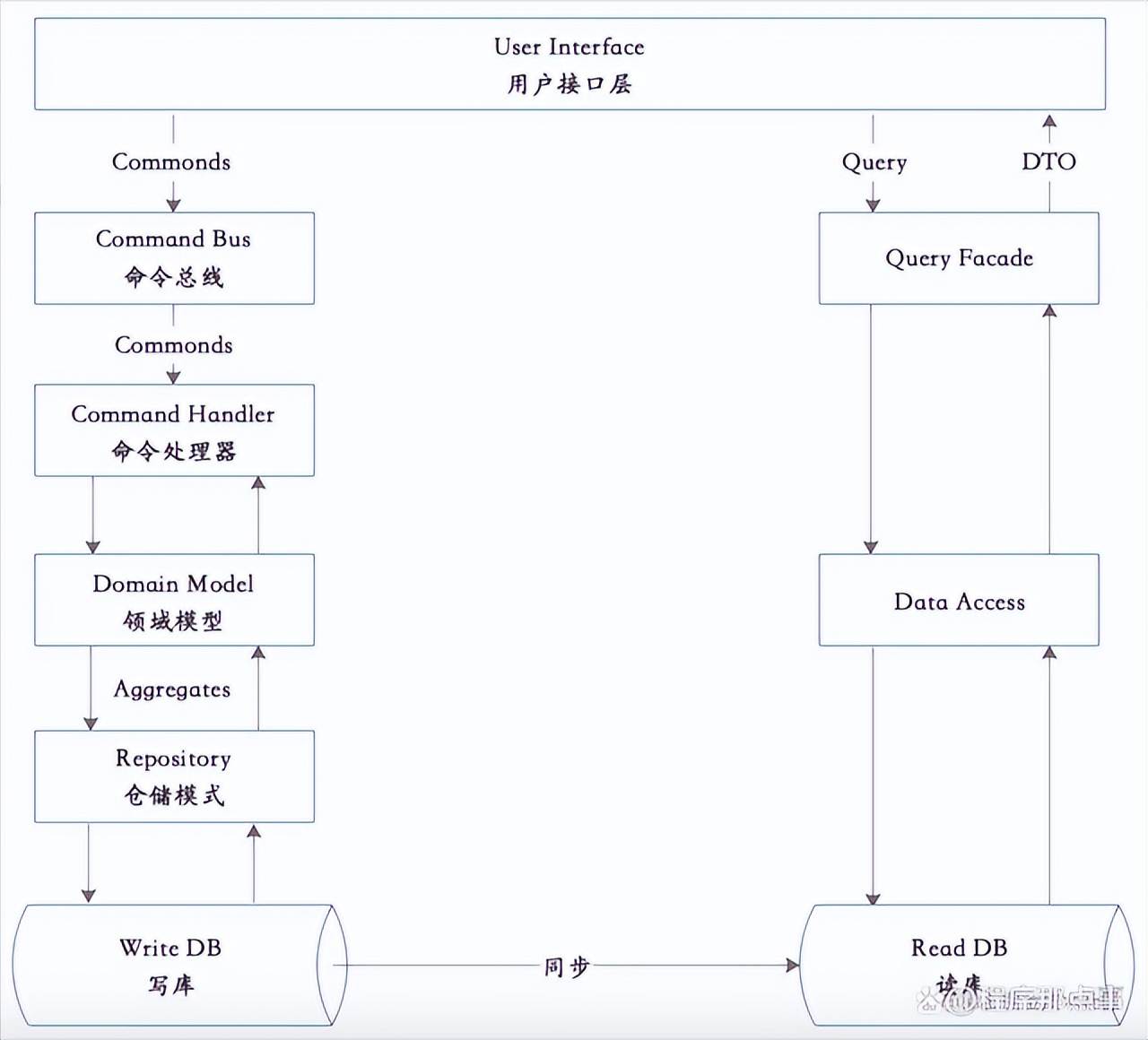
CQRS不只是为了分离数据的写入和读取,它的根本目的是为了实现数据的多重表示,每一种表示都能够满足某些用户的需求。CQRS可能会有多种查询模式,可以使用数据库、Redis,ES等等。例如对于复杂的数据查询诉求,Command负责将数据落到DB中,然后同步到ES中,Query端从ES中查询需要的数据。
7.2.3 事件源的CQRS
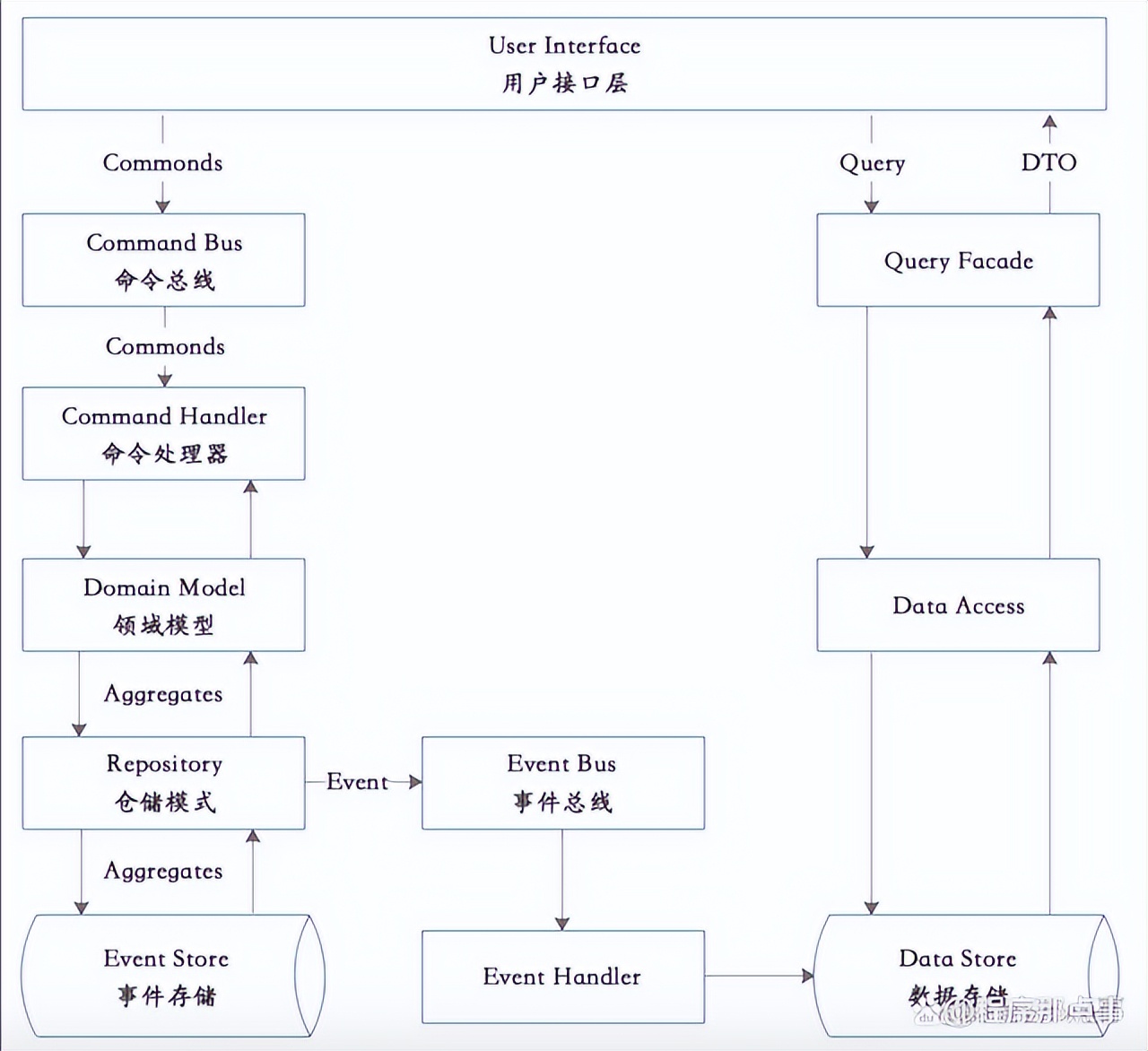
当Command系统完成数据更新的操作后,会通过「领域事件」的方式通知Query系统。Query系统在接受到事件之后更新自己的数据源。所有的查询操作都通过Query系统暴露的接口完成。
7.4 CQRS架构的优点
Command、Query两端架构分离、相互不受束缚,各自独立设计、扩展
Command端通常结合DDD,解决复杂的业务逻辑;
Query端轻量级查询,多种不同的查询视图通过订阅事件来更新
Command端通过分布式消息队列水平扩展,天然支持削峰
EDA架构(Event-Driven Architecture, 事件驱动架构),整个系统各个部分松耦合,可扩展性好
架构层面做到无并发,实现Command的高吞吐
技术架构和业务代码完全分离,程序员不用关心技术问题,更方便的分工合作
7.5 CQRS架构的缺点
需要处理事务问题,开发成本提高。例如一个Command可能需要修改多个DB,数据一致性处理成本较高。CQRS不是强一致性,而是面向最终一致性
实效性问题。Command端修改后同步给Query端可能存在时间差,那么Command修改数据后、Query可能查询到旧数据。Event传递需要稳定且性能强大的分布式消息队列
必须有强大可靠的CQRS框架,从头做起成本高、风险大
最好结合Event Sourcing模式,否则Command、Query分离意义不大
提高了开发人员的门槛
8 总结
通过本文介绍,我们了解DDD是为解决软件复杂性而诞生,与OOP最大的区别就是划分边界的方式不一样,所以DDD本身掌握起来并不会感觉复杂,DDD其实是研究将包含业务逻辑的ifelse语句放在哪里的学问。
在DDD中,应用层依赖于领域和基础设施层,而基础设施依赖于领域层,但是领域层不依赖于任何层。
只在领域层编写业务规则和通用的领域知识,而应用层负责针对软件的目标来组合、协调领域层的业务规则。
领域层的领域实体、值类型、聚合根反映了真实业务的核心,需要用一种通用的语言来定义,这样不管应用层多么复杂,核心领域层自岿然不动。
领域层不能直接依赖与基础设施层,现代ORM框架一般都提出仓储模型来帮助领域层和技术设施层解耦。






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有