磁盘iops 测试 fio 及报错解释
I/O输入/输出(Input/Output),读和写,提高缓存(cache)和做磁盘阵列(RAID)能提高存储IO性能。
IOPS (英文:Input/Output Operations Per Second),即每秒进行读写(I/O)操作的次数,多用于数据库、存储等场合,衡量随机访问的性能。
存储端的IOPS性能和主机端的IO是不同的,IOPS是指存储每秒可接受多少次主机发出的访问,主机的一次IO需要三次访问存储才可以完成。例如,主机写入一个最小的数据块,也要经过"发送写入请求、写入数据、收到写入确认"等三个步骤,也就是3个存储端访问。
Linux下常用Fio、dd工具, Windows下常用IOMeter。
FIO是测试IOPS的非常好的工具,用来对硬件进行压力测试和验证,支持13种不同的I/O引擎,包括:sync,mmap, libaio, posixaio, SG v3, splice, null, network, syslet, guasi, solarisaio 等等。
注意:不要对有数据的磁盘或者分区做测试,会破坏已存在的数据
FIO 官网地址:http://freshmeat.net/projects/fio/
一,FIO安装
下载源码包: wget http://brick.kernel.dk/snaps/fio-2.0.7.tar.gz
安装依赖软件:yum install libaio-devel 我们一般使用libaio,发起异步IO请求。
解压: tar -zxvf fio-2.0.7.tar.gz
安装: cd fio-2.0.7
编译: make
安装: make install
二、FIO用法: 也可以多个任务时可以写在job file里面
下面用命令直接输出的方法:
随机读的测试命令:
fio -filename=/dev/sdb1 -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=4k -size=50G -numjobs=10 -runtime=1000 -group_reporting -name=mytest
说明:
filename=/dev/sdb1 测试文件名称,通常选择需要测试的盘的data目录。 只能是分区,不能是目录,会破坏数据。
direct=1 测试过程绕过机器自带的buffer。使测试结果更真实。
iodepth 1 队列深度,只有使用libaio时才有意义,这是一个可以影响IOPS的参数,通常情况下为1。
rw=randwrite 测试随机写的I/O
rw=randrw 测试随机写和读的I/O
ioengine=psync io引擎使用pync方式
bs=4k 单次io的块文件大小为4k
bsrange=512-2048 同上,提定数据块的大小范围
size=50G 本次的测试文件大小为50g,以每次4k的io进行测试,此大小不能超过filename的大小,否则会报错。
numjobs=10 本次的测试线程为10.
runtime=1000 测试时间为1000秒,如果不写则一直将5g文件分4k每次写完为止。
rwmixwrite=30 在混合读写的模式下,写占30%
group_reporting 关于显示结果的,汇总每个进程的信息。
此外
lockmem=1g 只使用1g内存进行测试。
zero_buffers 用0初始化系统buffer。
nrfiles=8 每个进程生成文件的数量。
read 顺序读
write 顺序写
rw,readwrite 顺序混合读写
randwrite 随机写
randread 随机读
randrw 随机混合读写
顺序读:
fio -filename=/dev/sdb1 -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=4k -size=50G -numjobs=30 -runtime=1000 -group_reporting -name=mytest
随机写:
fio -filename=/dev/sdb1 -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=4k -size=50G -numjobs=30 -runtime=1000 -group_reporting -name=mytest
顺序写:
fio -filename=/dev/sdb1 -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=4k -size=50G -numjobs=30 -runtime=1000 -group_reporting -name=mytest
混合随机读写:
fio -filename=/dev/sdb1 -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=4k -size=50G -numjobs=30 -runtime=100 -group_reporting -name=mytest -ioscheduler=noop
三,实际测试范例:
先前在虚拟机上做的实验:因为size过大,超过实际大小,机器重启后报错,起不起来了。
[root@localhost ~]# fio -filename=/dev/sdb1 -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=16k -size=200G -numjobs=30 -runtime=100 -group_reporting -name=mytest1 //因为200G,超过了/dev/sdb1的大小,所以机器重启后,报错起不了。
mytest1: (g=0): rw=randrw, bs=16K-16K/16K-16K, ioengine=psync, iodepth=1
…
mytest1: (g=0): rw=randrw, bs=16K-16K/16K-16K, ioengine=psync, iodepth=1
fio 2.0.7
Starting 30 threads
Jobs: 1 (f=1): [________________m_____________] [3.5% done] [6935K/3116K /s] [423 /190 iops] [eta 48m:20s] s]
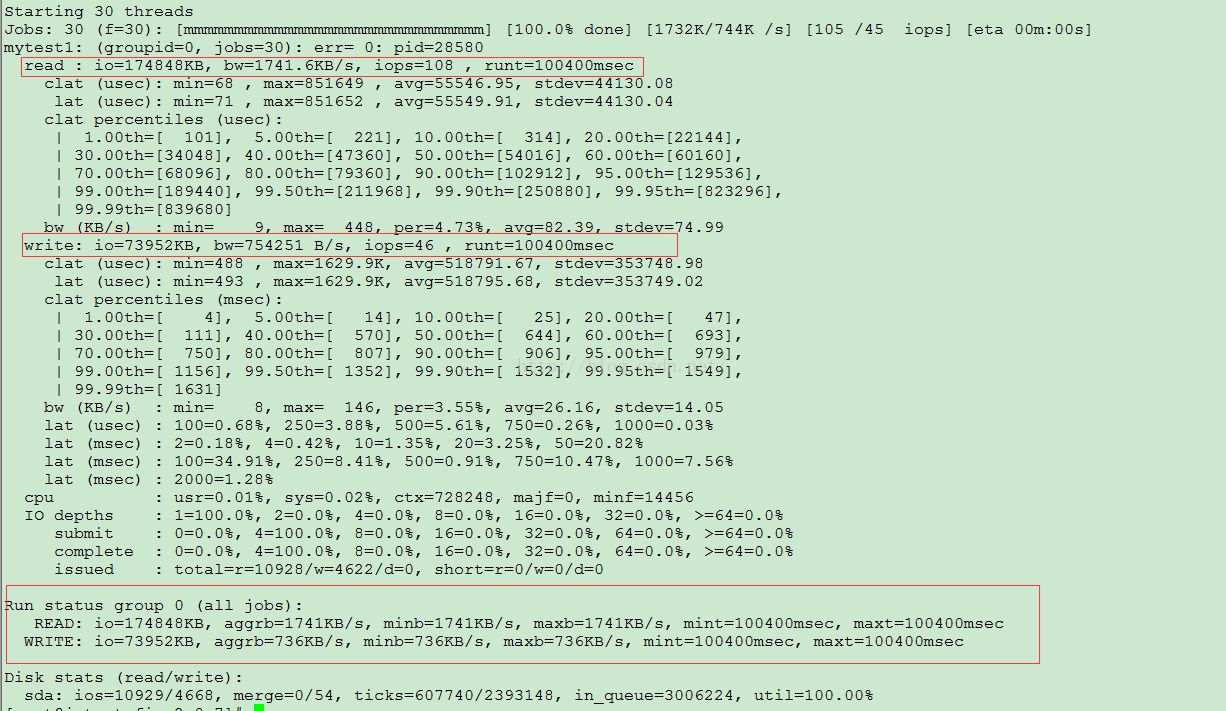
mytest1: (groupid=0, jobs=30): err= 0: pid=23802 // iops:磁盘的每秒读写次数,这个是随机读写考察的重点
read : io=1853.4MB, bw=18967KB/s, iops=1185 , runt=100058msec //bw:磁盘的吞吐量,这个是顺序读写考察的重点,类似于下载速度
clat (usec): min=60 , max=871116 , avg=25227.91, stdev=31653.46 //avg每个IO请求的平均相应时间25秒左右
lat (usec): min=60 , max=871117 , avg=25228.08, stdev=31653.46
clat percentiles (msec):
| 1.00th=[ 3], 5.00th=[ 5], 10.00th=[ 6], 20.00th=[ 8],
| 30.00th=[ 10], 40.00th=[ 12], 50.00th=[ 15], 60.00th=[ 19],
| 70.00th=[ 26], 80.00th=[ 37], 90.00th=[ 57], 95.00th=[ 79],
| 99.00th=[ 151], 99.50th=[ 202], 99.90th=[ 338], 99.95th=[ 383], // %99.95的IO请求的响应时间是小于等于383msec
| 99.99th=[ 523]
bw (KB/s) : min= 26, max= 1944, per=3.36%, avg=636.84, stdev=189.15
write: io=803600KB, bw=8031.4KB/s, iops=501 , runt=100058msec
clat (usec): min=52 , max=9302 , avg=146.25, stdev=299.17
lat (usec): min=52 , max=9303 , avg=147.19, stdev=299.17
clat percentiles (usec):
| 1.00th=[ 62], 5.00th=[ 65], 10.00th=[ 68], 20.00th=[ 74],
| 30.00th=[ 84], 40.00th=[ 87], 50.00th=[ 89], 60.00th=[ 90],
| 70.00th=[ 92], 80.00th=[ 97], 90.00th=[ 120], 95.00th=[ 370],
| 99.00th=[ 1688], 99.50th=[ 2128], 99.90th=[ 3088], 99.95th=[ 3696],
| 99.99th=[ 5216]
bw (KB/s) : min= 20, max= 1117, per=3.37%, avg=270.27, stdev=133.27
lat (usec) : 100=24.32%, 250=3.83%, 500=0.33%, 750=0.28%, 1000=0.27%
lat (msec) : 2=0.64%, 4=3.08%, 10=20.67%, 20=19.90%, 50=17.91%
lat (msec) : 100=6.87%, 250=1.70%, 500=0.19%, 750=0.01%, 1000=0.01%
cpu : usr=1.70%, sys=2.41%, ctx=5237835, majf=0, minf=6344162
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued : total=r=118612/w=50225/d=0, short=r=0/w=0/d=0
Run status group 0 (all jobs):
READ: io=1853.4MB, aggrb=18966KB/s, minb=18966KB/s, maxb=18966KB/s, mint=100058msec, maxt=100058msec
WRITE: io=803600KB, aggrb=8031KB/s, minb=8031KB/s, maxb=8031KB/s, mint=100058msec, maxt=100058msec
Disk stats (read/write):
sdb: ios=118610/50224, merge=0/0, ticks=2991317/6860, in_queue=2998169, util=99.77% //利用率达到99.77%
主要查看以上红色字体部分的iops
bw:磁盘的吞吐量,这个是顺序读写考察的重点,类似于下载速度。
iops:磁盘的每秒读写次数,这个是随机读写考察的重点
io总的输入输出量
runt:总运行时间
lat (msec):延迟(毫秒)
msec: 毫秒
usec: 微秒
如下图使用配置文件来执行测试iops:
在fio命令行进行这些设置时的操作如下,在当前目录下会生成读写用的文件,因此要在可以写入的目录下执行。
$ fio --name=global --direct=1 --name=read --rw=read --size=10m --name=write --rw=randwrite --size=5m
与上述命令行选项具有相同意义的配置文件如下所示。
# cat fio_exam.fio //文件名
[global]
direct=1
[readjob]
size=10m
rw=read
[writejob]
size=5m
rw=randwrite
使用这个配置文件执行fio命令如下。
$ fio simple_read.fio
如上是使用配置文件来执行的。
自己机器的结果: 以为测试时size=200G 磁盘只有30G 导致机器跪了
报错:因为测试路径不是分区路径,报错
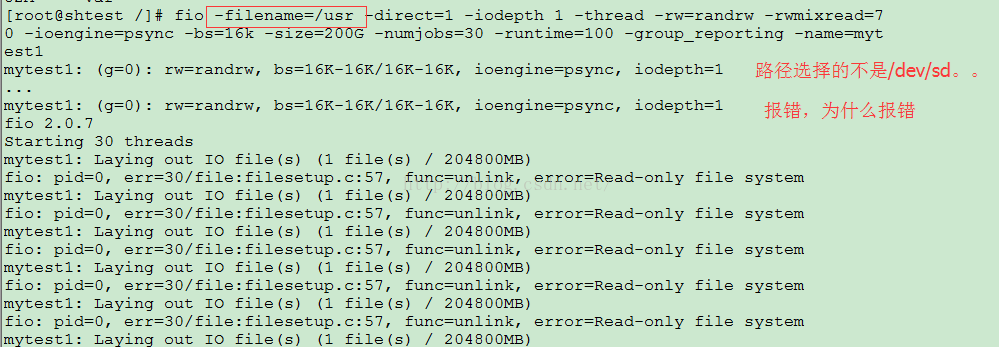
输出里写着错误的原因:error=Is a directory,fio是用来对裸设备做测试的,所以你的-filename参数不能使用目录,而应该使用硬盘分区,例如这样:-filename=/dev/sdb。你可以使用命令:sudo fdisk -l,来查看你当前有那些分区。
下面就是你需要了解fio的具体使用方法了,可以使用命令:man fio来查看,或者找一些文档。这里给一个提示
:不要对有数据的磁盘或分区做测试,fio测试会破坏已存在的数据。
影响IOPS的因素:
iodepth 队列深度对IOPS的影响 :
在某个时刻,有N个inflight的IO请求,包括在队列中的IO请求、磁盘正在处理的IO请求。N就是队列深度。
加大硬盘队列深度就是让硬盘不断工作,减少硬盘的空闲时间。
加大队列深度 -> 提高利用率 -> 获得IOPS和MBPS峰值 -> 注意响应时间在可接受的范围内,队列深度增加了,IO在队列的等待时间也会增加,导致IO响应时间变大,这需要权衡。
下面我们做两次测试,分别 iodepth = 1和iodepth = 4的情况。下面是iodepth = 1的测试结果。
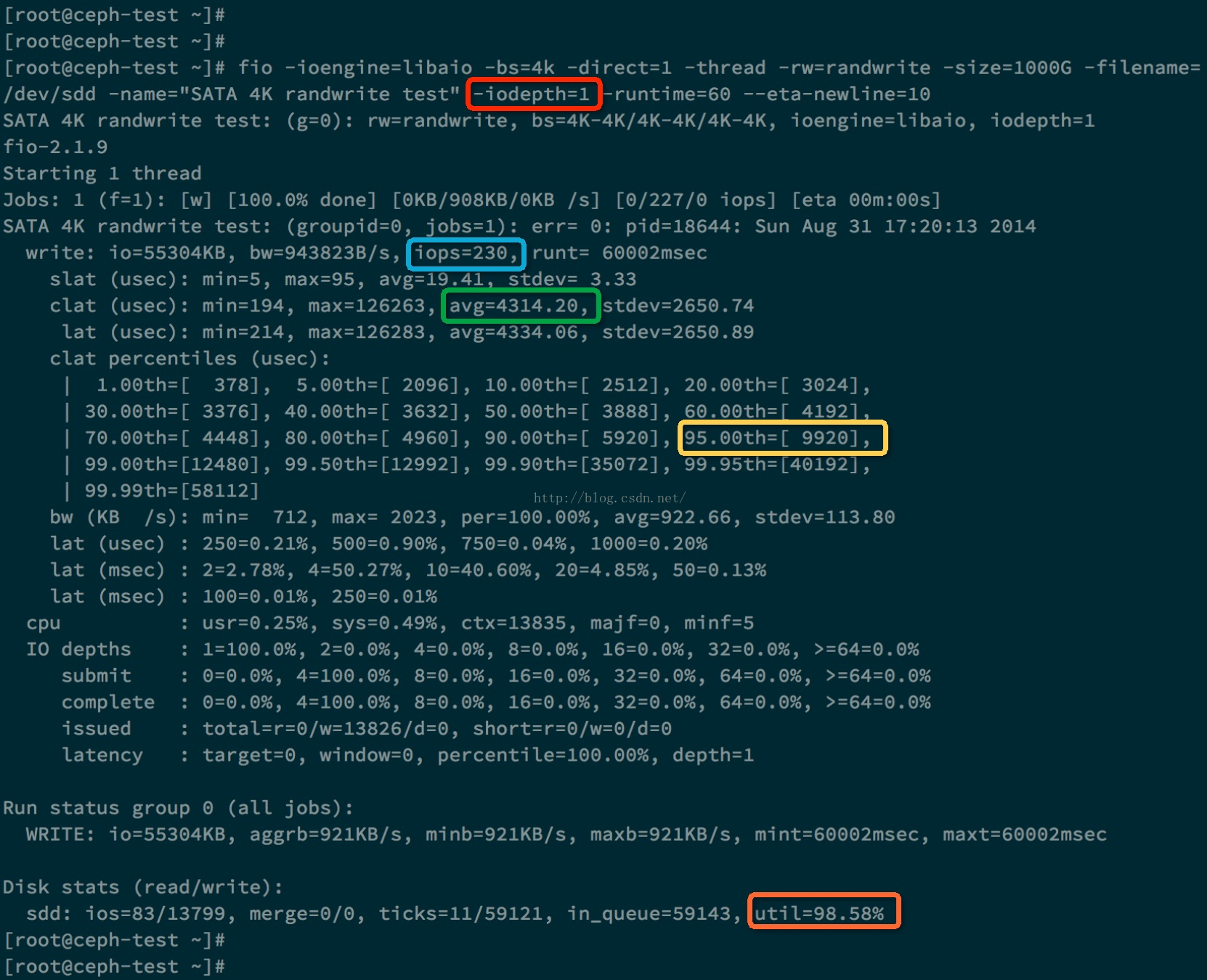
上图中蓝色方框里面的是测出的IOPS 230, 绿色方框里面是每个IO请求的平均响应时间,大约是4.3ms。黄色方框表示95%的IO请求的响应时间是小于等于 9.920 ms。橙色方框表示该硬盘的利用率已经达到了98.58%。
下面是 iodepth = 4 的测试:
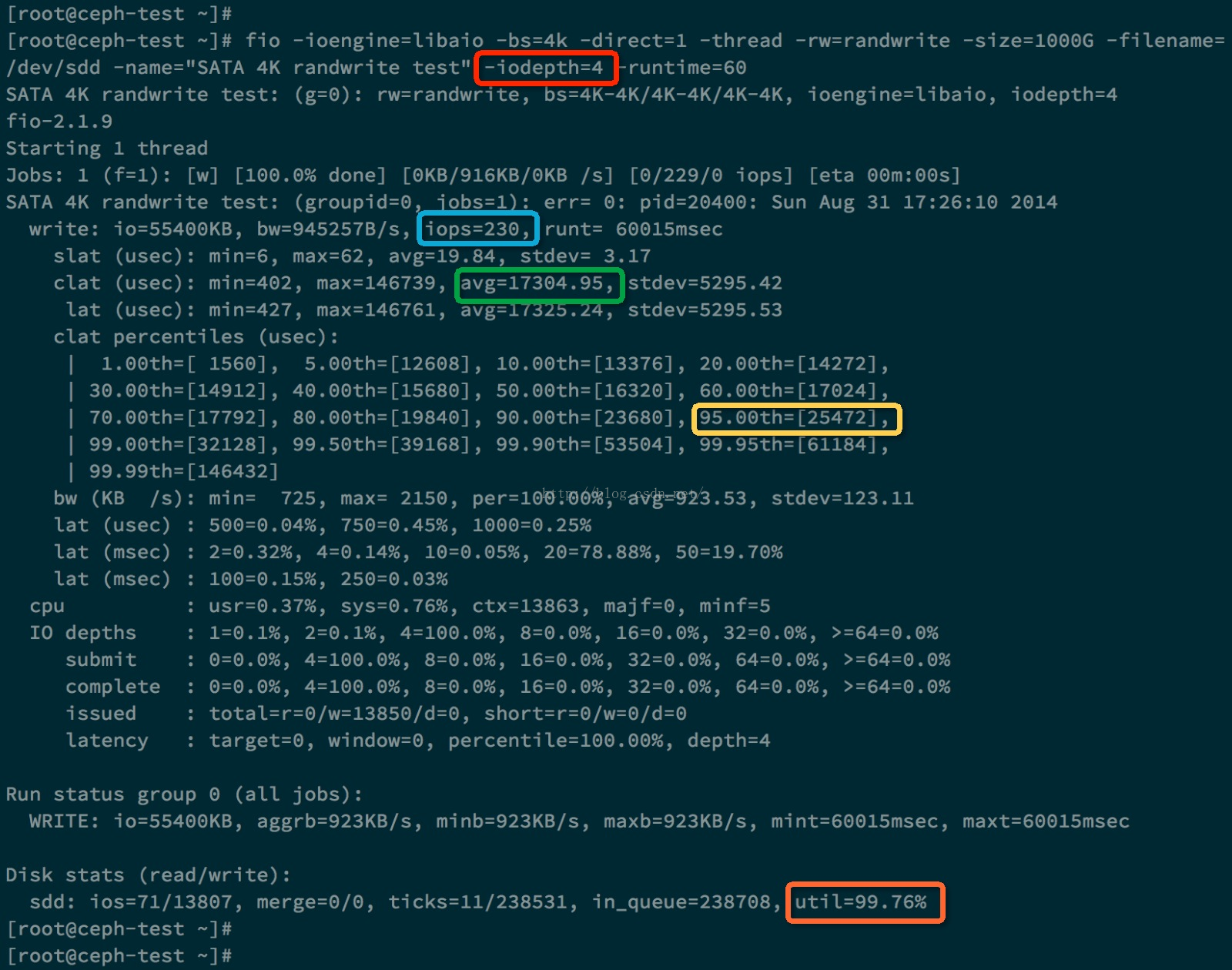
我们发现这次测试的IOPS没有提高,反而IO平均响应时间变大了,是17ms。
为什么这里提高队列深度没有作用呢,原因当队列深度为1时,硬盘的利用率已经达到了98%,说明硬盘已经没有多少空闲时间可以压榨了。而且响应时间为 4ms。 对于SATA硬盘,当增加队列深度时,并不会增加IOPS,只会增加响应时间。这是因为硬盘只有一个磁头,并行度是1, 所以当IO请求队列变长时,每个IO请求的等待时间都会变长,导致响应时间也变长。
寻址空间对IOPS的影响
我们继续测试SATA硬盘,前面我们提到寻址空间参数也会对IOPS产生影响,下面我们就测试当size=1GB时的情况。

我们发现,当设置size=1GB时,IOPS会显著提高到568,IO平均响应时间会降到7ms(队列深度为4)。这是因为当寻址空间为1GB时,磁头需要移动的距离变小了,每次IO请求的服务时间就降低了,这就是空间局部性原理。假如我们测试的RAID卡或者是磁盘阵列(SAN),它们可能会用Cache把这1GB的数据全部缓存,极大降低了IO请求的服务时间(内存的写操作比硬盘的写操作快很1000倍)。所以设置寻址空间为1GB的意义不大,因为我们是要测试硬盘的全盘性能,而不是Cache的性能。
硬盘优化
硬盘厂商提高硬盘性能的方法主要是降低服务时间(延迟):
提高转速(降低旋转时间和传输时间)
增加Cache(降低写延迟,但不会提高IOPS)
提高单磁道密度(变相提高传输时间)
RAID测试
RAID0/RAID5/RAID6的多块磁盘可以同时服务,其实就是提高并行度,这样极大提高了性能(相当于银行有多个柜台)。
以前测试过12块RAID0,100GB的寻址空间,4KB随机写,逐步提高队列深度,IOPS会提高,因为它有12块磁盘(12个磁头同时工作),并行度是12。

根据RAID和磁盘类型磁盘IOPS的计算
计算磁盘IOPS的三个因素:
1、RAID类型的读写比
不同RAID类型的IOPS计算公式:
| RAID类型 | 公式 |
| RAID5、RAID3 | Drive IOPS=Read IOPS + 4*Write IOPS |
| RAID6 | Drive IOPS=Read IOPS + 6*Write IOPS |
| RAID1、RAID10 | Drive IOPS=Read IOPS + 2*Write IOPS |
2、硬盘类型的IOPS值
不同磁盘类型的IOPS:
| 硬盘类型 | IOPS |
| FC 15K RPM | 180 |
| FC 10K RPM | 140 |
| SAS 15K RPM | 180 |
| SAS 10K RPM | 150 |
| SATA 10K RPM | 290 |
| SATA 7.2K RPM | 80 |
| SATA 5.4K RPM | 40 |
| Flash drive | 2500 |
3、具体业务系统的读写比
二、案例
1) 业务需求: 10TB 的FC 15K RPM存储空间,满足6000 IOPS,计算RAID5,RAID10分别需要多少块硬盘?
首先需要知道I/O中读操作与写操作所占的百分比。 假定6000 IOPS中读/写比是2:1
不同的RAID类型Drive 硬盘实际IOPS负载分别如下:
RAID10:(2/3)*6000+2*(1/3)*6000= 8000 IOPS
RAID5:(2/3)*6000+4*(1/3)*6000=12000 IOPS
参照不同硬盘类型的IOPS值,换算出需要多少块盘:
RAID10:8000 /180 = 45块
RAID5:12000/180 =67块
2) 一个RAID5,是由5块500G 10K RPM的FC盘组成,换算出该RAID支持的最大IOPS以及能够给前端应用提供的IOPS?
首先10K RPM的FC盘,单块盘的IOPS为140,5块盘最大IOPS值为700。
假设读写比为2:1,能够提供给前端应用的IOPS为:
(2/3)*X+4*(1/3)*X = 700
2*X = 700
X=350
能够提供给前端应用的IOPS为350。






 京公网安备 11010802041100号
京公网安备 11010802041100号