在使用ClickHouse当中,相信大家都遇到过各种各样的报错信息,难道从入门到放弃? 下面我将常见的报错总结,供大家参考排查问题。
1.1 问题再现
Memory limit (for query) exceeded:would use 9.37 GiB (attempt to allocate chunk of 301989888 bytes), maximum: 9.31 GiB
1.2 分析问题
默认情况下,ClickHouse会限制了SQL的查询内存使用的上线,当内存使用量大于该值的时候,查询被强制KILL。
1.3 解决问题
对于常规的如下简单的SQL, 查询的空间复杂度为O(1) 。
select count(1) from table where column1=xxx;
对于group by, order by , count distinct这样的复杂的SQL,查询的空间复杂度就不是O(1)了,需要使用大量的内存。
如果是group by内存不够,推荐配置上max_bytes_before_external_group_by参数,当使用内存到达该阈值,进行磁盘group by。推荐配置为max_memory_usage的一半。
如果是order by内存不够,推荐配置上max_bytes_before_external_sort参数,当使用内存到达该阈值,进行磁盘order by。
如果是count distinct内存不够,推荐使用一些预估函数(如果业务场景允许),这样不仅可以减少内存的使用同时还会提示查询速度。
2.1 问题再现
↑ Progress: 157.94 million rows, 6.91 GB (92.63 thousand rows/s., 4.05 MB/s.) Received exception from server (version 19.4.0):
Code: 319. DB::Exception: Received from 10.0.0.50:9000. DB::Exception: Unknown status, client must retry. Reason: Connection loss.
↖ Progress: 94.47 million rows, 4.18 GB (95.07 thousand rows/s., 4.20 MB/s.) Received exception from server (version 19.4.0):
Code: 999. DB::Exception: Received from 10.0.0.50:9000. DB::Exception: Cannot allocate block number in ZooKeeper: Coordination::Exception: Connection loss.
lineorder_flat_all.Distributed.DirectoryMonitor: Code: 225, e.displayText() = DB::Exception: Received from ambari02:9000, 10.0.0.52. DB::Exception: ZooKeeper session has been expired.. Stack trace:
2.2 分析问题
根据报错信息可知,是因为与Zookeeper的连接丢失导致不能分配块号等问题。因为clickhouse对zookeeper的依赖非常的重,表的元数据信息,每个数据块的信息,每次插入的时候,数据同步的时候,都需要和zookeeper进行交互。zookeerper 服务在同步日志过程中,会导致ZK无法响应外部请求,进而引发session过期等问题。- 加大zookeeper会话最大超时时间,在zoo.cfg 中修改MaxSessiOnTimeout=120000,修改后重启zookeeper。
注意:zookeeper的超时时间不要设置太大,在服务挂掉的情况下,会反映很慢。 - zookeeper的snapshot文件存储盘不低于1T,注意清理策略
- 在zookeeper中将dataLogDir存放目录应该与dataDir分开,可单独采用一套存储设备来存放ZK日志。
- 在ZOO.CFG中增加:forceSync=no。默认是开启的,为避免同步延迟问题,ZK接收到数据后会立刻去将当前状态信息同步到磁盘日志文件中,同步完成后才会应答。将此项关闭后,客户端连接可以得到快速响应。关闭forceSync选项后,会存在潜在风险,虽然依旧会刷磁盘(log.flush()首先被执行),但因为操作系统为提高写磁盘效率,会先写缓存,当机器异常后,可能导致一些zk状态信息没有同步到磁盘,从而带来ZK前后信息不一样问题。
- 建表的时候添加use_minimalistic_part_header_in_zookeeper参数,对元数据进行压缩存储,但是修改完了以后无法再回滚的哦。
3.1 问题再现
lineorder_flat_all.Distributed.DirectoryMonitor: Code: 242, e.displayText() = DB::Exception: Received from ambari04:9000, 10.0.0.54. DB::Exception: Table is in readonly mode. Stack trace:
3.2 分析问题
因为zookeeper集群出问题(例如zk服务挂了)导致的压力太大,表处于“read only mode”模式,导致插入失败。
3.3 解决问题
4.1 问题再现
Cannot create table from metadata file /var/lib/clickhouse/metadata/xx/xxx.sql, error: Coordination::Exception: Can’t get data for node /clickhouse/tables/xx/cluster_xxx-01/xxxx/metadata: node doesn’t exist (No node), stack trace:
4.2 分析问题
因为zookeeper数据丢失,从而使clickhouse数据库无法启动。
- 将/var/lib/clickhouse/metadata/ 下的SQL与/var/lib/clickhouse/data/ 下的数据备份之后删除;
- 将之前分布式表的数据文件夹复制到新表的数据目录中;
- insert into [分布式表] select * from [MergeTree表]。
5.1 问题再现
DB::NetException: Connection reset by peer, while reading from socket xxx
5.2 分析问题
查询过程中clickhouse-server进程挂掉。
排查发现在这个异常抛出的时间点有出现clickhouse-server的重启,通过监控系统看到机器的内存使用在该时间点出现高峰,在初期集群"裸奔"的时期,很多内存参数都没有进行限制,导致clickhouse-server内存使用量太高被OS KILL掉。max_memory_usage_for_all_queries该参数没有正确设置是导致该case触发的主要原因。An error occured before execution: Code: 371, e.displayText() = DB::Exception: Table 'test01' isn't replicated, but shard #1 is replicated according to its cluster definition (version 19.14.6.12)
只有使用了replicated开头的engine的引擎的表, 才能够在拥有on cluster xxx条件的ddl语句中进行集群更新;其他engine的表, 只能够每个node进行update;distributed_table使用的是Distributed引擎, 所以也不支持on cluster xxx这样条件的ddl语句。7.1 问题再现
zookeeper的snapshot文件太大,follower从leader同步文件时超时
7.2 分析问题
上面有说过clickhouse对zookeeper的依赖非常的重,表的元数据信息,每个数据块的信息,每次插入的时候,数据同步的时候,都需要和zookeeper进行交互,上面存储的数据非常的多。
7.3 解决问题
zookeeper的snapshot文件存储盘不低于1T,注意清理策略,不然磁盘报警报到你怀疑人生,如果磁盘爆了那集群就处于“残废”状态;
zookeeper集群的znode最好能在400w以下;
建表的时候添加use_minimalistic_part_header_in_zookeeper参数。
8.1 问题再现
Too many parts(304). Merges are processing significantly slower than inserts
8.2 分析问题
因为MergeTree的merge的速度跟不上目录生成的速度, 数据目录越来越多就会抛出这个异常, 所以一般情况下遇到这个异常,降低一下插入频次就ok了,单纯调整background_pool_size的大小是治标不治本的。
8.3 解决问题
详情请点击:ClickHouse新功能之WAL
9.1 问题再现
ClickHouse exception, code: 48, host: 172.16.8.84, port: 8123; Code: 48, e.displayText() = DB::Exception: There was an error on [172.16.8.84:9000]: Cannot execute replicated DDL query on leader (version 19.14.6.12)
9.2 分析问题
这个问题我自己没有弄明白, 查了非常多的资料, 各执一词。在20.4及以后版本的一个pr修复了相关的问题。
- 如果不支持升级CH版本, 我尝试在低版本上为每个分片加了一个副本也将这个问题解决了(原先的架构是无副本的)。
10.1 问题再现

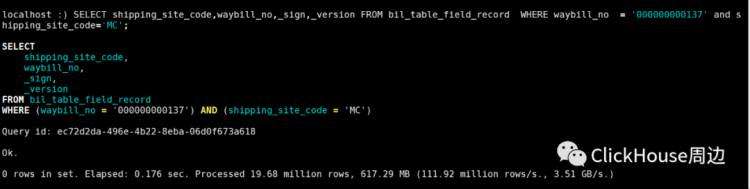
这个问题我自己也没有弄明白, 显示是数据查询0 rows。官方文档解释如下SELECT query from MaterializeMySQL tables has some specifics:
If _version is not specified in the SELECT query, FINAL modifier is used. So only rows with MAX(_version) are selected.
If _sign is not specified in the SELECT query, WHERE _sign=1 is used by default. So the deleted rows are not included into the result set.
以上报错信息,有更多见解的大佬,欢迎私信。
上一篇:ClickHouse 之 Server Settings
近期推荐文章:
ClickHouse优化典藏
CllickHouse 部署架构和国内大厂应用实践
ClickHouse (MATERIALIZED) VIEW
更多精彩内容欢迎关注微信公众号






 京公网安备 11010802041100号
京公网安备 11010802041100号