首页
技术博客
PHP教程
数据库技术
前端开发
HTML5
Nginx
php论坛
新用户注册
|
会员登录
PHP教程
技术博客
编程问答
PNG素材
编程语言
前端技术
Android
PHP教程
HTML5教程
数据库
Linux技术
Nginx技术
PHP安全
WebSerer
职场攻略
JavaScript
开放平台
业界资讯
大话程序猿
登录
极速注册
取消
热门标签 | HotTags
httpclient
md5
hashset
httprequest
schema
spring
数组
io
php7
metadata
usb
uri
jsp
erlang
join
heatmap
window
bitmap
buffer
replace
vba
flutter
iostream
request
php
foreach
search
case
grid
tree
install
jar
python2
split
frameworks
bytecode
runtime
config
heap
js
stream
byte
get
text
controller
hash
bit
typescript
keyword
match
solr
header
go
java
email
format
filter
future
main
cookie
function
cmd
blob
hashcode
settings
object
cPlusPlus
include
select
require
expression
perl
datetime
php5
javascript
cpython
testing
input
timezone
当前位置:
开发笔记
>
编程语言
> 正文
CacheManager彻底解密:CacheManager运行原理流程图和源码详解
作者:傻丫头苏婵_596 | 来源:互联网 | 2023-09-08 13:07
主题CacheManager运行原理图CacheManager源码解析CacheManager运行原理图[下图是CacheManager的运行原理图]首先RDD是通过itera
主题
CacheManager 运行原理图
CacheManager 源码解析
CacheManager 运行原理图
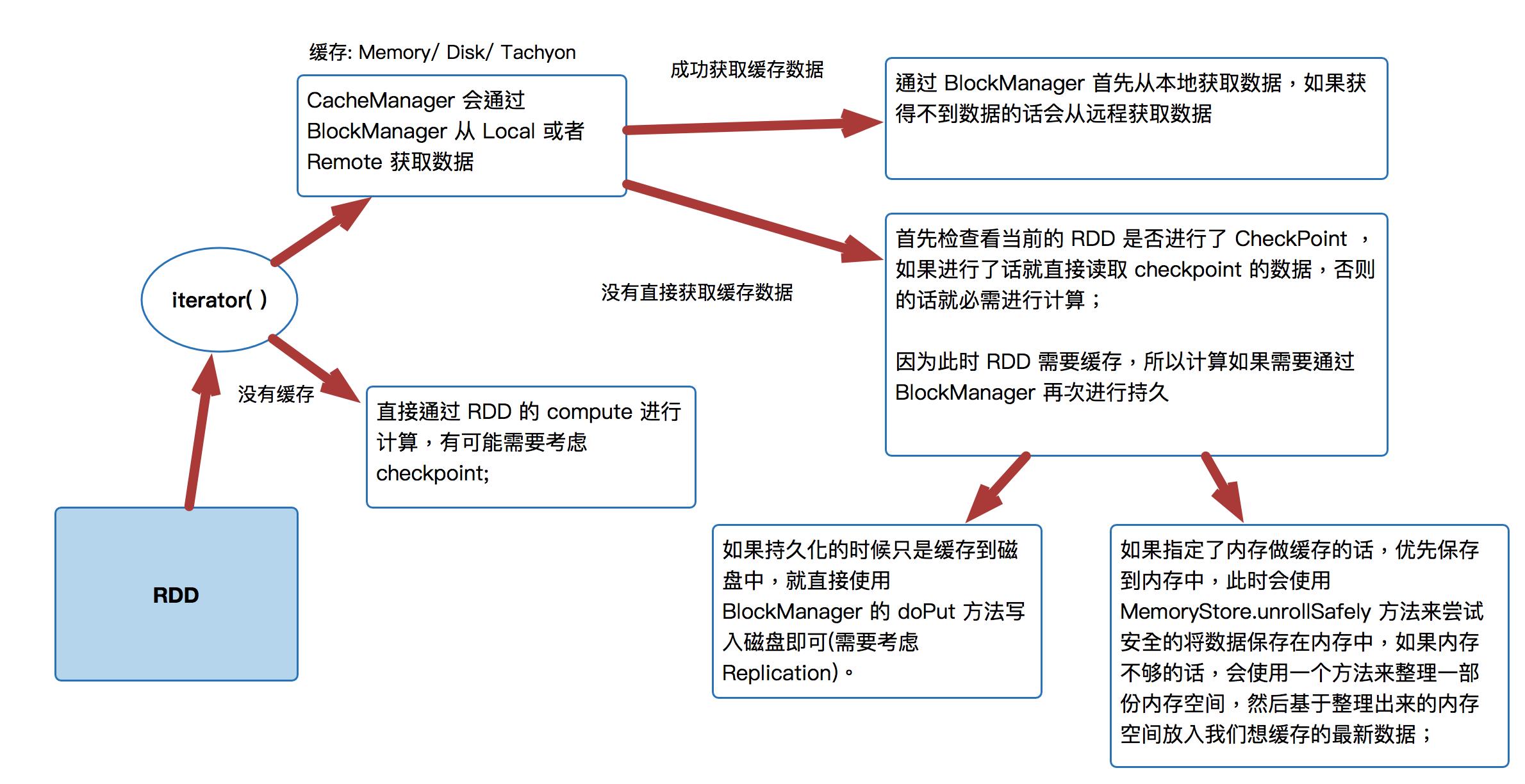
[下图是CacheManager的运行原理图]
首先 RDD 是通过 iterator 来进行计算:
CacheManager 会通过 BlockManager 从 Local 或者 Remote 获取数据直接通过 RDD 的 compute 进行计算,有可能需要考虑 checkpoint;
通过 BlockManager 首先从本地获取数据,如果获得不到数据的话会从远程获取数据
首先检查看当前的 RDD 是否进行了 CheckPoint ,如果进行了话就直接读取 checkpoint 的数据,否则的话就必需进行计算;因为此时 RDD 需要缓存,所以计算如果需要通过 BlockManager 再次进行持久
如果持久化的时候只是缓存到磁盘中,就直接使用 BlockManager 的 doPut 方法写入磁盘即可(需要考虑 Replication)。
如果指定了内存做缓存的话,优先保存到内存中,此时会使用MemoryStore.unrollSafely 方法来尝试安全的将数据保存在内存中,如果内存不够的话,会使用一个方法来整理一部份内存空间,然后基于整理出来的内存空间放入我们想缓存的最新数据;
直接通过 RDD 的 compute 进行计算,有可能需要考虑 checkpoint;
CacheManager 源码解析
CacheManager 管理的是
缓存中的数据
,缓存可以是基于内存的缓存,也可以是基于磁盘的缓存;
CacheManager 需要通过 BlockManager 来操作数据;
每当 Task 运行的时候会调用
RDD 的 Compute
方法进行计算,而 Compute 方法会调用
iterator
方法;
[下图是 MapPartitionRDD.scala 的 compute 方法]
这个方法是 final 级别不能覆写但可以被子类去使用,可以看见 RDD 是优先使用内存的,这个方法很关键!!如果存储级别不等于 NONE 的情况下,程序会先找 CacheManager 获得数据,否则的话会看有没有进行 Checkpoint
[下图是 RDD.scala 的 iterator 方法]
以下是 Spark 中的 StorageLevel
[下图是 StorageLevel.scala 的 StorageLevel 对象]
Cache 在工作的时候会最大化的保留数据,但是数据不一定绝对完整,因为当前的计算如果需要内存空间的话,那么内存中的数据必需让出空间,这是因为执行比缓存重要!此时如何在RDD 持久化的时候同时指定了可以把数据放左Disk 上,那么部份 Cache 的数据可以从内存转入磁盘,否则的话,数据就会丢失!
假设现在 Cache 了一百万个数据分片,但是我下一个步骤计算的时候,我需要内存,思考题:你觉得是我现在需要的内存重要呢,还是你曾经 Cache 占用的空间重要呢?亳无疑问,肯定是现在计算重要。所以 Cache 占用的空间需要从内存中除掉,如果你程序的 StorageLevel 是 MEMEORY_AND_DISK 的话,这时候在内存可能是 Drop 到磁盘上,如果你程序的 StorageLevel 是 MEMEORY_ONLY 的话,那就会出去数据丢失的情况。
你进行Cache时,BlockManager 会帮你进行管理,我们可以通过 Key 到 BlockManager 中找出曾经缓存的数据。
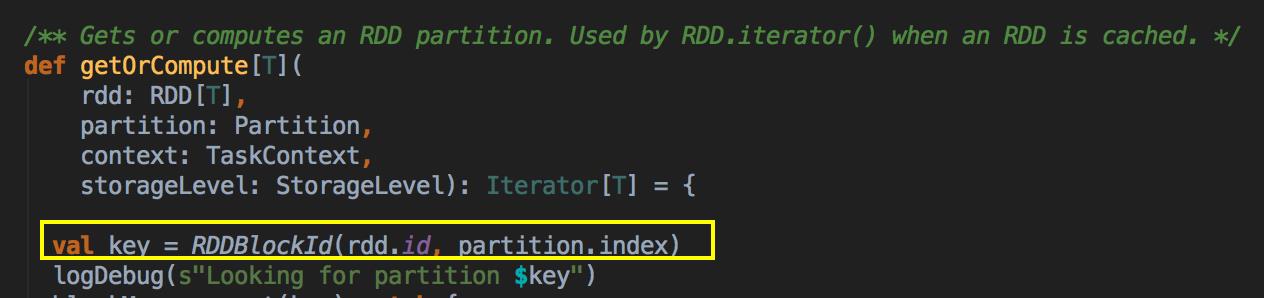
[下图是 CacheManager.scala 的 getOrCompute 方法]
[下图是 CacheManager.scala 的 getOrCompute 方法内部具体的实现]
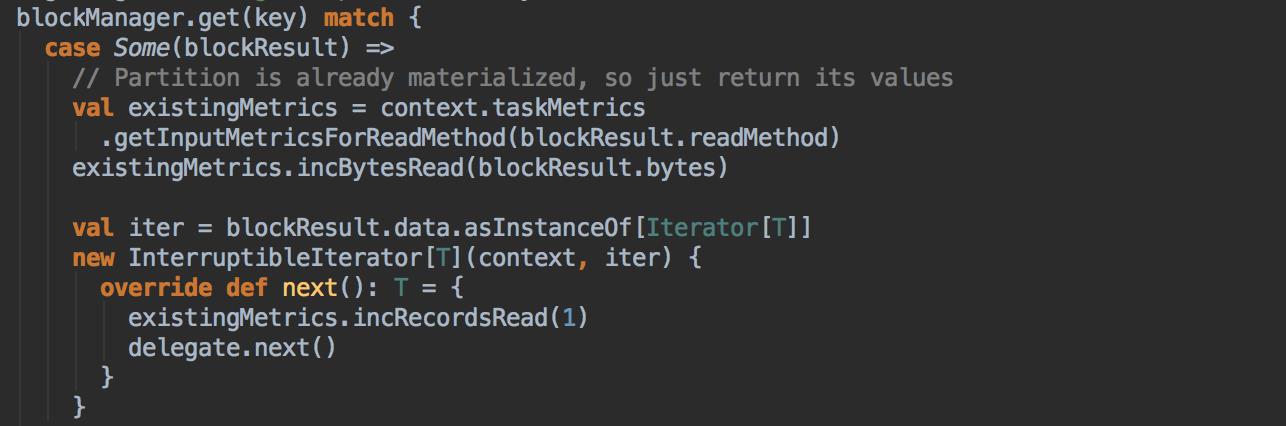
如果有 BlockManager.get() 方法没有返回任何数据,就调用 acquireLockForPartition 方法,因为会有可能多条线程在操作数据,Spark 有一个东西叫慢任务StraggleTask 推迟,StraggleTask 推迟的时候一般都会运行两个任务在两台机器上,你可能在你当前机器上没有发现这个内容,同时有远程也没有发现这个内容,只不过在你返回的那一刻,别人已经算完啦!
[下图是 CacheManager.scala 的 getOrCompute 方法内部具体的实现]
[下图是 CacheManager.scala 的 getOrCompute 方法内部具体的实现]
最后还是通过 BlockManager.get 来获得数据
[下图是 CacheManager.scala 的 acquireLockForPartition 方法]
具体 CacheManager 在获得缓存数据的时候会通过 BlockManager 来抓到数据,
优先在本地找数据或者的话就远程抓取数据
。
[下图是 BlockManager.scala 的 get 方法]
BlockManger.getLocal 然后转过来调用 doGetLocal 方法,在 doGetLocal 的实现中看到缓存其实不竟竟在内存中,可以在内存、磁盘、也可以在 OffHeap (Tachyon) 中
[下图是 BlockManager.scala 的 getLocal 方法]
在第5步调用了 getLocal 方法后转过调用了 doGetLocal
[下图是 BlockManager.scala 的 doGetLocal 方法]
在第5步中如果本地没有缓存的话就调用 getRemote 方法从远程抓取数据
[下图是 BlockManager.scala 的 getRemote 方法]
如果 CacheManager 没有通过 BlockManager 获得缓存内容的话,其实会通过 RDD 的
computeOrReadCheckpoint
方法来获得数据。
[下图是 RDD.scala 的 computeOrReadChcekpoint 方法]
上述首先检查看当前的 RDD 是否进行了 Checkpoint ,如果进行了话就直接读取 checkpoint 的数据,否则的话就必需进行计算; Checkpoint 本身很重要;
计算之后通过 putInBlockManager 会把数据按照 StorageLevel 重新缓存起来
。
[下图是 CacheManager.scala 的 putInBlockManager 方法]
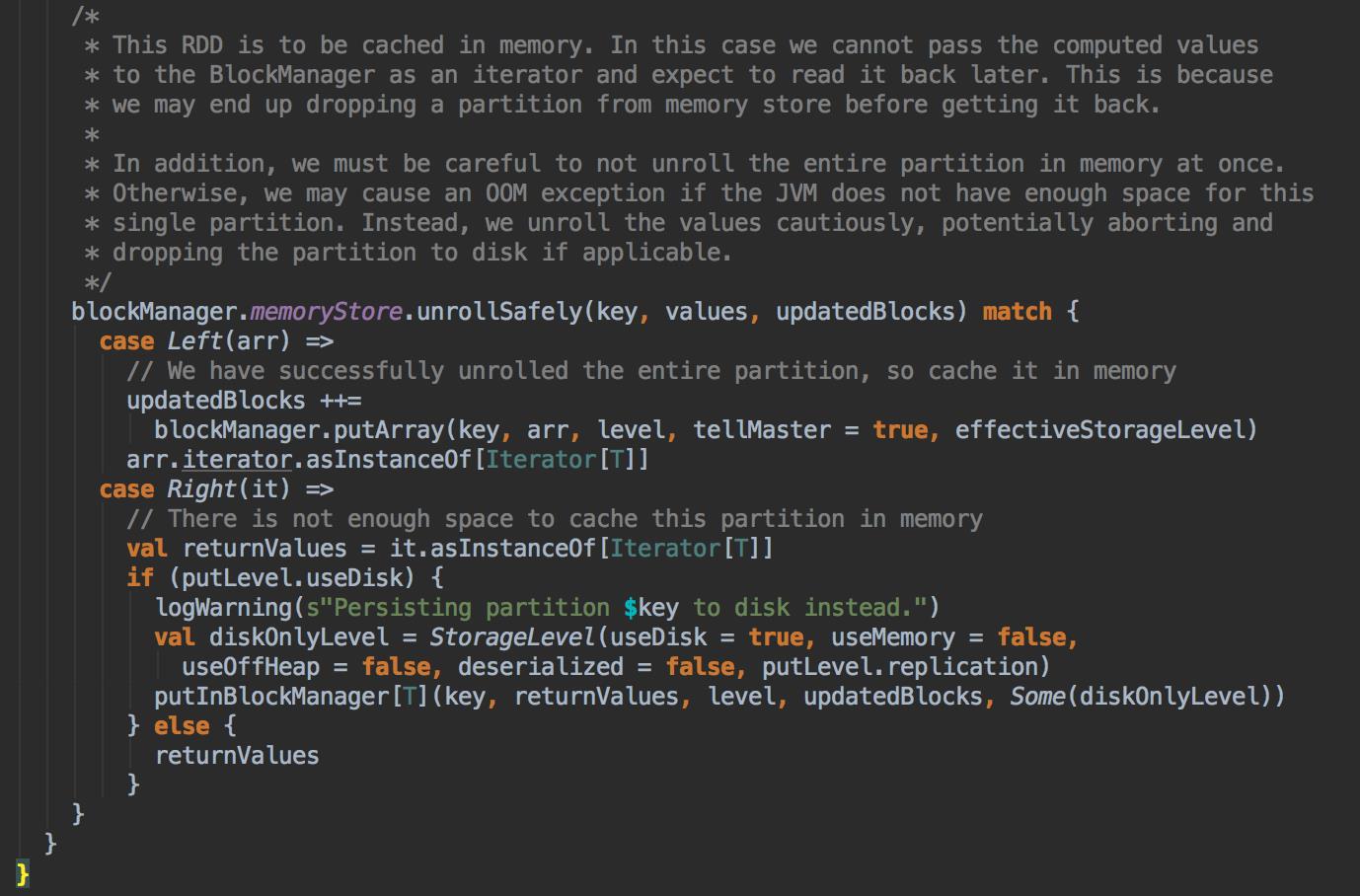
你如果把数据缓存在内存中,你需要注意的是内存空间够不够,此时会调用 memoryStore 中的 unrollSafety 方法,里面有一个循环在内存中放数据。
[下图是 MemoryStore.scala 中的 unrollSafely 方法]
cache
int
缓存
io
安全
scala
final
spark
storage
写下你的评论吧 !
吐个槽吧,看都看了
会员登录
|
用户注册
推荐阅读
php
第二章:Kafka基础入门与核心概念解析
本章节主要介绍了Kafka的基本概念及其核心特性。Kafka是一种分布式消息发布和订阅系统,以其卓越的性能和高吞吐量而著称。最初,Kafka被设计用于LinkedIn的活动流和运营数据处理,旨在高效地管理和传输大规模的数据流。这些数据主要包括用户活动记录、系统日志和其他实时信息。通过深入解析Kafka的设计原理和应用场景,读者将能够更好地理解其在现代大数据架构中的重要地位。 ...
[详细]
蜡笔小新 2024-11-06 11:10:03
case
Scala学习指南:从零开始掌握基础
本指南从零开始介绍Scala编程语言的基础知识,重点讲解了Scala解释器REPL(读取-求值-打印-循环)的使用方法。REPL是Scala开发中的重要工具,能够帮助初学者快速理解和实践Scala的基本语法和特性。通过详细的示例和练习,读者将能够熟练掌握Scala的基础概念和编程技巧。 ...
[详细]
蜡笔小新 2024-11-07 18:07:59
tree
探索阿里云RDS中MySQL的高效压缩存储引擎TokuDB应用
在过去,我曾使用过自建MySQL服务器中的MyISAM和InnoDB存储引擎(也曾尝试过Memory引擎)。今年初,我开始转向阿里云的关系型数据库服务,并深入研究了其高效的压缩存储引擎TokuDB。TokuDB在数据压缩和处理大规模数据集方面表现出色,显著提升了存储效率和查询性能。通过实际应用,我发现TokuDB不仅能够有效减少存储成本,还能显著提高数据处理速度,特别适用于高并发和大数据量的场景。 ...
[详细]
蜡笔小新 2024-11-04 11:36:52
io
Spark与HBase结合处理大规模流量数据结构设计
本文将详细介绍如何利用Spark和HBase进行大规模流量数据的分析与处理,包括数据结构的设计和优化方法。 ...
[详细]
蜡笔小新 2024-11-12 19:49:05
io
Java 并发编程:深入解析 AtomicInteger 和 CAS 无锁算法
在多线程并发环境中,普通变量的操作往往是线程不安全的。本文通过一个简单的例子,展示了如何使用 AtomicInteger 类及其核心的 CAS 无锁算法来保证线程安全。 ...
[详细]
蜡笔小新 2024-11-12 16:40:04
io
如何在Java中使用DButils类
这期内容当中小编将会给大家带来有关如何在Java中使用DButils类,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。D ...
[详细]
蜡笔小新 2024-11-12 13:46:11
case
PHP 对象生命周期与内存管理
本文详细介绍了 PHP 中对象的生命周期、内存管理和魔术方法的使用,包括对象的自动销毁、析构函数的作用以及各种魔术方法的具体应用场景。 ...
[详细]
蜡笔小新 2024-11-12 13:35:26
io
开发中遇到的一些常见问题及解决方案
本文总结了一些开发中常见的问题及其解决方案,包括特性过滤器的使用、NuGet程序集版本冲突、线程存储、溢出检查、ThreadPool的最大线程数设置、Redis使用中的问题以及Task.Result和Task.GetAwaiter().GetResult()的区别。 ...
[详细]
蜡笔小新 2024-11-12 08:20:05
join
掌握MySQL数据库的基础语法与核心操作
本文详细介绍了MySQL数据库的基础语法与核心操作,涵盖从基础概念到具体应用的多个方面。首先,文章从基础知识入手,逐步深入到创建和修改数据表的操作。接着,详细讲解了如何进行数据的插入、更新与删除。在查询部分,不仅介绍了DISTINCT和LIMIT的使用方法,还探讨了排序、过滤和通配符的应用。此外,文章还涵盖了计算字段以及多种函数的使用,包括文本处理、日期和时间处理及数值处理等。通过这些内容,读者可以全面掌握MySQL数据库的核心操作技巧。 ...
[详细]
蜡笔小新 2024-11-11 23:39:51
request
Java并发编程指南:深入理解信号量机制
本文是Java并发编程系列的开篇之作,将详细解析Java 1.5及以上版本中提供的并发工具。文章假设读者已经具备同步和易失性关键字的基本知识,重点介绍信号量机制的内部工作原理及其在实际开发中的应用。 ...
[详细]
蜡笔小新 2024-11-11 15:49:02
io
Java类加载机制详解:第二阶段深入解析
类加载机制是Java虚拟机运行时的重要组成部分。本文深入解析了类加载过程的第二阶段,详细阐述了从类被加载到虚拟机内存开始,直至其从内存中卸载的整个生命周期。这一过程中,类经历了加载(Loading)、验证(Verification)等多个关键步骤。通过具体的实例和代码示例,本文探讨了每个阶段的具体操作和潜在问题,帮助读者全面理解类加载机制的内部运作。 ...
[详细]
蜡笔小新 2024-11-11 11:42:38
tree
深入解析JDK 8 HashMap源代码:put方法详解及capacity、size、loadFactor和红黑树转换阈值的设定原理
本文深入解析了JDK 8中HashMap的源代码,重点探讨了put方法的工作机制及其内部参数的设定原理。HashMap允许键和值为null,但键为null的情况只能出现一次,因为null键在内部通过索引0进行存储。文章详细分析了capacity(容量)、size(大小)、loadFactor(加载因子)以及红黑树转换阈值的设定原则,帮助读者更好地理解HashMap的高效实现和性能优化策略。 ...
[详细]
蜡笔小新 2024-11-10 14:10:53
case
深入剖析Java中SimpleDateFormat在多线程环境下的潜在风险与解决方案
深入剖析Java中SimpleDateFormat在多线程环境下的潜在风险与解决方案 ...
[详细]
蜡笔小新 2024-11-09 19:04:36
case
分享一款基于Java开发的经典贪吃蛇游戏实现
本文介绍了一款使用Java语言开发的经典贪吃蛇游戏的实现。游戏主要由两个核心类组成:`GameFrame` 和 `GamePanel`。`GameFrame` 类负责设置游戏窗口的标题、关闭按钮以及是否允许调整窗口大小,并初始化数据模型以支持绘制操作。`GamePanel` 类则负责管理游戏中的蛇和苹果的逻辑与渲染,确保游戏的流畅运行和良好的用户体验。 ...
[详细]
蜡笔小新 2024-11-08 17:59:38
tree
投融资周报 | Circle 达成 4 亿美元融资协议,唯一艺术平台 A 轮融资超千万美元
投融资周报 | Circle 达成 4 亿美元融资协议,唯一艺术平台 A 轮融资超千万美元 ...
[详细]
蜡笔小新 2024-11-05 04:56:42
傻丫头苏婵_596
这个家伙很懒,什么也没留下!
Tags | 热门标签
httpclient
md5
hashset
httprequest
schema
spring
数组
io
php7
metadata
usb
uri
jsp
erlang
join
heatmap
window
bitmap
buffer
replace
vba
flutter
iostream
request
php
foreach
search
case
grid
tree
RankList | 热门文章
1
前端图片合成技术_靠谱的前端需要做哪些准备?
2
IE浏览器一打开即无响应、崩溃&“ieframe.dll没有被指定在Windows上运行,或者它包含错误,错误代码:0xc000012f”的解决方案~
3
C#中的自定义控件中的属性、事件及一些相关特性的总结
4
Lisp之根源 保罗格雷厄姆
5
Oracle数据库文件路径怎么改,在已修复的Oracle数据库中更改文件路径
6
用自定义消息在线程间通信(VC)
7
什么牌子的冰柜好用又实惠(冷柜十大名牌排行榜)
8
vue 获取index
9
输出用JS 输出的HTML显示的带链接的邮件地址,点击后可直接打开邮件程序
10
redis 获取不到_redis 缓存锁的实现方法
11
html+css实现图片滑移效果
12
【solidity之浮点数计算方法总结】solidity之变量运算小数点会截断,而字面常量运算小数点不会截断
13
用Kubeadm安装K8s后,kubeflannelds一直CrashLoopBackOff
14
MongoDB中的Group By
15
appium+python的APP自动化(2)
PHP1.CN | 中国最专业的PHP中文社区 |
DevBox开发工具箱
|
json解析格式化
|
PHP资讯
|
PHP教程
|
数据库技术
|
服务器技术
|
前端开发技术
|
PHP框架
|
开发工具
|
在线工具
Copyright © 1998 - 2020 PHP1.CN. All Rights Reserved |
京公网安备 11010802041100号
|
京ICP备19059560号-4
| PHP1.CN 第一PHP社区 版权所有

























 京公网安备 11010802041100号
京公网安备 11010802041100号