
CountVectorizer
关于文本特征提取,前面一篇文章TF-IDF介绍了HashingTF,本文将再介绍一种Spark MLlib的API CountVectorizer。
CountVectorizer 和 CountVectorizerModel 旨在帮助将文本文档集合转化为频数向量。当先验词典不可用时,CountVectorizer可以用作Estimator提取词汇表,并生成一个CountVectorizerModel。该模型会基于该字典为文档生成稀疏矩阵,该稀疏矩阵可以传给其它算法,比如LDA,去做一些处理。
在拟合过程中,CountVectorizer会从整个文档集合中进行词频统计并排序后的前vocabSize个单词。
一个可选参数minDF也会影响拟合过程,方法是指定词汇必须出现的文档的最小数量(或小于1.0)。另一个可选的二进制切换参数控制输出向量。如果设置为true,则所有非零计数都设置为1.这对于模拟二进制计数而不是整数计数的离散概率模型特别有用。
举例说明该算法
假如我们有个DataFrame有两列:id和texts。
| id | texts |
| 0 | Array("a", "b", "c") |
| 1 | Array("a", "b", "b", "c", "a") |
每一行texts都是一个Array [String]类型的文档。使用字典(A,B,C)调用CountVectorizer产生CountVectorizerModel。然后转换后的输出列“向量”包含
vector列:
| id | texts | vector |
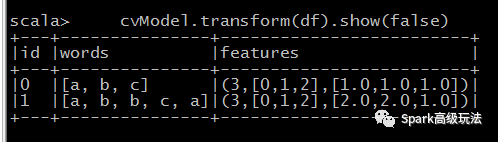
| 0 | Array("a", "b", "c") | (3,[0,1,2],[1.0,1.0,1.0]) |
| 1 | Array("a", "b", "b", "c", "a") | (3,[0,1,2],[2.0,2.0,1.0]) |
将两篇文档中的词去重后就组成了一个字典,这个字典中有3个词:a,b,c,分别建立索引为0,1,2.
在第三列的文档向量,是由基于字典的索引向量,与对应对索引的词频向量所组成的。
文档向量是稀疏的表征,例子中只有3个词可能感觉不出,在实际业务中,字典的长度是上万,而文章中出现的词可能是几百或几千,故很多索引对应的位置词频都是0.
spark中的源码
导包
import org.apache.spark.ml.feature.{CountVectorizer, CountVectorizerModel}
准备数据
val df = spark.createDataFrame(Seq(
(0, Array("a", "b", "c")),
(2, Array("a", "b", "c", "c", "a"))
)).toDF("id", "words")
从全文集中拟合CountVectorizerModel(自动计算字典)
val cvModel: CountVectorizerModel = new CountVectorizer()
.setInputCol("words")
.setOutputCol("features")
.setVocabSize(3)
.setMinDF(2).fit(df)
查看结果
cvModel.transform(df).show(false)
指定预先字典
val cvm = new CountVectorizerModel(Array("a", "b", "c"))
.setInputCol("words").setOutputCol("features")
为了避免重复,重新造一组数据
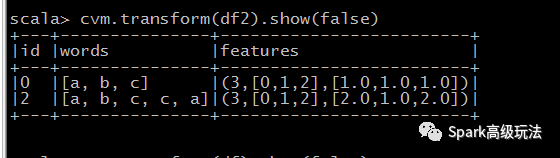
val df = spark.createDataFrame(Seq(
(0, Array("a", "b", "c")),
(2, Array("a", "b", "c", "c", "a"))
)).toDF("id", "words")
查看结果
cvm.transform(df).show(false)
推荐阅读:
1,SparkMLLib中基于DataFrame的TF-IDF
2,基于DF的Tokenizer分词
3,案例:Spark基于用户的协同过滤算法
4,SparkSql的Catalyst之图解简易版

关于Spark高级玩法 kafka,hbase,spark,Flink等入门到深入源码,spark机器学习,大数据安全,大数据运维,请关注浪尖公众号,看高质量文章。

更多文章,敬请期待





 京公网安备 11010802041100号
京公网安备 11010802041100号