**转载 论文精读——CenterNet :Objects as Points
版权提示:此文章转载自 论文精读——CenterNet :Objects as Points
论文地址:https://arxiv.org/pdf/1904.07850.pdf
发布时间:2019.4.16
机构:UT Austin,UC Berkeley
代码:https://github.com/xingyizhou/CenterNet
Abstract
目标检测识别往往在图像上将目标用矩形框形式框出,该框的水平和垂直轴与图像的水平和垂直向平行。大多成功的目标检测器都先穷举出潜在目标位置,然后对该位置进行分类,这种做法浪费时间,低效,还需要额外的后处理。本文中,我们采用不同的方法,构建模型时将目标作为一个点——即目标BBox的中心点。我们的检测器采用关键点估计来找到中心点,并回归到其他目标属性,例如尺寸,3D位置,方向,甚至姿态。我们基于中心点的方法,称为:CenterNet,相比较于基于BBox的检测器,我们的模型是端到端可微的,更简单,更快,更精确。我们的模型实现了速度和精确的最好权衡,以下是其性能:
MS COCO dataset, with 28:1% AP at 142 FPS, 37:4% AP at 52 FPS, and 45:1% AP with multi-scale testing at 1.4 FPS.
用同个模型在KITTI benchmark 做3D bbox,在COCO keypoint dataset做人体姿态检测。同复杂的多阶段方法比较,我们的取得了有竞争力的结果,而且做到了实时的。
Introduction
目标检测 驱动了 很多基于视觉的任务,如 实例分割,姿态估计,跟踪,动作识别。且应用在下游业务中,如 监控,自动驾驶,视觉问答。当前检测器都以bbox轴对称框的形式紧紧贴合着目标。对于每个目标框,分类器来确定每个框中是否是特定类别目标还是背景。
One stage detectors 在图像上滑动复杂排列的可能bbox(即锚点),然后直接对框进行分类,而不会指定框中内容。
Two-stage detectors 对每个潜在框重新计算图像特征,然后将那些特征进行分类。
后处理,即 NMS(非极大值抑制),通过计算Bbox间的IOU来删除同个目标的重复检测框。这种后处理很难区分和训练,因此现有大多检测器都不是端到端可训练的。
本文通过目标中心点来呈现目标(见图2),然后在中心点位置回归出目标的一些属性,例如:size, dimension, 3D extent, orientation, pose。 而目标检测问题变成了一个标准的关键点估计问题。我们仅仅将图像传入全卷积网络,得到一个热力图,热力图峰值点即中心点,每个特征图的峰值点位置预测了目标的宽高信息。
模型训练采用标准的监督学习,推理仅仅是单个前向传播网络,不存在NMS这类后处理。

对我们的模型做一些拓展(见图4),可在每个中心点输出3D目标框,多人姿态估计所需的结果。
对于3D BBox检测,我们直接回归得到目标的深度信息,3D框的尺寸,目标朝向;
对于人姿态估计,我们将关节点(2D joint)位置作为中心点的偏移量,直接在中心点位置回归出这些偏移量的值。

由于模型设计简化,因此运行速度较高(见图1)

Related work
我们的方法与基于锚点的one-stage方法相近。中心点可看成形状未知的锚点(见图3)。但存在几个重要差别(本文创新点):
第一&#xff0c;我们分配的锚点仅仅是放在位置上&#xff0c;没有尺寸框。没有手动设置的阈值做前后景分类。&#xff08;像Faster RCNN会将与GT IOU >0.7的作为前景&#xff0c;<0.3的作为背景&#xff0c;其他不管&#xff09;&#xff1b;
第二&#xff0c;每个目标仅仅有一个正的锚点&#xff0c;因此不会用到NMS&#xff0c;我们提取关键点特征图上局部峰值点&#xff08;local peaks&#xff09;&#xff1b;
第三&#xff0c;CenterNet 相比较传统目标检测而言&#xff08;缩放16倍尺度&#xff09;&#xff0c;使用更大分辨率的输出特征图&#xff08;缩放了4倍&#xff09;&#xff0c;因此无需用到多重特征图锚点&#xff1b;

通过关键点估计做目标检测&#xff1a;
我们并非第一个通过关键点估计做目标检测的。CornerNet将bbox的两个角作为关键点&#xff1b;ExtremeNet 检测所有目标的 最上&#xff0c;最下&#xff0c;最左&#xff0c;最右&#xff0c;中心点&#xff1b;所有这些网络和我们的一样都建立在鲁棒的关键点估计网络之上。但是它们都需要经过一个关键点grouping阶段&#xff0c;这会降低算法整体速度&#xff1b;而我们的算法仅仅提取每个目标的中心点&#xff0c;无需对关键点进行grouping 或者是后处理&#xff1b;
单目3D 目标检测&#xff1a;
3D BBox检测为自动驾驶赋能。Deep3Dbox使用一个 slow-RCNN 风格的框架&#xff0c;该网络先检测2D目标&#xff0c;然后将目标送到3D 估计网络&#xff1b;3D RCNN在Faster-RCNN上添加了额外的head来做3D projection&#xff1b;Deep Manta 使用一个 coarse-to-fine的Faster-RCNN &#xff0c;在多任务中训练。而我们的模型同one-stage版本的Deep3Dbox 或3D RCNN相似&#xff0c;同样&#xff0c;CenterNet比它们都更简洁&#xff0c;更快。
Preliminary
令 分散到热力图
分散到热力图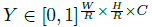 上&#xff0c;其中
上&#xff0c;其中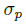 是目标尺度-自适应 的标准方差。如果对于同个类 c &#xff08;同个关键点或是目标类别&#xff09;有两个高斯函数发生重叠&#xff0c;我们选择元素级最大的。训练目标函数如下&#xff0c;像素级逻辑回归的focal loss&#xff1a;
是目标尺度-自适应 的标准方差。如果对于同个类 c &#xff08;同个关键点或是目标类别&#xff09;有两个高斯函数发生重叠&#xff0c;我们选择元素级最大的。训练目标函数如下&#xff0c;像素级逻辑回归的focal loss&#xff1a;
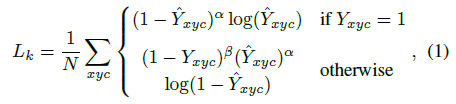
其中  和
和  是focal loss的超参数&#xff0c;实验中两个数分别设置为2和4&#xff0c; N是图像 I 中的关键点个数&#xff0c;除以N主要为了将所有focal loss归一化。
是focal loss的超参数&#xff0c;实验中两个数分别设置为2和4&#xff0c; N是图像 I 中的关键点个数&#xff0c;除以N主要为了将所有focal loss归一化。
由于图像下采样时&#xff0c;GT的关键点会因数据是离散的而产生偏差&#xff0c;我们对每个中心点附加预测了个局部偏移 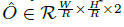 所有类别 c 共享同个偏移预测&#xff0c;这个偏移同个 L1 loss来训练&#xff1a;
所有类别 c 共享同个偏移预测&#xff0c;这个偏移同个 L1 loss来训练&#xff1a;
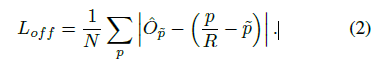
只会在关键点位置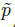 做监督操作&#xff0c;其他位置无视。下面章节介绍如何将关键点估计用于目标检测。
做监督操作&#xff0c;其他位置无视。下面章节介绍如何将关键点估计用于目标检测。
Objects as Points
令 是目标 k &#xff08;其类别为
是目标 k &#xff08;其类别为 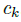 &#xff09;的bbox. 其中心位置为
&#xff09;的bbox. 其中心位置为 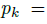
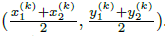 &#xff0c;我们用 关键点估计
&#xff0c;我们用 关键点估计  来得到所有的中心点&#xff0c;此外&#xff0c;为每个目标 k 回归出目标的尺寸
来得到所有的中心点&#xff0c;此外&#xff0c;为每个目标 k 回归出目标的尺寸 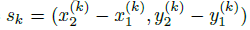 。为了减少计算负担&#xff0c;我们为每个目标种类使用单一的尺寸预测
。为了减少计算负担&#xff0c;我们为每个目标种类使用单一的尺寸预测 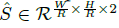 &#xff0c;我们在中心点位置添加了 L1 loss:
&#xff0c;我们在中心点位置添加了 L1 loss:
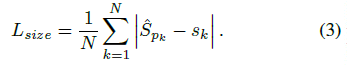
我们不将scale进行归一化&#xff0c;直接使用原始像素坐标。为了调节该loss的影响&#xff0c;将其乘了个系数&#xff0c;整个训练的目标loss函数为&#xff1a;

实验中&#xff0c;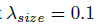 &#xff0c;
&#xff0c;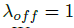 &#xff0c;整个网络预测会在每个位置输出 C&#43;4个值(即关键点类别C, 偏移量的x,y&#xff0c;尺寸的w,h)&#xff0c;所有输出共享一个全卷积的backbone;
&#xff0c;整个网络预测会在每个位置输出 C&#43;4个值(即关键点类别C, 偏移量的x,y&#xff0c;尺寸的w,h)&#xff0c;所有输出共享一个全卷积的backbone;
从点到Bbox
在推理的时候&#xff0c;我们分别提取热力图上每个类别的峰值点。如何得到这些峰值点呢&#xff1f;做法是将热力图上的所有响应点与其连接的8个临近点进行比较&#xff0c;如果该点响应值大于或等于其八个临近点值则保留&#xff0c;最后我们保留所有满足之前要求的前100个峰值点。令 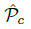 是检测到的 c 类别的 n 个中心点的集合。
是检测到的 c 类别的 n 个中心点的集合。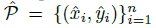 每个关键点以整型坐标
每个关键点以整型坐标  的形式给出。
的形式给出。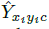 作为测量得到的检测置信度&#xff0c; 产生如下的bbox:
作为测量得到的检测置信度&#xff0c; 产生如下的bbox:

其中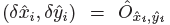 是偏移预测结果&#xff1b;
是偏移预测结果&#xff1b;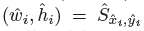 是尺度预测结果&#xff1b;所有的输出都直接从关键点估计得到&#xff0c;无需基于IOU的NMS或者其他后处理。
是尺度预测结果&#xff1b;所有的输出都直接从关键点估计得到&#xff0c;无需基于IOU的NMS或者其他后处理。
3D 检测
3D检测是对每个目标进行3维bbox估计&#xff0c;每个中心点需要3个附加信息&#xff1a;depth, 3D dimension&#xff0c; orientation。我们为每个信息分别添加head.
对于每个中心点&#xff0c;深度值depth是一个维度的。然后depth很难直接回归&#xff01;我们参考【D. Eigen, C. Puhrsch, and R. Fergus. Depth map prediction from a single image using a multi-scale deep network. In NIPS, 2014.】对输出做了变换。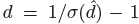 其中
其中 是sigmoid函数&#xff0c;在特征点估计网络上添加了一个深度计算通道
是sigmoid函数&#xff0c;在特征点估计网络上添加了一个深度计算通道 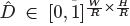 &#xff0c; 该通道使用了两个卷积层&#xff0c;然后做ReLU 。我们用L1 loss来训练深度估计器。
&#xff0c; 该通道使用了两个卷积层&#xff0c;然后做ReLU 。我们用L1 loss来训练深度估计器。
目标的3D维度是三个标量值。我们直接回归出它们&#xff08;长宽高&#xff09;的绝对值&#xff0c;单位为米&#xff0c;用的是一个独立的head : 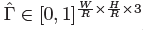 和L1 loss;
和L1 loss;
方向默认是单标量的值&#xff0c;然而其也很难回归。我们参考【A. Mousavian, D. Anguelov, J. Flynn, and J. Kosecka.
3d bounding box estimation using deep learning and geometry. In CVPR, 2017.】&#xff0c; 用两个bins来呈现方向&#xff0c;且i做n-bin回归。特别地&#xff0c;方向用8个标量值来编码的形式&#xff0c;每个bin有4个值。对于一个bin,两个值用作softmax分类&#xff0c;其余两个值回归到在每个bin中的角度。
人姿态估计
人的姿态估计旨在估计 图像中每个人的k 个2D人的关节点位置&#xff08;在COCO中&#xff0c;k是17&#xff0c;即每个人有17个关节点&#xff09;。因此&#xff0c;我们令中心点的姿态是 kx2维的&#xff0c;然后将每个关键点&#xff08;关节点对应的点&#xff09;参数化为相对于中心点的偏移。 我们直接回归出关节点的偏移&#xff08;像素单位&#xff09;  &#xff0c;用到了L1 loss&#xff1b;我们通过给loss添加mask方式来无视那些不可见的关键点&#xff08;关节点&#xff09;。此处参照了slow-RCNN。
&#xff0c;用到了L1 loss&#xff1b;我们通过给loss添加mask方式来无视那些不可见的关键点&#xff08;关节点&#xff09;。此处参照了slow-RCNN。
为了refine关键点&#xff08;关节点&#xff09;&#xff0c;我们进一步估计k 个人体关节点热力图 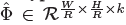 &#xff0c;使用的是标准的bottom-up 多人体姿态估计【4,39,41】,我们训练人的关节点热力图使用focal loss和像素偏移量&#xff0c;这块的思路和中心点的训练雷同。我们找到热力图上训练得到的最近的初始预测值&#xff0c;然后将中心偏移作为一个grouping的线索&#xff0c;来为每个关键点&#xff08;关节点&#xff09;分配其最近的人。具体来说&#xff0c;令
&#xff0c;使用的是标准的bottom-up 多人体姿态估计【4,39,41】,我们训练人的关节点热力图使用focal loss和像素偏移量&#xff0c;这块的思路和中心点的训练雷同。我们找到热力图上训练得到的最近的初始预测值&#xff0c;然后将中心偏移作为一个grouping的线索&#xff0c;来为每个关键点&#xff08;关节点&#xff09;分配其最近的人。具体来说&#xff0c;令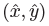 是检测到的中心点。第一次回归得到的关节点为&#xff1a;
是检测到的中心点。第一次回归得到的关节点为&#xff1a;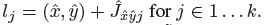
我们提取到的所有关键点&#xff08;关节点&#xff0c;此处是类似中心点检测用热力图回归得到的&#xff0c;对于热力图上值小于0.1的直接略去&#xff09;&#xff1a;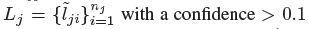 for each joint type j from the corresponding heatmap
for each joint type j from the corresponding heatmap 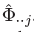
然后将每个回归&#xff08;第一次回归&#xff0c;通过偏移方式&#xff09;位置 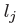 与最近的检测关键点&#xff08;关节点&#xff09;进行分配
与最近的检测关键点&#xff08;关节点&#xff09;进行分配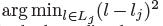 &#xff0c;考虑到只对检测到的目标框中的关节点进行关联。
&#xff0c;考虑到只对检测到的目标框中的关节点进行关联。
Implementation details
我们实验了4个结构&#xff1a;ResNet-18, ResNet-101, DLA-34&#xff0c; Hourglass-104. 我们用deformable卷积层来更改ResNets和DLA-34&#xff0c;按照原样使用Hourglass 网络。

Hourglass
堆叠的Hourglass网络【30,40】通过两个连续的hourglass 模块对输入进行了4倍的下采样&#xff0c;每个hourglass 模块是个对称的5层 下和上卷积网络&#xff0c;且带有skip连接。该网络较大&#xff0c;但通常会生成最好的关键点估计。
ResNet
Xiao et al. [55]等人对标准的ResNet做了3个up-convolutional网络来dedao更高的分辨率输出&#xff08;最终stride为4&#xff09;。为了节省计算量&#xff0c;我们改变这3个up-convolutional的输出通道数分别为256,128,64。up-convolutional核初始为双线性插值。
DLA
即Deep Layer Aggregation (DLA)&#xff0c;是带多级跳跃连接的图像分类网络&#xff0c;我们采用全卷积上采样版的DLA&#xff0c;用deformable卷积来跳跃连接低层和输出层&#xff1b;将原来上采样层的卷积都替换成3x3的deformable卷积。在每个输出head前加了一个3x3x256的卷积&#xff0c;然后做1x1卷积得到期望输出。
Training
训练输入图像尺寸&#xff1a;512x512; 输出分辨率&#xff1a;128x128 (即4倍stride)&#xff1b;采用数据增强方式&#xff1a;随机flip, 随机scaling (比例在0.6到1.3)&#xff0c;裁剪&#xff0c;颜色jittering&#xff1b;采用Adam优化器&#xff1b;
在3D估计分支任务中未采用数据增强&#xff08;scaling和crop会影响尺寸&#xff09;&#xff1b;
更详细的训练参数设置&#xff08;学习率&#xff0c;GPU数量&#xff0c;初始化策略等&#xff09;见论文~~
Inference
采用3个层次的测试增强&#xff1a;没增强&#xff0c;flip增强&#xff0c;flip和multi-scale&#xff08;0.5,0.75,1.25,1.5&#xff09;增强&#xff1b;For flip, we average the network
outputs before decoding bounding boxes. For multi-scale,we use NMS to merge results.
Experiments




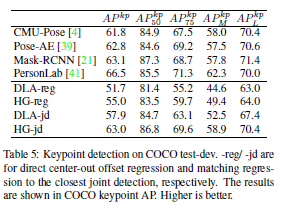
文章网络结构细节信息见下图&#xff1a;










 京公网安备 11010802041100号
京公网安备 11010802041100号