大数据概念
2011年,美国麦肯锡在研究报告《大数据的下一个前沿:创新、竞争和生产力》中定义大数据是指大小超出典型数据库软件工具收集、存储、管理和分析能力的数据集。但是这个定义过于简单,作为对照理解,Gartner研究机构定义的大数据是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。后者“信息量”比较大,突出了以下几点:
由于大数据的定义众说纷纭,我们可以从大数据的5V特征入手,来认识大数据:
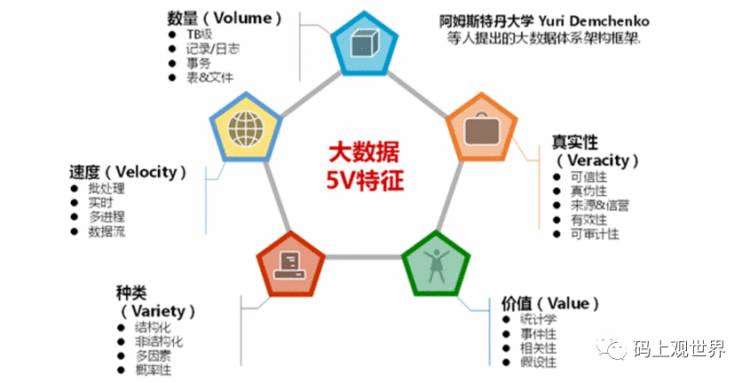
Volume:主要指数据集的规模大,而数据集的类型可以是记录或者日志数据,也可以是在线事务数据,存储形式可以是数据库表或者文件。大数据集通常在TB级别,因为数据量的持续增长,该标准不是固定的,未来还会提高。
Velocity:不仅指数据产生和流动速率快,也指数据处理及时、快速。相比批处理,实时处理在某些场合下是必选方式。
Variety:大数据包括多种不同格式和不同类型的数据。数据来源包括人与系统交互时与机器自动生成,来源的多样性导致数据类型的多样性。根据数据是否具有一定的模式、结构和关系,数据可分为三种基本类型:结构化数据、非结构化数据、半结构化数据。
Veracity:真实性要求大数据来源可信、可追溯、可审计,否则大数据将失去可用价值。
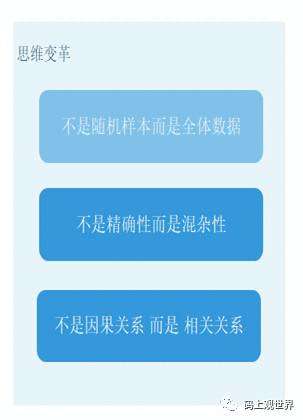
Value:数据价值密度相对较低,数据蕴含的价值并没有随着数量或者时间同比例增长。大数据的价值更多体现在统计意义和相关性上,因此对于该特征要求我们进行思维变革才能理解大数据的价值:
关于大数据的应用可以追溯到19世纪末美国人口普查,大数据的发展大致划分为如下图所示的4各阶段:萌芽期、成长期、普及期和爆发期。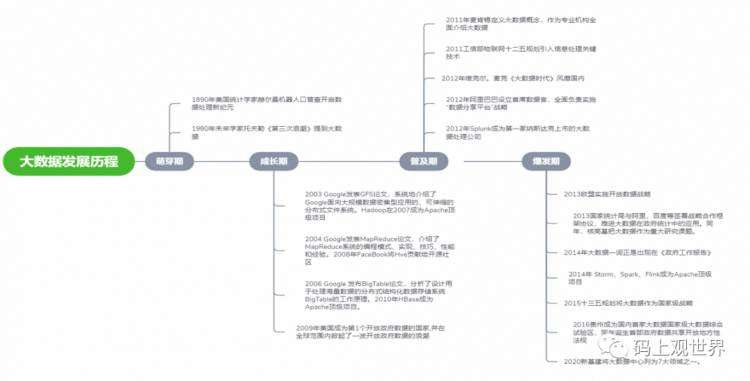
为了更进一步了解大数据在实践中的落地应用,这里列举几种身边的大数据案例:
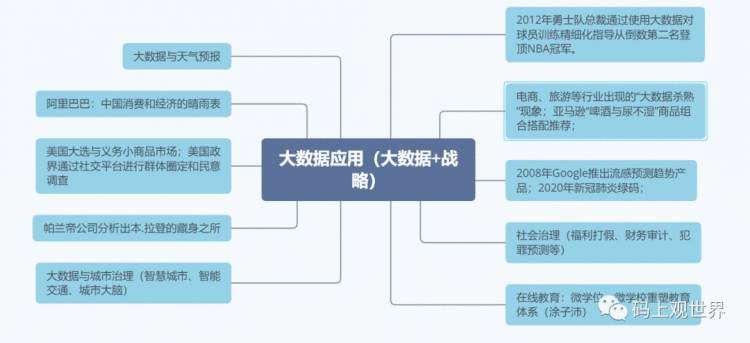
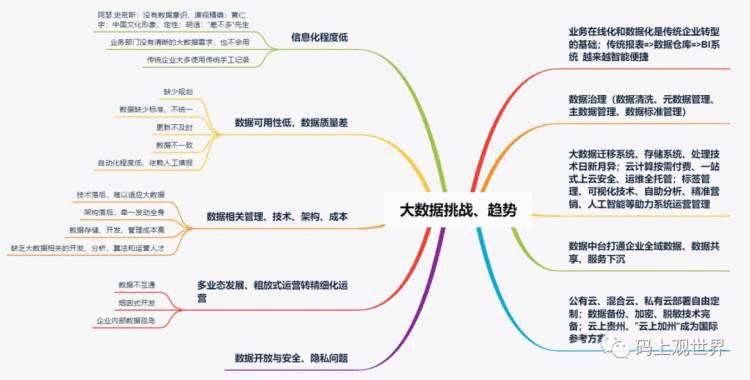
从上图中可知大数据在很多年前,很多方面都有很成熟的应用:比如天气预报、经济预测、政治选举、反恐、智慧城市、体育训练、电子商务、疾病防控、社会治理和教育等。正如互联网可以加一切行业一样,大数据同样可以加一切行业,而且比互联网应用范围更广、更深入。但大数据落地,特别是在传统行业尤其面临很多挑战,同时也是机遇,比如:
信息化程度低:造成这种问题的根源在于认知,著名历史学家黄仁宇对比中美文化指出中国文化形象是定性而不是定量,其次才是没有数据积累和大数据相关的技术。
数据质量:表现为数据标准不统一、缺少规范、数据不一致,导致数据不可用。
数据管理、技术、架构、成本:表现为管理、技术落后、架构复杂导致系统升级成本高。
运营转型:随着大数据在电商等领域应用成熟,领域也拓展到核心业务周边领域,相应的运营策略逐渐从粗犷运营转向跨领域、精细化运营,原有的“烟囱”开发模式无法满足膨胀增长的数据需求。
数据安全:突出表现在对用户隐私信息的收集和利用上,对跨国企业还面临着不同文化导致的国家层面政治安全的博弈问题。
大数据架构案例
时至今日,大数据在各家互联网公司已经相对完善,架构和应用模式基本确定,下面列举几家企业案例,从技术产品架构角度看看各家企业在大数据方面的建设和应用实践。
网易大数据平台
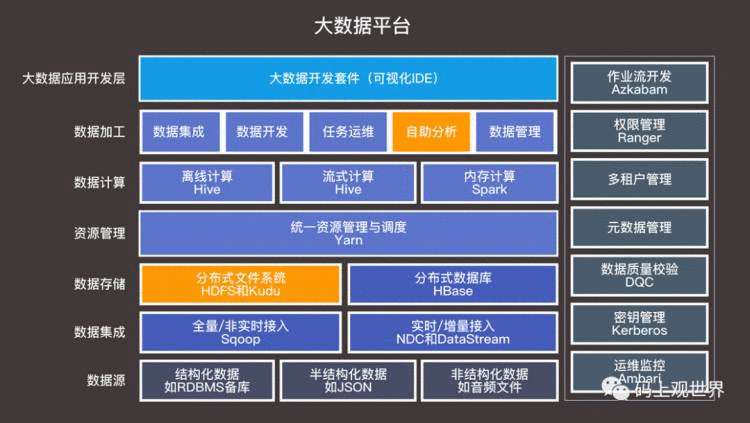
猛犸大数据平台是网易大数据平台产品的代表,从上述架构图中,可以看到其基于开源的作业流调度系统Azkaban,实现了对不同数据源的实时和非实时的收集、存储和计算。使用的技术基于常规的、开源的大数据如Hive、Spark、Hbase和Yarn,只不过是在它们基础上包装成易于使用的开发套件,如数据集成、数据开发、任务运维、自助分析和数据管理等,此外还包括必要的功能如元数据管理、数据质量管理等。由于开源技术的蓬勃发展和普遍使用,基于自建集群之上独立部署大数据平台是各类企业普遍采用的方式,不足之处是投入成本巨大,不仅包括硬件还包括运维、开发等。
阿里巴巴大数据平台
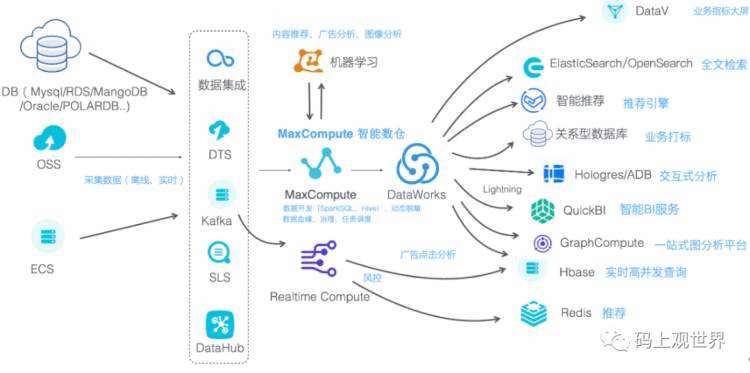
阿里巴巴作为云上大数据平台基础技术设施的提供者,更强调技术的性能、稳定性和自主性,比如为了支持更大规模的数据处理集群,一站式的数据存储和计算服务平台MaxCompute取代了Hadoop,成为云上数据仓库的技术基础。MaxCompute跟DataWorks等产品紧密结合,实现更为完整的解决方案,比如DataWorks为MaxCompute提供一站式的数据同步、业务流程设计、数据开发、管理和运维等功能。
另外云上数据来源多样,比如数据库DB,外部文件系统OSS或者服务器日志ECS,数据传输可以使用阿里云数据传输产品DTS,也可以通过日志收集工具投递到Kafka或者DataHub,这些构成云上大数据平台的基础底座,由于其具备的弹性扩容带来的免运维特性给传统的大数据平台带来不小的冲击,尤其是技术能力薄弱的中小企业,企业上云成为明智选择。
亚马逊大数据平台
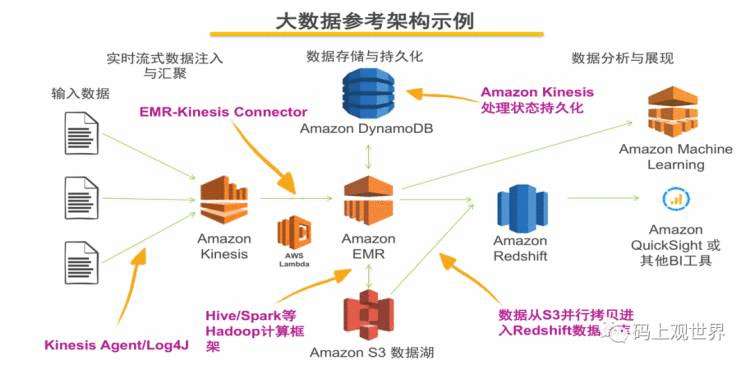
作为云计算的鼻祖,亚马逊原则上不提供具体的大数据平台架构,只提供推荐参考架构,但具体的产品组件功能异常丰富和完善。上图中Amazon EMR作为架构的核心,提供弹性大数据存储和计算服务,EMR是一套产品的组合,包括常见的开源技术如Hadoop、Hive、Spark、HBase、Flink等,用户在开启集群的时候可以自由定制所使用的产品组合、版本以及分配服务器的数量、规格和扩容策略等。值得一提的是Amazon基于对象存储S3和独立的元数据中心Glue实现了计算和存储分离,用一套数据存储、多种计算引擎,互不干涉,为分布式架构提升到新的高度。在这种架构模式之下,实现数据湖变得异常容易,参考下图示意:
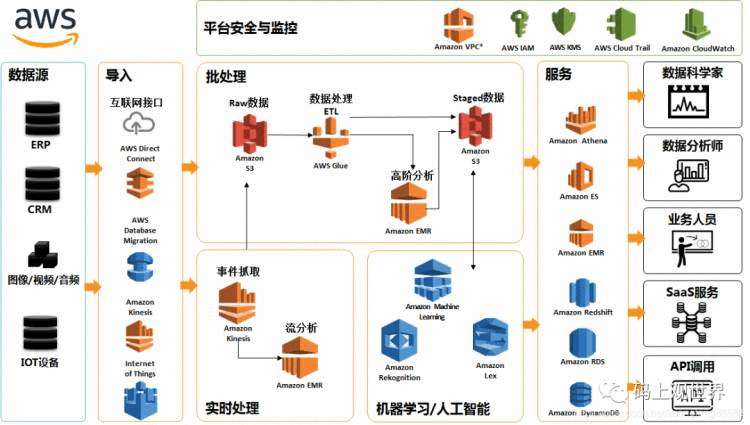
其中基于无服务部署的Athena数据分析服务可以让客户完全忽略底层的服务架构,只专注于业务分析,带来了相比EMR更为强大、便利的体验。
大数据中台
如果把大数据平台看做技术的沉淀,那么数据中台就可以看做数据和业务的沉淀:
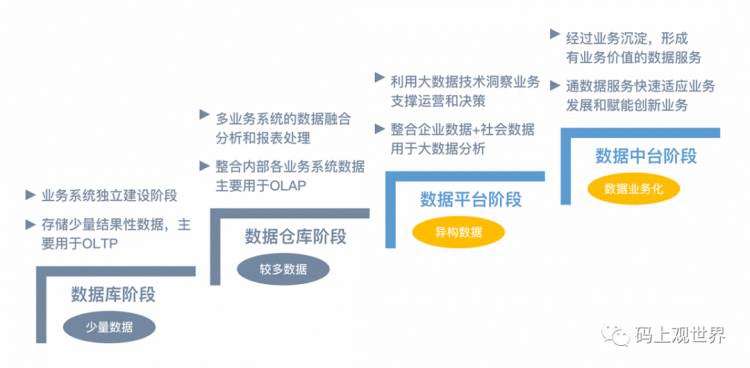
从图中数据中台的发展路径,可知数据中台的产生不是凭空出现:只有当技术和业务积累到一定阶段才可能出现,过早搭建数据中台只会阻碍业务的进步。为了解释中台是什么,先看下中台有什么优势:

在二战时期,美军是以庞大的军队为单位作战;到了越战时,以营为单位作战;到了中东战斗的时候,以7人或者11人的极小班排去作战,这就是今天具备最强核心竞争力和打击能力的组织。而美军之所以能灵活作战,敢放这么小的团队到前方,是因为有非常强的中台能力,这些能力包括战斗直升机、舰炮远程支援、战术导弹系统、战斗机支援体系等,这些能力能支持小团队快速做判断,并且引领整个炮火覆盖和定点清除。“⼤平台炮火支撑精兵作战”是“大”中台、“小”前台战略的具体应用。在IT领域,中台可以抽象为企业级的能力复用平台,中台除了我们熟知的数据中台还有技术中台、业务中台等,详见下图:
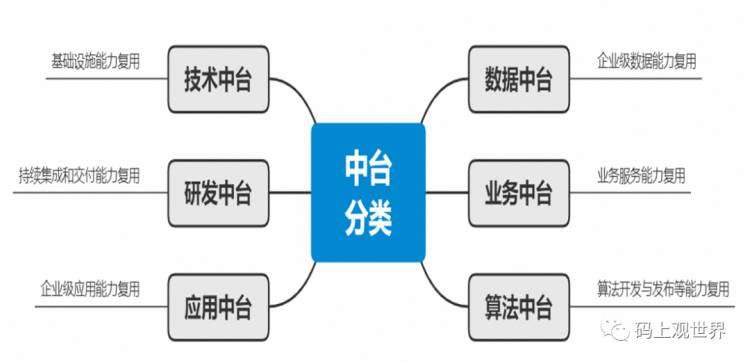
大数据中台概念在国内风靡一时,国外目前所知甚少,基本是跟数据平台合在一起。其中数据中台和业务中台是数字中台的主要形式,两者相辅相成,相互促进,依托于技术中台,这三者关系为:
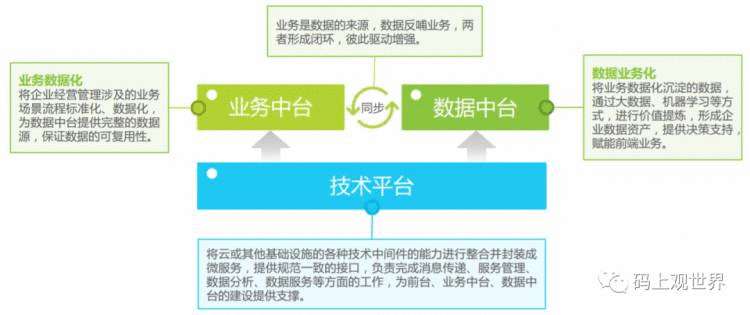
数据中台从后台及业务中台将数据汇入,进行数据的共享融合、组织处理、建模分析、管理治理和服务应用,统一数据标 准口径,以API的方式提供服务,是综合性数据能力平台。数据中台为前台业务部门提供决策快速响应、精细化运营及应 用支撑等,让数据业务化,避免“数据孤岛”的出现,提升业务效率,更好地驱动业务发展和创新。典型的数据中台架构和数据处理流程可表示如下:
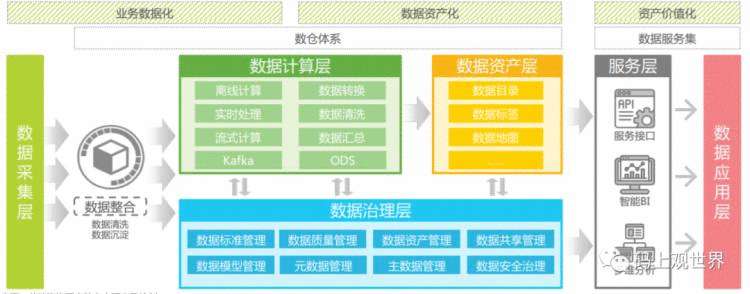
大数据中台实践案例
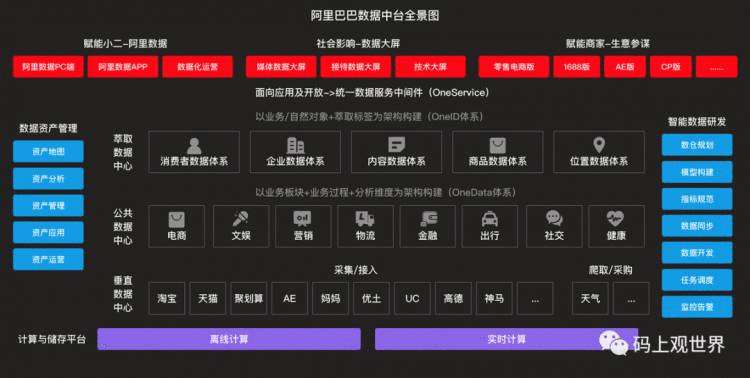
阿里巴巴数据中台
作为国内大数据中台的引领者,阿里巴巴通过OneId、OneData、OneService打通实体、数据和服务,解决自身数据孤岛问题。
数澜科技数据中台
数澜科技作为国内数据中台,面向行业解决方案的重要提供者,以数据资产为核心,形成数据汇聚和开发、数据体系和数据服务体系,为客户提供标准化、系统化的中台架构。
网易数据中台
以网易为代表的企业在跟随中台引领者提供的中台建设理念和思路,结合企业实际搭建满足企业需求的数据中台。
数据中台实施
数据中台建设方法论
数据中台是集方法论、工具、组织于一体的“快”、“准”、“全”、“统”、“通”的智能大数据体系。核心内容包括数据中台方法论、工具、组织。
首先,在方法论层面要有全局观统领,单独谈局部的技术、系统或结构,都不能实现真正的数据中台建设;
其次,必须将思想产品化,形成一个真正普适性的工具或产品;
第三,数据中台的建设不是一个数据系统项目,而是组织文化的变革,是真正把数据变为资产的一种变革。
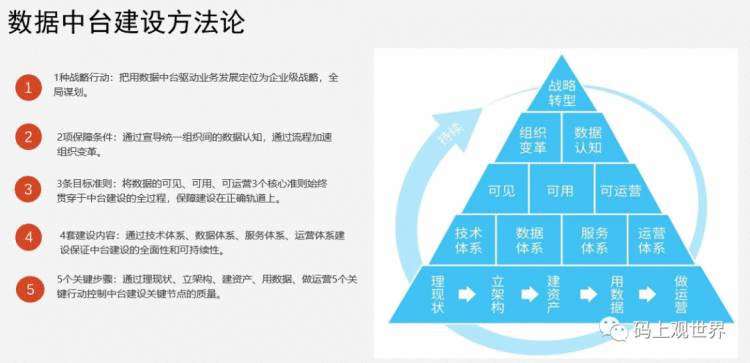
数据中台实施路径
第一阶段:全局架构与初始化。
基于智能大数据解决方案,配置和部署数据中台相关产品,同时全局架构数据中台,以便后续逐步做厚;
基于数据中台全局架构,从数据向上、从业务向下同步思考,初始化数据采集、数据公共层建设,并初始化最关键的数据应用层建设;
结合业务思考,直接解决业务看数据、用数据的最关键且最易感知的若干场景应用。
第二阶段:迭代数据中台深化应用。
迭代调优数据中台全局架构,加配合完善数据中台相关产品套件;
迭代调优数据中台的初始化数据汇集、数据公共层和数据应用层,持续推进数据公共层的丰富完善,并平衡数据应用层建设;
深入业务思考,优化场景应用,拓展场景应用。
第三阶段:全面推进业务数据化。
持续基于业务的数据中台建设;
全面推进业务数据化,不断优化、拓展应用场景。
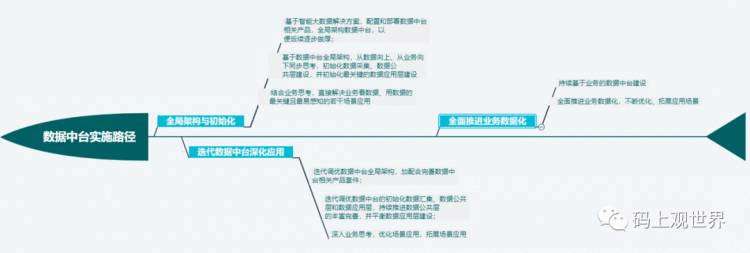
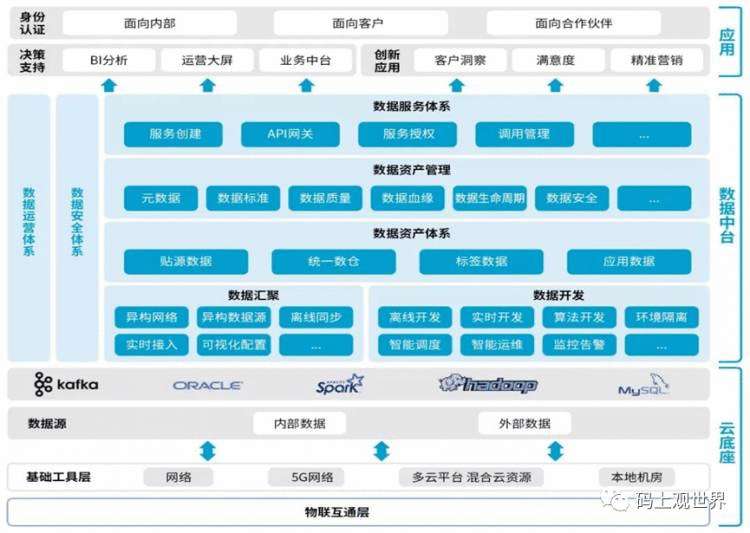
数据中台架构
数据中台系统架构
数据中台由大数据平台及传统数据仓库两部分构成:

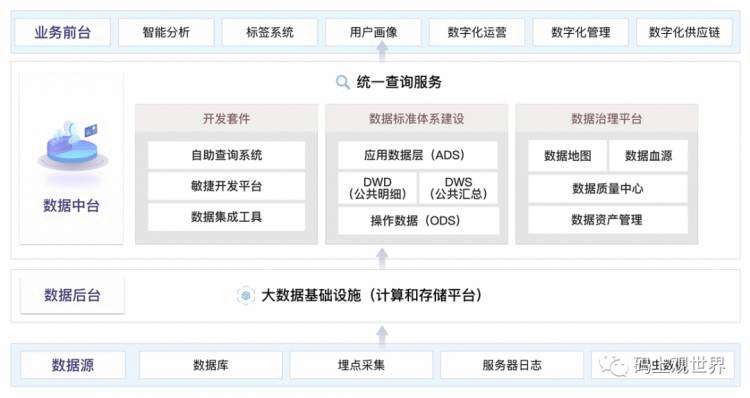
大数据平台通过外部工具汇集结构化、半结构化或者非结构化数据进入分布式集群,如HDFS,计算引擎如Hive、Spark等基于资源调度管理实现对集群数据处理。数据仓库从业务系统中批量或者实时采集数据,按照分层设计实现数据建模,各层次示意图如下:
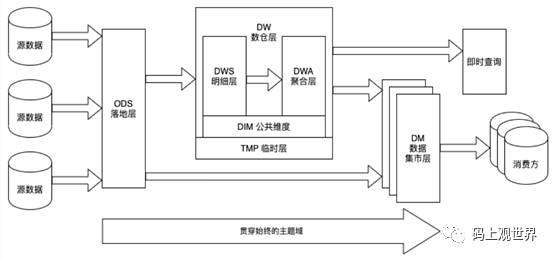
数据仓库对外以Table或者View对外暴露数据访问接口,用户通过仪表盘、报表或者通过SQL语句等跟数据仓库交互,实现企业决策分析基本功能。
大数据平台计算结果数据可以反馈存储到数据仓库,形成结构化规范数据表,同样也可以读取数据仓库数据进行深度价值挖掘,结果以内表或者外表形式对外暴露访问接口。
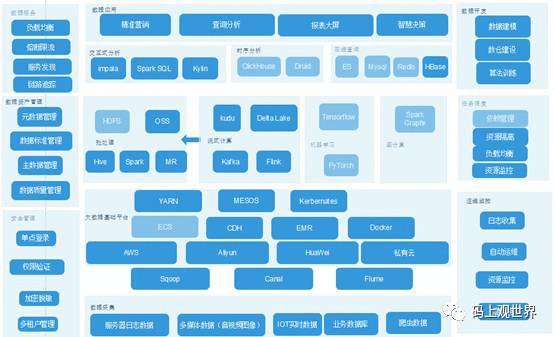
上述数据中台系统架构从技术视角可以展示为下图所示:功能模块可以划分为数据采集、数据计算、数据存储、数据治理和数据服务,这些构成数据中台的核心职能。

数据中台技术架构
数据中台技术架构是逻辑架构的物理映射,是结合公司现状和技术栈等因素落地的产物,因此脱离实际谈技术架构是无意义的,但是提供必要的技术结构说明是必要的,因此本文综合各种场景,尽量给出相对通用的架构。
数据中台基本职能包括数据服务、数据资产管理、安全管理、运维监控、任务调度和数据开发。数据处理流程主要包括数据采集、数据存储和计算、查询和应用。其中数据采集来源于全域数据,包括服务器日志、多媒体数据、IOT实时数据、业务数据库数据比如MySQL,Oracle,SQL Server等,以及网络爬虫来源的数据等。
数据存储架构可以基于公有云如AWS、Aliyun、Huawei云,也可以基于私有云部署。大数据组件的运维部署可以基于开源的CDH,也可以采用AWS或者aliyun的EMR。在服务器的选择上可以基于阿里云的弹性服务器ECS,同样也可以选择虚拟化Docker部署。在资源管理调度上同样可以选择YARN、Mesos或者Kerbernates。
在数据计算方面支持批处理和实时处理,另外也支持图计算和机器学习。
在数据查询方面,为了支持不同类型数据规模和特征,将数据分析引擎大致分为3类:交互式分析、时序分析和在线查询引擎。其中交互式分析主要选择有Impala、Spark SQL和Kylin。时序分析主要面向物联网大量数据的访问,可以选择的引擎为Druid和ClickHouse。在线查询主要面向热数据访问,引擎可以选择Mysql、Redis、Elastic Search和HBase等 。
参考
中国数字中台行业研究报告 艾瑞咨询 2019
阿里云金融行业数据中台报告 2020
数据资产管理实践白皮书 中国信通院 4.0
<<数据中台&#xff1a;让数据用起来>>








 京公网安备 11010802041100号
京公网安备 11010802041100号