大型的预训练模型,比如ELMo、GPT、Bert等提高了NLP任务的最新技术。这些预训练模型在NLP的成功驱动了多模态预训练模型,比如ViBERT、VideoBERT(他们从双模式数据,比如语言-图像对中进行自监督学习)
CodeBERT,是一种用于编程语言(PL)和自然语言(NL)的bimodal预训练模型。CodeBERT捕获自然语言和编程语言的语义连接,生成能广泛支持NL-PL理解任务(自然语言代码搜索)和生成任务(代码文档生成)的通用表示形式。
为了利用NL-PL pairs bimodal 实例和大量可用的uni-modal 代码,训练CodeBERT时用一个混合目标函数(包含标准掩码语言模型和 replaced token detection)
在BERT中,句子内15%的token被选中,其中80%被[MASK]替换,10%被随机替换,10%保持不变,随后将替换后的句子输入到BERT中用于预测那些被替换的token。
论文作者认为BERT只学习这15%的token有点浪费算力,还存在[MASK]不会在实际任务中出现的问题。于是,文章提出了一个新的预训练任务:replaced token detection,即首先使用一个生成器预测句中被mask掉的token,接下来使用预测的token替代句中的[MASK]标记,然后使用一个判别器区分句中的每个token是原始的还是替换后的。
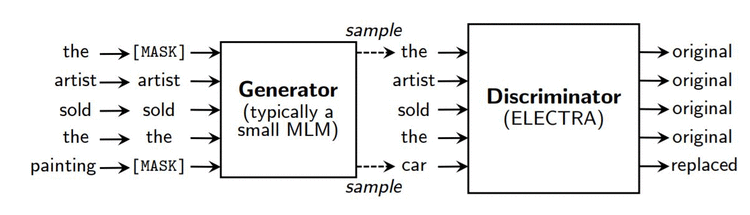
在预训练后,将判别器用于用于下游任务。作者认为replaced token detection任务让模型(判别器)可以在所有的token上学习,而不是那些仅仅被mask掉的token,这使得计算效率更高。
遵循 BERT 和 RoBERTa ,并使用了多层双向 Transformer 作为 CodeBERT 的模型架构。通过使用与Roberta-Base完全相同的模型架构来开发Codebert。模型参数的总数为125M。
RoBERTa:
与BERT相比主要有以下几点改进:
另外,RoBERTa在训练方法上有以下改进:
在预训练阶段,将输入设置为两个序列与特殊token的串联
[
C
L
S
]
,
w
1
,
w
1
,
w
2
,
.
.
.
,
w
n
,
[
S
E
P
]
,
c
1
,
c
2
,
.
.
.
,
c
m
,
[
E
O
S
]
[CLS] ,w_{1},w_{1},w_{2},...,w_{n},[SEP],c_{1},c_{2},...,c_{m},[EOS]
[CLS],w1,w1,w2,...,wn,[SEP],c1,c2,...,cm,[EOS],其中一个序列是自然语言文本,另一个是编程语言。
[
C
L
S
]
[CLS]
[CLS]是两个部分前面的特殊token,其最终隐藏代表被视为分类或排名的汇总序列表示形式。
按照transformers中处理文本的标准方式,将自然语言文本看作一系列单词,把它分为WordPiece。把一块代码视为一系列tokens。
输出包括:
训练CodeBERT模型并行使用单峰数据和双峰数据,双峰数据就是NL-PL对,单峰数据就是单一的自然语言文本,或者是单一的代码。
数据来自公开可用的开源非fork github存储库,并用一组约束和规则过滤。
两个训练目标:
给定NL-PL pair(
X
=
w
,
c
X = {w,c}
X=w,c)的数据点作为输入,其中
w
w
w是NL单词的序列,
c
c
c是PL tokens的序列,我们首先选择NL和PL的随机位置集要掩盖(分别为
m
w
m^{w}
mw和
m
c
m^{c}
mc),然后用特殊的[MASK] token替换所选位置。其中x中15%的token被mask掉。然后预测被mask掉的原始token。
在我们的情况下对其进行调整,并在训练中同时使用双峰和单峰数据。具体而言,有两个数据生成器,一个NL,一个PL,均用于为一组随机掩盖的位置生成合理的替代方案。
判别器被训练检测一个单词是否是原始的单词,这是一个二分类问题。值得注意的是,RTD适用于输入的每个位置,如果生成器生成的单词恰好是原来真实的单词,则标签为 real 而不是 fake

NL和Code生成器都是语言模型,它们基于周围的上下文环境生成了被掩盖位置的合理的token,NL-Code Discriminator是目标的预训练模型,该模型通过检测从NL和PL生成器采样的合理的可替代方案来训练。NL-Code 判别器用于在微调阶段产生通用的表示。NL和Code生成器在微调阶段被抛出。
有不同的设置可以在下游NL-PL任务中使用Codebert。例如,在自然语言代码搜索中,我们将输入与预训练阶段相同,并使用[CLS]的表示来测量代码和自然语言查询之间的语义相关性,而在代码到文本中生成,我们使用编码 - 解码器框架,并使用Codebert初始化生成模型的编码器。
从头开始预训练RoBERTa模型的步骤:
核心代码在\transformers\models\roberta\tokenization_roberta.py
核心代码在\transformers\models\roberta\modeling_roberta.py。
MLM任务:
class RobertaLMHead(nn.Module):
"""Roberta Head for masked language modeling."""
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.layer_norm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.decoder = nn.Linear(config.hidden_size, config.vocab_size)
self.bias = nn.Parameter(torch.zeros(config.vocab_size))
self.decoder.bias = self.bias
def forward(self, features, **kwargs):
x = self.dense(features)
x = gelu(x)
x = self.layer_norm(x)
# project back to size of vocabulary with bias
x = self.decoder(x)
return x
class RobertaForMaskedLM(RobertaPreTrainedModel):
_keys_to_ignore_on_save = [r"lm_head.decoder.weight", r"lm_head.decoder.bias"]
_keys_to_ignore_on_load_missing = [r"position_ids", r"lm_head.decoder.weight", r"lm_head.decoder.bias"]
_keys_to_ignore_on_load_unexpected = [r"pooler"]
def __init__(self, config):
super().__init__(config)
if config.is_decoder:
logger.warning(
"If you want to use `RobertaForMaskedLM` make sure `config.is_decoder=False` for "
"bi-directional self-attention."
)
self.roberta = RobertaModel(config, add_pooling_layer=False)
self.lm_head = RobertaLMHead(config)
# The LM head weights require special treatment only when they are tied with the word embeddings
self.update_keys_to_ignore(config, ["lm_head.decoder.weight"])
# Initialize weights and apply final processing
self.post_init()
def get_output_embeddings(self):
return self.lm_head.decoder
def set_output_embeddings(self, new_embeddings):
self.lm_head.decoder = new_embeddings
@add_start_docstrings_to_model_forward(ROBERTA_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
processor_class=_TOKENIZER_FOR_DOC,
checkpoint=_CHECKPOINT_FOR_DOC,
output_type=MaskedLMOutput,
config_class=_CONFIG_FOR_DOC,
mask="
expected_output="' Paris'",
expected_loss=0.1,
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor], MaskedLMOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the masked language modeling loss. Indices should be in `[-100, 0, ...,
config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are ignored (masked), the
loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`
kwargs (`Dict[str, any]`, optional, defaults to *{}*):
Used to hide legacy arguments that have been deprecated.
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.roberta(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
prediction_scores = self.lm_head(sequence_output)
masked_lm_loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
masked_lm_loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
if not return_dict:
output = (prediction_scores,) + outputs[2:]
return ((masked_lm_loss,) + output) if masked_lm_loss is not None else output
return MaskedLMOutput(
loss=masked_lm_loss,
logits=prediction_scores,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有