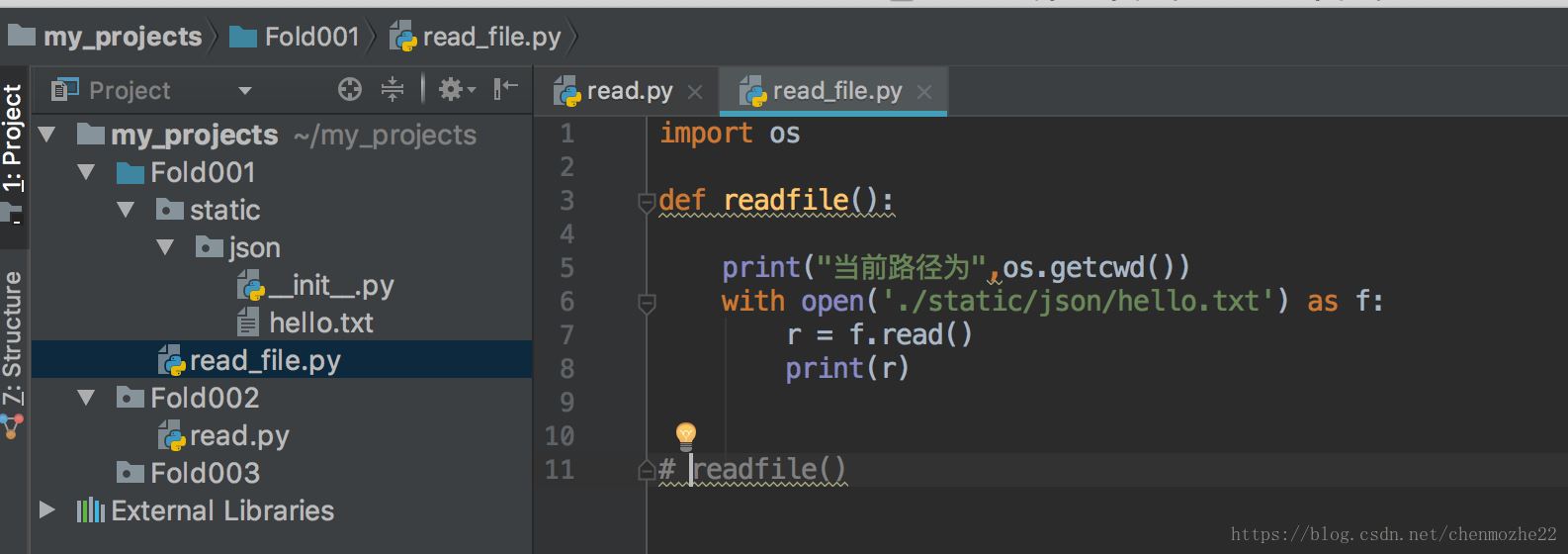
假如一个字符串'ABCDEFGH',要输出下列格式:

即: 每次取出第一个作为首,然后的字符串拆成列表,放置在后面,最后成上面的输出:
一般的处理是:
>>> s = 'ABCDEFGH'
>>> while s:
front, s = s[0], list(s[1:])
print(front, s)
A ['B', 'C', 'D', 'E', 'F', 'G', 'H']
B ['C', 'D', 'E', 'F', 'G', 'H']
C ['D', 'E', 'F', 'G', 'H']
D ['E', 'F', 'G', 'H']
E ['F', 'G', 'H']
F ['G', 'H']
G ['H']
H []
备注:
1.将切片中索引为0的字符赋值给front
2.将切片中索引为1之后字符再赋值给s
3.用list函数将字符串转变为列表
4.用while循环来s来判断,为空,则退出循环
上面的处理,可以用序列解包的方法会来处理,并好理解。 序列解包是Python 3.0之后出现,之前的版本一般赋值的时候,一定要对等,才能正常赋值,比如说:
>>> a, b, c = (1, 2, 3)
>>> a, c
(1, 3)
>>> [a, b, c] = (1, 2, 3)
>>> a, c
(1, 3)
>>> a, b, c = 'SON' # 刚好三个字符的字符串
>>> a, c
('S', 'N')
如果是不对等的情况下,是会报错的: too many values to unpack
>>> a, b = 'SON'
Traceback (most recent call last):
File "", line 1, in
a, b = 'SON'
ValueError: too many values to unpack (expected 2)
3.0出现了解包,一切就简单多了,如果我不之后字符有多少个时候,都可以如此:
>>> a, *b = 'BOOK'
>>> a, b
('B', ['O', 'O', 'K'])
>>> *a, b = 'BOOK'
>>> a, b
(['B', 'O', 'O'], 'K')
上面就是序列解包,在赋值时无疑更方便,适用性更强!运用序列解包的功能重写上面的代码:

从上面可以看出: 代码更简洁,也更好理解了!





 京公网安备 11010802041100号
京公网安备 11010802041100号