丨目录:
· 摘要
· 背景
· 方法
· 实验分析
· 总结
· 参考文献
1. 摘要
在广告召回场景中,图神经网络(GNN)由于其强大的拓扑特征提取和关系推理能力成为最先进的技术之一。大规模广告召回场景通常包含了数十亿量级的商品和数百亿量级的交互关系,导致传统的基于GNN的召回方法训练效率低。在训练效率的限制下,通常只能应用浅层的图模型算法,这极大限制了图模型的表达能力,从而降低了广告召回的质量。为了提升训练效率以及图模型表达能力,我们提出了解耦式图模型方法(DC-GNN)以改进和加速基于GNN的大规模广告召回。DC-GNN主要包含三个阶段:预训练、深度聚合与双塔CTR预估。具体来说,预训练阶段设计有监督的边预测任务和自监督的图多视野对比学习任务相结合的多任务学习以重点学习图节点属性信息,同时有效增强GNN鲁棒性;深度聚合阶段利用异构线性图算子进一步高效挖掘图深层结构信息来增强图节点的向量化表达;双塔CTR建模阶段将前两个阶段生成的节点向量化表达作为输入,获取预估分数以进行广告召回。DC-GNN通过将双塔CTR预估和图操作进行解耦,使得训练复杂度独立于图结构,有效提升了训练效率。同时,深度聚合阶段允许更深层次的图操作以挖掘高阶图结构信息,从而有效提升了模型的表达能力。大规模工业数据集实验表明,本文所提的DC-GNN方法在大规模广告召回场景下模型性能和训练效率都获得了显著提升。
2. 背景
近年来,在线电商平台在人们的生活中越来越普遍,其通过搜索、广告、推荐等系统来帮助用户从数十亿商品中更好地找到他们所需要的。以淘宝广告系统为例,主流的解决方案通常可以粗略地分为两个阶段:召回阶段、排序阶段。召回阶段负责从数十亿的候选库中挑选一组相关的商品,然后排序阶段对该组相关的商品进行排序并根据机制确定最终的展示位置。在以上两个阶段中,CTR预估均起着重要的作用。不同的是,召回阶段的CTR预估旨在高效地从庞大的候选库中挑选相关商品,排序阶段的CTR预估负责精细化地排序相关商品。在本文中,我们主要关注召回阶段,该阶段的CTR模型通常被设计为双塔结构以高效地检索。
图神经网络(GNN)由于其强大的特征提取和关系推理能力成为电商广告召回最先进的技术之一。GNN的核心是迭代地从邻居节点聚合信息到目标节点,以捕捉图中高阶近邻来缓解数据稀疏问题。传统的基于GNN的大规模广告召回面临两个挑战:
该场景通常包含数十亿量级的商品和数百亿量级的关系,且图操作随着层数的增加复杂度指数增加,庞大的图数据和复杂的图操作导致图模型的训练效率较低;
在训练效率的限制下,只能应用浅层图操作(1~2层),使得目标节点只能获取有限的邻居信息,限制了图模型的表达能力。
为解决以上挑战,本文提出解耦式图模型方法(DC-GNN),将传统的基于GNN的双塔CTR模型解耦为三个阶段:图预训练、深度聚合与双塔CTR预估。每个阶段的主要贡献如下:
图预训练阶段设计多任务学习,即有监督的边预测任务与自监督的图多视野对比学习任务,重点学习图中节点的属性信息,同时增强GNN的鲁棒性;
深度聚合阶段利用异构线性图算子进一步高效挖掘图深层结构信息来增强图节点的向量化表达;
双塔CTR预估阶段将前两个阶段生成的节点向量化表达作为输入,获取预估分数以进行广告召回。
DC-GNN通过将双塔CTR预估和图模型解耦,使得训练复杂度独立于图结构,有效提升了训练效率;在图预训练阶段学习丰富节点属性信息的基础上,深度聚合阶段允许复杂、深层的图操作进一步高效地挖掘图深层结构信息,从而有效提升了图模型的表达能力。我们在大规模工业数据集上的实验表明,DC-GNN在大规模广告召回场景下训练效率和模型性能都获得了显著的提升。
3. 方法
图1展示了DC-GNN的整体框架,主要包含图预训练、深度聚合以及双塔CTR预估三个阶段。
 图1: DC-GNN框架
图1: DC-GNN框架3.1 图预训练
预训练阶段主要关注图节点的属性信息学习。如图1 Stage 1所示,大规模异构图(Main graph)主要包含query、user、ad三种节点,每类节点包含丰富的属性信息,图中的边表示点击行为。考虑到效率性,我们在异构图上以每个节点为目标节点进行三次随机游走(RW),为每个节点产生三个子图(Subgraph)。其中第一个子图用于边预测任务(Link prediction),其余两个子图用于对比学习任务(Contrastive learning)。
3.1.1 边预测任务
边预测任务旨在预测图中两个节点之间是否存在边,如图1中的query和ad。边预测任务的优化目标为:
其中表示余弦相似度函数;和表示一对正样本,即两者在图中存在边;表示第k个负样本。注意我们用点击行为作为图中的边,因此边预测任务的目标与CTR预估阶段在某种程度上是一致的,这意味着我们用CTR预估来引导预训练阶段节点的向量化表达。
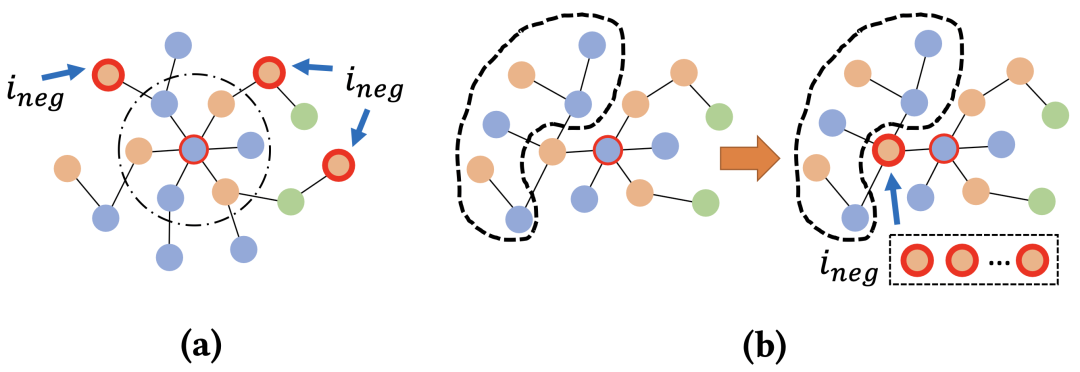 图2: 困难负样本. (a) 可控难度k-hop负样本 (b) 结构负样本
图2: 困难负样本. (a) 可控难度k-hop负样本 (b) 结构负样本如图2所示,为了提升节点向量化表达的质量,并使得GNN更加关注节点属性信息的学习,我们探索了两种类型的困难负样本():
可控难度的k-hop负样本。以中心目标节点为query为例,我们选择其k-hop (k>=2)广告邻居节点ad作为负样本,通过改变参数k则可以改变负样本的难易程度。距离query越近的ad节点更为困难,越远的则越简单。此类负样本忽略图结构,使得GNN可以关注节点属性信息的学习。
结构负样本。仍以目标节点为query为例,保留其正样本ad的邻居结构,并将该ad替换为来自全局负采样的负样本。理论上,结构负样本生成了假子图,但其拓扑结构与真实子图一致,并保留了全局负采样的随机性。因此,在正、负样本相同的图结构情况下,GNN会更关注节点属性信息的学习。同时,由于GNN天然容易过度依赖图结构,此类负样本可以缓解over-smoothing问题。
3.1.2 图对比学习任务
在工业场景下,由于效率的限制,节点向量化表达的更新通常都是以子图形式进行的,子图的生成会引入随机性和干扰。为了提升GNN的鲁棒性,捕获节点的泛化性特征,我们补充了多视野图对比学习任务。如图1 Stage 1所示,以目标节点为query为例,第二个和第三个子图是同一目标节点的两个增强视野,它们被视为正样本对(和),任意不同目标节点的增强视野则被视为负样本对(和)。对比学习损失函数旨在最大化正样本对的agreement,并且最小化负样本对的agreement。目标节点query的优化目标为:
其中,表示图中的query节点。同理,可以获得对于目标节点user和ad的优化目标和。因此,对比学习任务的目标函数为:
最后,利用多任务训练策略来联合优化边预测任务和多视野图对比学习任务,预训练阶段的损失函数为:
其中,表示模型参数,和是用于平衡和正则的超参数。
3.2 深度聚合
深度聚合阶段旨在高效地挖掘图的深层结构信息以进一步增强图节点的向量化表达。如图1 Stage 2所示,对异构图中的每个目标节点生成三类关系子图(Relation subgraphs),以目标节点为query为例,我们可以采样得到其query子图、user子图以及ad子图。假设分别表示关系子图预先计算好的一阶、二阶、三阶以及更高阶的邻接矩阵,用于捕获和保留不同阶近邻的信息。注意区别不同阶近邻的信息是必要的,可以使得图结构得到充分的学习。假设预训练阶段学习到的节点向量化表达为,则第二阶段增强后的节点向量化表达为:
其中,表示深层聚合阶段的节点向量化表达。
异构线性图算子实质上是一种并行前向传播的策略,可以使得计算复杂度与图层数呈线性关系。因此,其在图操作本身上进行了加速,使得深层图结构的挖掘更加高效。除此之外,在最终节点向量化表达中我们保留了节点的局部信息(Locality)来缓解深层图结构学习中可能出现的over-smoothing问题。
3.3 双塔CTR预估
如图1 Stage 3所示,我们构建了双塔CTR模型,其中一个塔为(query, user),另一个塔为ad,前两个阶段生成的节点向量化表达作为CTR的输入,优化目标为:
其中,我们利用(query, user)-ad点击结果当作正样本对(即(q, u)-),展示了但未点击结果当作负样本对(即(q, u)-)。CTR阶段获取预估分数,以进行广告召回。
4. 实验分析
该部分我们选择了部分实验进行展示,更多的结果详见论文。
DC-GNN: Decoupled Graph Neural Networks for Improving and Accelerating Large-Scale E-commerce Retrieval https://www2022.thewebconf.org/PaperFiles/19.pdf
4.1 与SOTA方法的对比
我们利用从淘宝APP收集到的大规模异构图数据作为数据集进行实验。表1所示为DC-GNN与SOTA方法在AUC和Hitrate@K方面的对比,最好的结果加粗显示,次好的结果下划线显示。实验结果表明,在AUC指标上,DC-GNN相比于其他方法获取了最好的效果,这主要是因为DC-GNN在深度聚合阶段挖掘图的深层结构信息以增强模型的表达能力,突破了传统大规模广告召回场景只能应用浅层图模型的瓶颈。另一方面,我们通过Hitrate@K来评估模型性能,DC-GNN与其他方法相比获得了有竞争力的效果,并且随着K的增大,DC-GNN的优势明显扩大,这表明DC-GNN可以显著提高中长尾候选商品的预测结果。
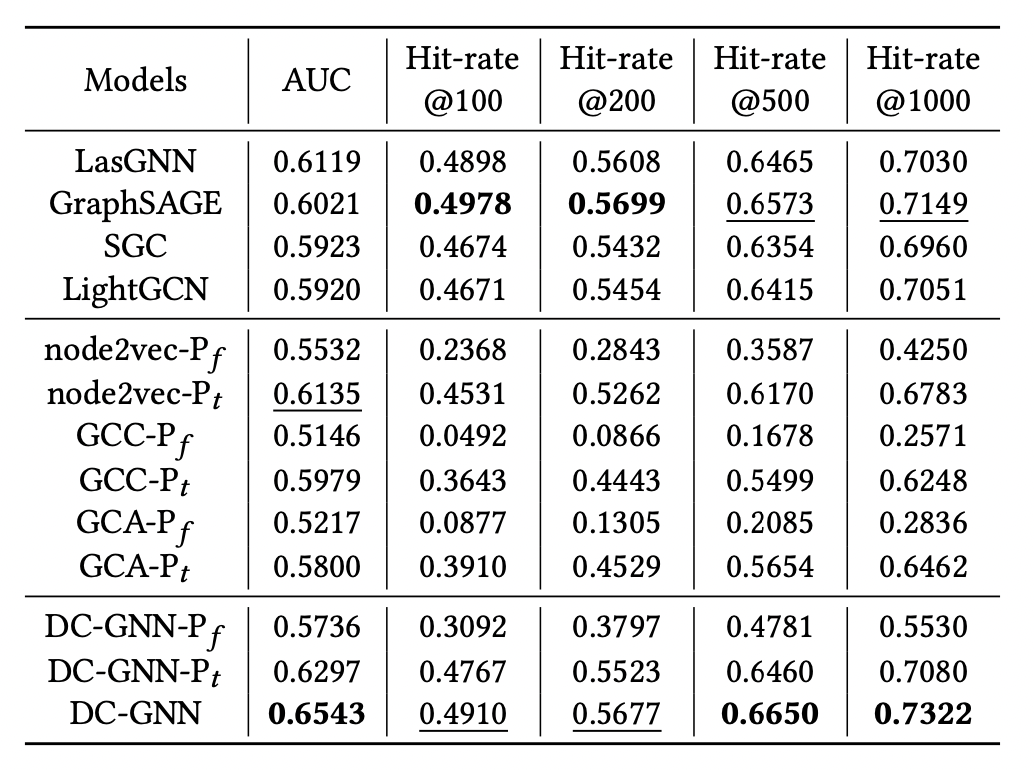 表1: DC-GNN与SOTA方法的性能对比
表1: DC-GNN与SOTA方法的性能对比图3展示了DC-GNN与轻量化图模型在训练效率上的对比。我们将LasGNN方法的训练效率作为基线,并计算其他方法的加速比。实验结果表明,随着GNN层数的增加,基于采样的轻量化图模型方法计算复杂度会急剧上升;基于高效传播的轻量化图模型方法(例如SGC、LightGCN)可以获得更好的训练效率,这归功于它们抛弃了图算子中的线性转换和非线性激活模块。相比之下,DC-GNN由于解耦了CTR预估和图操作,使得训练效率独立于图结构,因此,其可以获得更高的训练效率,且随着图层数的增加,训练效率的提升越明显。
 图3: 训练效率对比
图3: 训练效率对比4.2 对DC-GNN的研究
4.2.1 图预训练
为验证图预训练阶段多任务的效果,我们对比了DC-GNN在只有边预测任务或者只有图对比学习任务下的性能。如表2所示,LP表示模型只被边预测任务优化,CL表示模型只被对比学习任务优化,最好的结果粗体显示。实验结果表明,边预测任务和对比学习任务均对模型效果有正向作用,且两者联合优化时,DC-GNN可以获得最好的结果。
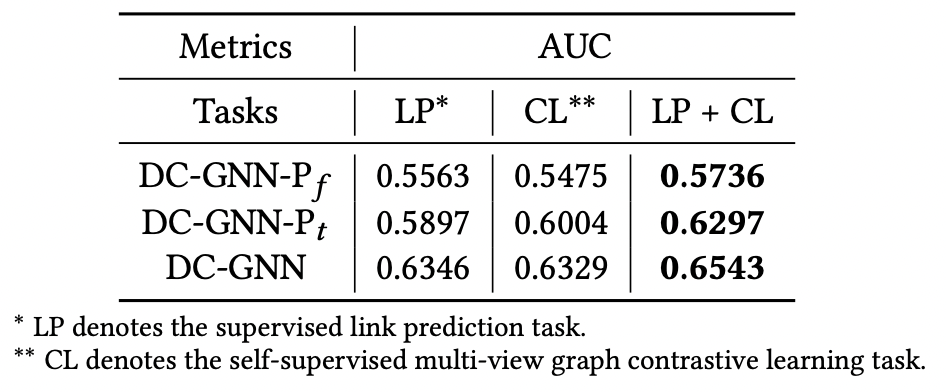 表2: 多任务的效果对比
表2: 多任务的效果对比4.2.2 深度聚合
为了验证深度聚合阶段聚合层数与聚合邻居的影响,我们在聚合层数1~5以及聚合邻居2~10分别进行了实验,实验结果如图4所示。实验结果表明,当聚合层数小于5时,随着聚合层数的增加,模型性能有效增加,此时当聚合层数继续增加时,模型效果趋于平缓;值得注意的是异构线性图算子使得图模型的计算复杂度与层数呈线性关系。当聚合邻居小于6时,随着聚合邻居的逐渐增加,模型性能有效增加,此时当聚合邻居继续增加时,模型效果趋于平缓。考虑到训练效率、网络复杂度以及模型性能,在深度聚合阶段,我们分别采取了4层聚合层数以及5个聚合邻居。
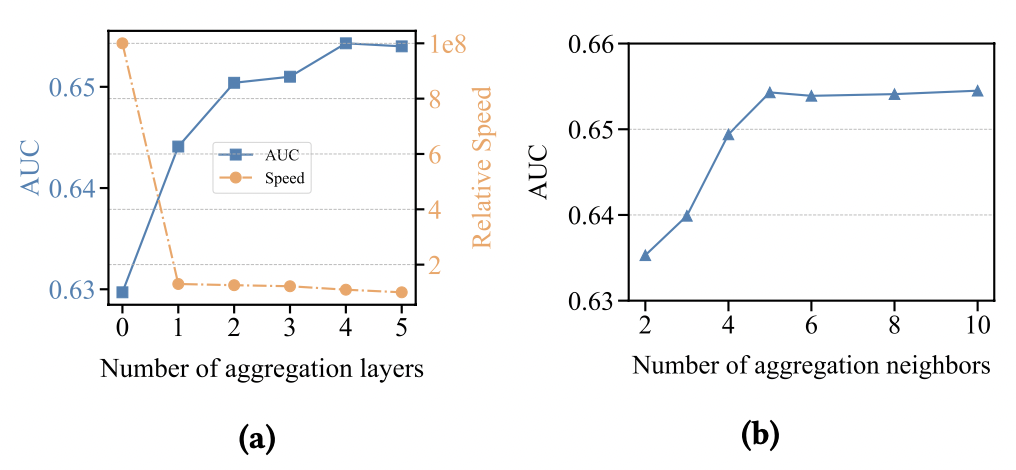 图4: 聚合层数(a)以及聚合邻居(b)对性能的影响
图4: 聚合层数(a)以及聚合邻居(b)对性能的影响5. 总结
本文提出了DC- GNN,将传统的基于GNN的双塔CTR框架解耦为图预训练、深度聚合以及CTR预估三个阶段,以缓解模型性能与训练效率之间的权衡。图预训练阶段通过多任务学习关注节点属性信息的学习,深度聚合通过线性图算子进一步高效地挖掘图深层结构以增强节点向量化表达,双塔CTR以前两个阶段的节点向量化表达为输入,获取预估分数以进行召回。在大规模工业数据集上的实验表明,DC-GNN在训练效率和模型性能上均取得了显著的提升。其中训练效率的提升主要归功于双塔CTR与图模型的解耦,模型性能的提升主要在于预训练阶段节点属性信息的充分学习以及深度聚合阶段深层图结构信息的学习。
该项工作相关内容已发表在 TheWebConf 2022,欢迎阅读交流。
论文:DC-GNN: Decoupled Graph Neural Networks for Improving and Accelerating Large-Scale E-commerce Retrieval
下载:https://www2022.thewebconf.org/PaperFiles/19.pdf
参考文献
[1] Fabrizio Frasca, Emanuele Rossi, Davide Eynard, Ben Chamberlain, Michael Bronstein, and Federico Monti. 2020. Sign: Scalable inception graph neural networks. arXiv preprint arXiv:2004.11198 (2020).
[2] Jiancan Wu, Xiang Wang, Fuli Feng, Xiangnan He, Liang Chen, Jianxun Lian, and Xing Xie. 2021. Self-supervised graph learning for recommendation. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 726–735.
[3] Yanqiao Zhu, Yichen Xu, Feng Yu, Qiang Liu, Shu Wu, and Liang Wang. 2021. Graph contrastive learning with adaptive augmentation. In Proceedings of the Web Conference 2021. 2069–2080.
[4] FanLiu,ZhiyongCheng,LeiZhu,ZanGao,andLiqiangNie.2021.Interest-aware Message-Passing GCN for Recommendation. In Proceedings of the Web Conference 2021. 1296–1305.
END

也许你还想看
丨从二值检索到层次竞买图——让搜索广告关键词召回焕然新生
丨基于生成式回放的流式图神经网络模型
丨图深度学习模型进展和在阿里搜索广告中的应用创新
关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”ღ~
↓欢迎留言参与讨论↓




 京公网安备 11010802041100号
京公网安备 11010802041100号