在v1版本的MyDisruptor实现单生产者、单消费者功能后。按照计划,v2版本的MyDisruptor需要支持多消费者和允许设置消费者组间的依赖关系。
由于该文属于系列博客的一部分,需要先对之前的博客内容有所了解才能更好地理解本篇博客
package mydisruptor;
import mydisruptor.util.SequenceUtil;
import mydisruptor.waitstrategy.MyWaitStrategy;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.locks.LockSupport;
/**
* 单线程生产者序列器(仿Disruptor.SingleProducerSequencer)
* 只支持单消费者的简易版本(只有一个consumerSequence)
*
* 因为是单线程序列器,因此在设计上就是线程不安全的
* */
public class MySingleProducerSequencer {
/**
* 生产者序列器所属ringBuffer的大小
* */
private final int ringBufferSize;
/**
* 当前已发布的生产者序列号
* (区别于nextValue)
* */
private final MySequence currentProducerSequence = new MySequence();
/**
* 生产者序列器所属ringBuffer的消费者序列集合
* (v2版本简单起见,先不和disruptor一样用数组+unsafe来实现)
* */
private final List
private final MyWaitStrategy myWaitStrategy;
/**
* 当前已申请的序列(但是是否发布了,要看currentProducerSequence)
*
* 单线程生产者内部使用,所以就是普通的long,不考虑并发
* */
private long nextValue = -1;
/**
* 当前已缓存的消费者序列
*
* 单线程生产者内部使用,所以就是普通的long,不考虑并发
* */
private long cachedCOnsumerSequenceValue= -1;
public MySingleProducerSequencer(int ringBufferSize, MyWaitStrategy myWaitStrategy) {
this.ringBufferSize = ringBufferSize;
this.myWaitStrategy = myWaitStrategy;
}
/**
* 一次性申请可用的1个生产者序列号
* */
public long next(){
return next(1);
}
/**
* 一次性申请可用的n个生产者序列号
* */
public long next(int n){
// 申请的下一个生产者位点
long nextProducerSequence = this.nextValue + n;
// 新申请的位点下,生产者恰好超过消费者一圈的环绕临界点序列
long wrapPoint = nextProducerSequence - this.ringBufferSize;
// 获得当前已缓存的消费者位点
long cachedGatingSequence = this.cachedConsumerSequenceValue;
// 消费者位点cachedValue并不是实时获取的(因为在没有超过环绕点一圈时,生产者是可以放心生产的)
// 每次发布都实时获取反而会触发对消费者sequence强一致的读,迫使消费者线程所在的CPU刷新缓存(而这是不需要的)
if(wrapPoint > cachedGatingSequence){
// 比起disruptor省略了if中的cachedGatingSequence > nextProducerSequence逻辑
// 原因请见:https://github.com/LMAX-Exchange/disruptor/issues/76
// 比起disruptor省略了currentProducerSequence.set(nextProducerSequence);
// 原因请见:https://github.com/LMAX-Exchange/disruptor/issues/291
long minSequence;
// 当生产者发现确实当前已经超过了一圈,则必须去读最新的消费者序列了,看看消费者的消费进度是否推进了
// 这里的getMinimumSequence方法中是对volatile变量的读,是实时的、强一致的读
while(wrapPoint > (minSequence = SequenceUtil.getMinimumSequence(nextProducerSequence, gatingConsumerSequenceList))){
// 如果确实超过了一圈,则生产者无法获取可用的队列空间,循环的间歇性park阻塞
LockSupport.parkNanos(1L);
}
// 满足条件了,则缓存获得最新的消费者序列
// 因为不是实时获取消费者序列,可能cachedValue比上一次的值要大很多
// 这种情况下,待到下一次next申请时就可以不用去强一致的读consumerSequence了
this.cachedCOnsumerSequenceValue= minSequence;
}
// 记录本次申请后的,已申请的生产者位点
this.nextValue = nextProducerSequence;
return nextProducerSequence;
}
public void publish(long publishIndex){
// 发布时,更新生产者队列
// lazySet,由于消费者可以批量的拉取数据,所以不必每次发布时都volatile的更新,允许消费者晚一点感知到,这样性能会更好
// 设置写屏障
this.currentProducerSequence.lazySet(publishIndex);
// 发布完成后,唤醒可能阻塞等待的消费者线程
this.myWaitStrategy.signalWhenBlocking();
}
public MySequenceBarrier newBarrier(){
return new MySequenceBarrier(this.currentProducerSequence,this.myWaitStrategy,new ArrayList<>());
}
public MySequenceBarrier newBarrier(MySequence... dependenceSequences){
return new MySequenceBarrier(this.currentProducerSequence,this.myWaitStrategy,new ArrayList<>(Arrays.asList(dependenceSequences)));
}
public void addGatingConsumerSequenceList(MySequence newGatingConsumerSequence){
this.gatingConsumerSequenceList.add(newGatingConsumerSequence);
}
public int getRingBufferSize() {
return ringBufferSize;
}
}
/**
* 序列号工具类
* */
public class SequenceUtil {
/**
* 从依赖的序列集合dependentSequence和申请的最小序列号minimumSequence中获得最小的序列号
* @param minimumSequence 申请的最小序列号
* @param dependentSequenceList 依赖的序列集合
* */
public static long getMinimumSequence(long minimumSequence, List
for (MySequence sequence : dependentSequenceList) {
long value = sequence.get();
minimumSequence = Math.min(minimumSequence, value);
}
return minimumSequence;
}
/**
* 获得传入的序列集合中最小的一个序列号
* @param dependentSequenceList 依赖的序列集合
* */
public static long getMinimumSequence(List
// Long.MAX_VALUE作为上界,即使dependentSequenceList为空,也会返回一个Long.MAX_VALUE作为最小序列号
return getMinimumSequence(Long.MAX_VALUE, dependentSequenceList);
}
}
/**
* 序列栅栏(仿Disruptor.SequenceBarrier)
* */
public class MySequenceBarrier {
private final MySequence currentProducerSequence;
private final MyWaitStrategy myWaitStrategy;
private final List
public MySequenceBarrier(MySequence currentProducerSequence,
MyWaitStrategy myWaitStrategy, List
this.currentProducerSequence = currentProducerSequence;
this.myWaitStrategy = myWaitStrategy;
this.dependentSequencesList = dependentSequencesList;
}
/**
* 获得可用的消费者下标
* */
public long getAvailableConsumeSequence(long currentConsumeSequence) throws InterruptedException {
// v1版本只是简单的调用waitFor,等待其返回即可
return this.myWaitStrategy.waitFor(currentConsumeSequence,currentProducerSequence,dependentSequencesList);
}
}
/**
* 阻塞等待策略
* */
public class MyBlockingWaitStrategy implements MyWaitStrategy{
private final Lock lock = new ReentrantLock();
private final Condition processorNotifyCOndition= lock.newCondition();
@Override
public long waitFor(long currentConsumeSequence, MySequence currentProducerSequence, List
throws InterruptedException {
// 强一致的读生产者序列号
if (currentProducerSequence.get()
lock.lock();
try {
//
while (currentProducerSequence.get()
processorNotifyCondition.await();
}
}
finally {
lock.unlock();
}
}
// 跳出了上面的循环,说明生产者序列已经超过了当前所要消费的位点(currentProducerSequence > currentConsumeSequence)
long availableSequence;
if(!dependentSequences.isEmpty()){
// 受制于屏障中的dependentSequences,用来控制当前消费者消费进度不得超过其所依赖的链路上游的消费者进度
while ((availableSequence = SequenceUtil.getMinimumSequence(dependentSequences))
// 在jdk9开始引入的Thread.onSpinWait方法,优化自旋性能
MyThreadHints.onSpinWait();
}
}else{
// 并不存在依赖的上游消费者,大于当前消费进度的生产者序列就是可用的消费序列
availableSequence = currentProducerSequence.get();
}
return availableSequence;
}
@Override
public void signalWhenBlocking() {
lock.lock();
try {
// signal唤醒所有阻塞在条件变量上的消费者线程(后续支持多消费者时,会改为signalAll)
processorNotifyCondition.signal();
}
finally {
lock.unlock();
}
}
}
在waitFor方法中自旋并不是简单的空循环,而是调用了MyThreadHints.onSpinWait方法。
/**
* 启发性的查询是否存在Thread.onSpinWait方法,如果有则可以调用,如果没有则执行空逻辑
*
* 兼容老版本无该方法的jdk(Thread.onSpinWait是jdk9开始引入的)
* */
public class MyThreadHints {
private static final MethodHandle ON_SPIN_WAIT_METHOD_HANDLE;
static {
final MethodHandles.Lookup lookup = MethodHandles.lookup();
MethodHandle methodHandle = null;
try {
methodHandle = lookup.findStatic(Thread.class, "onSpinWait", methodType(void.class));
} catch (final Exception ignore) {
// jdk9才引入的Thread.onSpinWait, 低版本没找到该方法直接忽略异常即可
}
ON_SPIN_WAIT_METHOD_HANDLE = methodHandle;
}
public static void onSpinWait() {
// Call java.lang.Thread.onSpinWait() on Java SE versions that support it. Do nothing otherwise.
// This should optimize away to either nothing or to an inlining of java.lang.Thread.onSpinWait()
if (null != ON_SPIN_WAIT_METHOD_HANDLE) {
try {
// 如果是高版本jdk找到了Thread.onSpinWait方法,则进行调用, 插入特殊指令优化CPU自旋性能(例如x86架构中的pause汇编指令)
// invokeExact比起反射调用方法要高一些,详细的原因待研究
ON_SPIN_WAIT_METHOD_HANDLE.invokeExact();
}
catch (final Throwable ignore) {
// 异常无需考虑
}
}
}
}
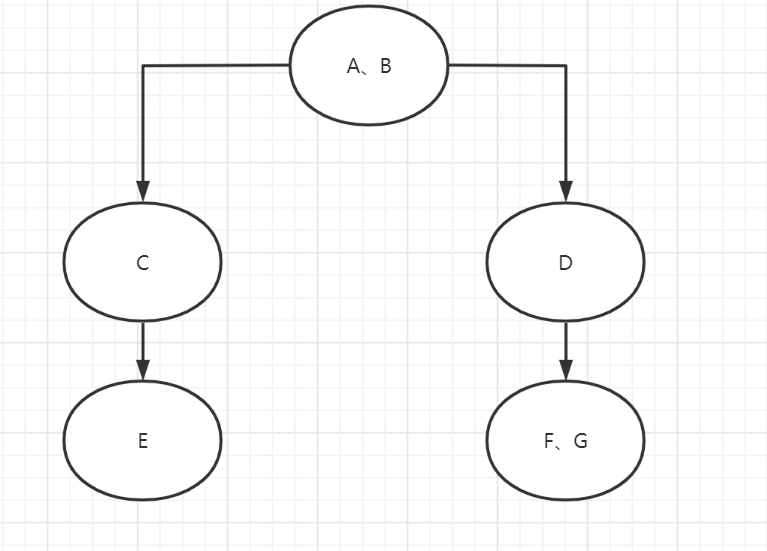
v2版本支持了多生产者和消费者组间消费依赖的功能,下面通过一个稍显复杂的demo来展示如何使用这些功能。
public class MyRingBufferV2Demo {
/**
* 树形依赖关系
* A,B->C->E
* ->D->F,G
* */
public static void main(String[] args) throws InterruptedException {
// 环形队列容量为16(2的4次方)
int ringBufferSize = 16;
// 创建环形队列
MyRingBuffer
new OrderEventProducer(), ringBufferSize, new MyBlockingWaitStrategy());
// 获得ringBuffer的序列屏障(最上游的序列屏障内只维护生产者的序列)
MySequenceBarrier mySequenceBarrier = myRingBuffer.newBarrier();
// ================================== 基于生产者序列屏障,创建消费者A
MyBatchEventProcessor
new MyBatchEventProcessor<>(myRingBuffer, new OrderEventHandlerDemo("consumerA"), mySequenceBarrier);
MySequence cOnsumeSequenceA= eventProcessorA.getCurrentConsumeSequence();
// RingBuffer监听消费者A的序列
myRingBuffer.addGatingConsumerSequenceList(consumeSequenceA);
// ================================== 基于生产者序列屏障,创建消费者B
MyBatchEventProcessor
new MyBatchEventProcessor<>(myRingBuffer, new OrderEventHandlerDemo("consumerB"), mySequenceBarrier);
MySequence cOnsumeSequenceB= eventProcessorB.getCurrentConsumeSequence();
// RingBuffer监听消费者B的序列
myRingBuffer.addGatingConsumerSequenceList(consumeSequenceB);
// ================================== 消费者C依赖上游的消费者A,B,通过消费者A、B的序列号创建序列屏障(构成消费的顺序依赖)
MySequenceBarrier mySequenceBarrierC = myRingBuffer.newBarrier(consumeSequenceA,consumeSequenceB);
// 基于序列屏障,创建消费者C
MyBatchEventProcessor
new MyBatchEventProcessor<>(myRingBuffer, new OrderEventHandlerDemo("consumerC"), mySequenceBarrierC);
MySequence cOnsumeSequenceC= eventProcessorC.getCurrentConsumeSequence();
// RingBuffer监听消费者C的序列
myRingBuffer.addGatingConsumerSequenceList(consumeSequenceC);
// ================================== 消费者E依赖上游的消费者C,通过消费者C的序列号创建序列屏障(构成消费的顺序依赖)
MySequenceBarrier mySequenceBarrierE = myRingBuffer.newBarrier(consumeSequenceC);
// 基于序列屏障,创建消费者E
MyBatchEventProcessor
new MyBatchEventProcessor<>(myRingBuffer, new OrderEventHandlerDemo("consumerE"), mySequenceBarrierE);
MySequence cOnsumeSequenceE= eventProcessorE.getCurrentConsumeSequence();
// RingBuffer监听消费者E的序列
myRingBuffer.addGatingConsumerSequenceList(consumeSequenceE);
// ================================== 消费者D依赖上游的消费者A,B,通过消费者A、B的序列号创建序列屏障(构成消费的顺序依赖)
MySequenceBarrier mySequenceBarrierD = myRingBuffer.newBarrier(consumeSequenceA,consumeSequenceB);
// 基于序列屏障,创建消费者D
MyBatchEventProcessor
new MyBatchEventProcessor<>(myRingBuffer, new OrderEventHandlerDemo("consumerD"), mySequenceBarrierD);
MySequence cOnsumeSequenceD= eventProcessorD.getCurrentConsumeSequence();
// RingBuffer监听消费者D的序列
myRingBuffer.addGatingConsumerSequenceList(consumeSequenceD);
// ================================== 消费者F依赖上游的消费者D,通过消费者D的序列号创建序列屏障(构成消费的顺序依赖)
MySequenceBarrier mySequenceBarrierF = myRingBuffer.newBarrier(consumeSequenceD);
// 基于序列屏障,创建消费者F
MyBatchEventProcessor
new MyBatchEventProcessor<>(myRingBuffer, new OrderEventHandlerDemo("consumerF"), mySequenceBarrierF);
MySequence cOnsumeSequenceF= eventProcessorF.getCurrentConsumeSequence();
// RingBuffer监听消费者F的序列
myRingBuffer.addGatingConsumerSequenceList(consumeSequenceF);
// ================================== 消费者G依赖上游的消费者D,通过消费者D的序列号创建序列屏障(构成消费的顺序依赖)
MySequenceBarrier mySequenceBarrierG = myRingBuffer.newBarrier(consumeSequenceD);
// 基于序列屏障,创建消费者G
MyBatchEventProcessor
new MyBatchEventProcessor<>(myRingBuffer, new OrderEventHandlerDemo("consumerG"), mySequenceBarrierG);
MySequence cOnsumeSequenceG= eventProcessorG.getCurrentConsumeSequence();
// RingBuffer监听消费者G的序列
myRingBuffer.addGatingConsumerSequenceList(consumeSequenceG);
// 启动消费者线程
new Thread(eventProcessorA).start();
new Thread(eventProcessorB).start();
new Thread(eventProcessorC).start();
new Thread(eventProcessorD).start();
new Thread(eventProcessorE).start();
new Thread(eventProcessorF).start();
new Thread(eventProcessorG).start();
// 生产者发布100个事件
for(int i=0; i<100; i++) {
long nextIndex = myRingBuffer.next();
OrderEventModel orderEvent = myRingBuffer.get(nextIndex);
orderEvent.setMessage("message-"+i);
orderEvent.setPrice(i * 10);
System.out.println("生产者发布事件:" + orderEvent);
myRingBuffer.publish(nextIndex);
}
// 简单阻塞下,避免还未消费完主线程退出
Thread.sleep(5000L);
}
}
disruptor无论在整体设计还是最终代码实现上都有很多值得反复琢磨和学习的细节,希望能帮助到对disruptor感兴趣的小伙伴。
本篇博客的完整代码在我的github上:https://github.com/1399852153/MyDisruptor 分支:feature/lab2








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 
