作者:php辉子 | 来源:互联网 | 2023-08-17 17:07
原标题:词义分析和词义消歧Synsets(“synonymsets”,effectivelysenses)arethebasicunitoforganizatio
原标题:词义分析和词义消歧
Synsets(“synonym sets”, effectively senses) are the basic unit of organization in WordNet.同义词集
对于许多应用程序,我们希望消除歧义
• 我们可能只对一种含义感兴趣
• 在网络上搜索chemical plant 化工厂,我们不想搜到香蕉中的化学物质
所以词义消歧任务是给定一个词,找到给定的含义上下文。并且对于一些热门话题,data driven 方法表现良好。
给定上下文中的一个词和潜在词义的固定清单,能够确定这是哪个词义
WSD 任务的两种变体
词汇样本任务 Lexical Sample task
• 预选的小目标词集(线条、植物)
• 以及每个词的意义清单
• 监督机器学习:为每个词训练分类器
全词任务 All-words task
• 一个词中的每个词整个文本
•文章来源地址19064.html 每个单词都有含义的词典
• 数据稀疏:无法训练特定单词的分类器
评估方法:
外部:作为信息检索、问答或机器翻译系统的一部分进行测试
内在:根据黄金标准感官,评估分类准确性或精确度/召回率
Baseline:选择出现次数最频繁的sense
语义分析的方法
Lexicon-based 基于词典
分为二元和gradable,后者使用情绪范围而不是二元系统来处理诸如absolutely, utterly, completely, totally, nearly, virtually, essentially,
mainly, almost
否定规则Negation rule:
• E.g: “I am not good today”.
Emotion(good)= +3; “not” is detected in neighbourhood (of 5 words around); so emotional valence of “good” is decreased by 1 and sign is
inverted → Emotion(good) = −2
强化规则Intensifier rule:
• 需要一系列强化词:“绝对”、“非常”、“极度”等。
• 每个强化词都有一个权重,例如权重(非常)=1; Weight(extremely)=2
• 权重被加到积极的术语上
• 权重被从消极的术语中减去
• E.g.: “I am feeling very good”.
Emotion(good)= +3; emotional valence of “good” increased by 1 → Emotion(good) = +4
• E.g. “This was an extremely boring game”文章来源地址19064.html
Emotion(boring)=−3; emotional valence of “boring” decreased by −2 → Emotion(boring) = −5
减量规则Diminisher rule:
• 需要一个列表:“有点”、“勉强”、“很少”等。
• 每个强化词都有一个权重
• 从正面词中减去权重
• 将权重加到否定词上
• E.g.: “I am somewhat good”.
Emotion(good)= +3; emotional valence of “good” decreased by 1 → Emotion(good) = +2
• E.g. “This was a slightly boriwww.yii666.comng game”
Emotion(boring)=−3; emotional valence of “boring” increased by 1 → Emotion(boring) = −2
优点:
• 有效处理不同的文本:论坛、博客等。
• 独立于语言——只要有最新的情感词词典可用
• 不需要训练数据
• 可以使用额外的词典进行扩展,例如对于流行的新情感词/符号,尤其是。在社交媒体上
缺点:
• 需要情感词的词典,应该相当全面,涵盖生词、缩写词(LOL、m8 等)、拼写错误的词等。
corpus-based 基于语料库
构建n-gram,类似信息检索的语料预处理
两个步骤:
1 主观性分类器:首先运行二元分类器以识别然后消除目标片段
2 具有剩余片段的情感分类器:学习如何组合和加权不同的属性以进行预测。例如。朴素贝叶斯
词义消歧的方法
基于字典的方法
Lesk’s Algorithm (1986),使用字典条目执行消歧
1.提取上下文词(仅内容词)
2.与不同含义的字典定义/示例进行比较
3 .选择最匹配的含义
监督机器学习
一个训练语料库,在语境中标记了它们的意义,用于训练可以在新文本中标记单词的分类器
所以需要:
• 标记集(意义清单)
• 训练语料库
• 从训练语料库中提取的一组特征
• 分类www.yii666.com器
两种特征向量:
Collocational features
• 关于目标词附近特定位置的词的搭配特征
• 通常仅限于单词身份和词性
bag-of-words features
• 关于出现在窗口中任何地方的词的词袋特征(无论位置如何)
• 通常仅限于频率计数
输入:
• 文本窗口 d 中的单词 w(我们称之为文档)
• 一组固定的类 C = {c1, c2, …, cJ }
• 再次训练一组 m 个手工标记的文本窗口称为文档 (d1, c1), …, (dm, cm)
输出:
• 学习分类器 : d → c
词性相似度
单词相似度:同义词或可以在上下文中粗略地替换另一个 • car 类似于自行车
单词相关性:单词之间的一组更大的关系 • car 与 gasoline 相关
两种求词性相似度的算法
基于词库:使用本体,例如 WordNet
分布方法:通过查看词在大型语料库中的分布情况
计算词性相似度的方法:
Thesaurus-based: using an ontology such as WordNet
Thesaurus-based method: Path length
Distributional methods: by looking at how words are distributed in a large corpus
基于词库的方法
WordNet 具有图形结构。该图中两个同义词集之间的路径长度可以用作它们之间相似性的度量。通常路径来自上位关系或 A is-a B 关系
pathlen(c1,c2) = 节点 c1 和 c2 之间图中最短路径中的边数
计算两个词的所有意义对之间的相似度并取最大值
这可能产生的问题:可能不是每种语言都有同义词库 ,即使我们有,许多单词和短语也会丢失。因此,也有无需昂贵资源即可计算相似度的方法
一些老生常谈的计算

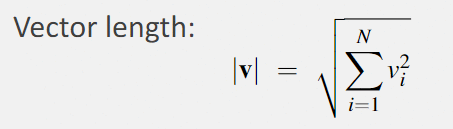
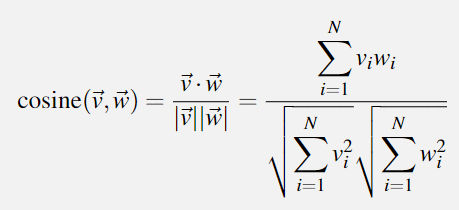

term frequency (tf): count(t,d)
document frequency (df文章来源站点https://www.yii666.com/) 是文档 t 出现的数量
inverse document frequency (idf) = log (N/df) N 是集合中文档的总数


PMI 的范围从 −∞ 到 +∞ ,但负值是有问题的, 因此我们只需将负 PMI 值替换为 0 。也就是ppmi
来源于:词义分析和词义消歧


![[c++基础]STL](https://img.php1.cn/3c972/1edc8/c5a/a04ecc977fd8ed28.jpeg)



 京公网安备 11010802041100号
京公网安备 11010802041100号