本文基于收集到的10080个现场视频和62535个问答对,创建了一个新的数据集TrafficQA(Traffic Question Answering),该数据集采用视频问答的形式,用于测试复杂交通场景下的因果推理和事件理解模型的认知能力。具体地,作者提出了6个具有挑战性的推理任务,分别对应于不同的交通场景,以评估不同类型复杂而实用的交通事件的推理能力。此外,作者还提出了一种新的基于动态推理的Efficient glimpse network,即Eclipse,以实现计算效率高且可靠的视频推理。实验表明,该方法在显着降低计算量的同时,取得了较好的性能。

提出6个具有挑战性的交通相关推理任务:

TrafficQA数据集包含62,535个QA对和10,080个交通场景视频。
与现有视频QA数据集不同的是,TrafficQA关注的是野外复杂交通场景的推理,其中基于不同的真实交通视频介绍了6个具有挑战性的交通事件推理任务。
Videos。作者采用线上采集和线下捕捉相结合的方式收集视频,以覆盖各种真实的交通场景。在网络视频采集方面,基于不同国家的各种视频分享平台,包括但不限于YouTube、LiveLeak、Twitter、BiliBili等来增加视频采集的多样性。因此,从这些在线来源收集了九千多个视频。至于离线视频捕捉,一组视频是由志愿者通过手持摄像机拍摄的,另一组是从车载视频录像机获取的。然后对这两组离线视频进行检查,并将其剪辑成大约一千个视频片段。
通过对线上视频和线下视频的梳理,作者共获得了10,080个视频,包含了不同方面的差异,包括:a)不同的天气(晴天/雨天/刮风/下雪);b)不同的时间(白天/夜晚);c)不同的道路情况(拥堵/稀疏,城市道路/乡村道路);d)不同的交通事件(事故、车辆转弯、行人行为、红绿灯等);e)不同的视频视角(监控摄像头视角/车载视频视角/手持摄像头视角);f)不同的片段长度(从1秒到70秒)。
QA对。首先,向标注员解释了这6项任务。为了确保他们充分理解任务的设计原则,为他们准备了多个示例问题,以确定问题属于哪一个任务。之后,每一个标注员都提供了一批视频文件夹,每个文件夹包含100个剪辑,这些剪辑是从完整的视频集中随机选择的。标注员被要求为每部视频设计至少3个关于推理任务的问题。作者没有对问题格式施加限制,以鼓励标注员保持他们的QA对多样化。具体地说,作者鼓励他们重新表述相似的问题或候选答案,以推动模型学习QA对的底层语义,而不是表面的语言相关性。为了确保QA对的质量,作者每周对QA标注进行交叉检查。此外,作者不断监控QA集合中不同任务的分布,以保持作者数据集的平衡和多样性。

在图2中作者展示了作者的TrafficQA数据集的统计数据。图2(a)显示了由单词数测量的问题长度分布。问题平均长度为8.6字。图2(b)显示了根据起始词分类的各种问题类型,这暗示了作者数据集中问题的多样性。图2©是根据推理任务划分的问题。作者的数据集涵盖了广泛的交通相关推理任务,需要视频中各种层次的时空理解和因果推理。
在处理视频推理时,一种常用的解决方案是观看完整的视频并仔细分析整个事件信息。以这种方式,通常可以在整个视频上应用固定的计算架构以解决每个问题。然而,使用固定的网络架构来处理视频QA任务通常是计算量大且消耗能量的,因为用于推理的视频序列可能很长并且包含大量的帧供处理。
回顾一下,作为人类,为了分析一个视频中的事件,作者可能没有足够的耐心去仔细检查整个视频中的帧,相反,可能采用一种自适应的信息“foraging”策略。具体来说,作者可以使用一种“动态”推理方式,在序列上来回跳过,根据任务逐步推断和选择一些有用的帧。此外,对于挑选出来的帧,作者可以仔细地检查其中的几个帧,同时检查其他帧。这样一种动态的、自适应的感知习惯使作者从全神贯注地观看整个视频中解脱出来,并且常常能够在很小的帧数下快速而又非常准确地进行视频推理。这样的动态推理方案避免了对视频中不相关片段的特征提取,从而显著降低了实现可靠和高效推理的总体计算成本。值得注意的是,选择一个glimpse帧的确定和每个glimpse的计算粒度的决定本质上都是离散的操作,对优化来说不是琐碎的。为了解决这个问题,本文还引入了一个有效的联合Gumbel-Softmax机制,使Eclipse框架具有完全的差异性和端到端的可训练性。
本文首次提出了一种新的动态推理过程,第一个对视频QA进行动态推理和自适应计算调整的模型,它利用一个有效的glimpse策略,以文本和视觉上下文信息为指导,用于glimpse帧的选择和计算粒度的确定。以实现可靠、高效的因果推理和视频QA。本文还引入了联合Gumbel-Softmax操作来联合优化这两个决策。
与现有的视频问答方法不同的是,作者的Eclipse模型研究了学习一个有效的glimpse策略的方向,用于自适应推理,以实现具有计算效率的重复推理。

如图3所示。作者的网络不是在每个视频和问题上使用固定的计算架构,而是学会在每个推理步骤中动态跳到并选择一个有用的视频帧。此外,作者的网络自适应地决定所选帧的特征计算粒度(即粗或细)。为了实现这一过程,在每一个推理步骤中,作者的网络利用包括QA对、当前选择的帧和历史线索在内的指导信息进行动态推理。
如图3所示,在作者的网络中,为了为交互模块提供QA信息,QA库存储QA对的表示。在每个推理步骤中,为了辅助选择帧和相应特征粒度的动态推理,交互模块利用QA信息、当前选择的帧和来自以往观察到的帧的信息导出一个表达表示,然后作为下游模块执行的动态推理过程的输入,包括用于输出推理结果的预测模块和用于动态确定下一步要观察到的帧的 Glimpse-Determination Module。另一方面,退出策略模块也利用该表示自适应地决定在当前推理步骤是否可以退出推理过程。通过这种动态的、循环的推理过程,作者的网络能够以显著的计算效率得到可靠的关于在帧的使用和特征的计算量两个方面的答案预测。
网络模块如下:
考虑到每个问题的候选答案的数量在作者的数据集中不是固定的,作者使用二进制和多选设置来评估作者的网络的性能。在二进制情况下(表示为Setting-1/2),对模型的输入是一个带有答案的问题,模型需要预测这个答案的正确性。在多选设置中(表示为Setting-1/4),模型期望从4个候选答案(即其中3个不正确)中选出正确答案。这两个实验设置可以被处理为二元和四类分类问题。
作者从一个预训练的ResNet-101模型的倒数第二层计算特征作为细粒度帧特征,而一个预训练的Mo-BilenetV2作为轻量级CNN来提取粗粒度特征。在QA库中,作者使用Glove对QA文本进行嵌入处理,然后使用一个150维的BiLSTM隐藏状态来编码文本序列。对于交互LSTM,隐藏状态的维数为300。作者使用Pytorch实现了该框架,并采用了Adam学习率为3e-4,重量衰减为1e-5。Exit-Policy中的µ,在损失函数中设为0.1,在损失函数中设为0.01。设置初始 temperature为5,并以一个-0.045的指数衰减因子逐渐anneal。根据评估统计,对于每个测试视频,作者的网络在Nvidia RTX 2080TI GPU上显示了一个非常快的16ms的推断速度。
将作者的网络与以下基线进行比较。
Text-only models。这些模型只依赖于文本信息而没有视觉输入,在作者的交通中是用来评估语言偏见的相对薄弱的基线。Qtype (random)从答案空间中随机选择一个答案。QE-LSTM使用Glove嵌入输入的问题,然后用LSTM进行编码。最后的LSTM隐藏状态被传递给MLP,用于预测正确答案。与只使用问题的QE-LSTM不同,QA-LSTM使用LSTM对问题嵌入和答案嵌入进行编码,最后的隐藏状态用于预测答案。
Text+video models。作者评估以下同时需要视频和文本输入的模型。VIS+LSTM使用LSTM对图像表示和文本特征进行编码。由于原始方法以单个图像作为输入,作者通过对视频中所有采样帧的特征进行平均作为视觉输入来改进该方法。Avgpooling使用具有编码QA特征的每个帧来计算每个帧的预测。然后作者对所有帧预测执行均值池,以获得最终结果。CNN+LSTM使用两个LSTM分别对视频序列和QA文本进行编码。最后的两个隐藏状态被连接以预测正确的答案。I3D+LSTM利用I3D网络提取视频运动特征,再与LSTM编码的QA文本特征融合,计算模型预测。TVQA是一个多流网络,融合来自不同模式的输入特征来回答问题。HCRN采用一种高效的条件关系网络对视频推理结构进行建模。BERT-VQA利用BERT对视觉信息和语言信息进行联合编码来预测答案。

表2中的结果显示了TrafficQA中最小的语言偏差,因为纯文本基线与随机选择基本相同。相比之下,使用视频输入的模型比仅使用文本的基线获得明显更高的精度。这表明,为了解决作者的数据集中的推理任务,模型需要将视觉内容与语言线索关联起来,从而推断出正确的答案。为了公平地比较计算效率,作者选择需要视频输入的模型来计算每个视频的GFLOPs,因为视觉特征提取消耗大量的计算预算,并且GFLOPs的度量与硬件配置无关。结果表明,Eclipse实现了现有的推理精度,并显著提高了计算效率。与传统的视频问答方法相比,该模型通过动态因果推理,有效地利用了视频事件的时空和逻辑结构,以较小的帧用量和有效的特征计算量得到了正确的答案。另外,作者还邀请了三位没有看过视频和问题的志愿者来选择正确的答案,作者用平均预测准确率作为Human表现。神经网络与人类性能之间的差异表明了作者的数据集的挑战性和在视频推理领域进一步研究的必要性。

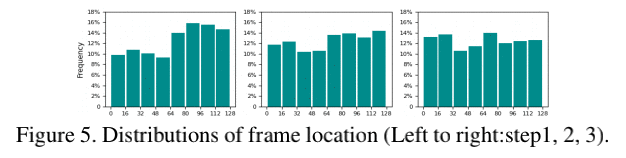
如表3所示,与仅使用细粒度特征的模型变体相比,通过采用粒度策略在每一步自适应地决定所选帧的特征粒度,作者的网络达到了几乎相同的精度,但使用了较低的计算成本。该网络的推理精度也明显高于只使用粗粒度特征的方法。这些结果表明了作者的粒度策略的有效性,它为最有用的帧选择了细粒度特征,为不太重要的帧选择了粗粒度特征。此外,作者去掉了skip-policy,并在每一步简单地统一采样帧。如表4所示,作者的Eclipse以较小的计算成本取得了最好的性能。这表明作者的skip-policy通过动态地选择有用的帧来有效地降低了计算成本。此外,作者给出了作者网络前三个推理步骤的帧位置分布,如图5所示,作者的网络按照作者的预期为不同的视频动态地选择帧。作者还研究了Exit-Policy模块,并将其与推理方法进行了比较,直到最后的推理步骤。表5的结果表明,通过自适应推理,作者的模型达到了最佳的精度与计算比。在图4中,作者进一步展示了数据集中的一个定性示例,以展示Eclipse如何执行动态和高效的推理。

创建了一个新的视频QA数据集TrafficQA,重点研究交通事件的视频推理。在作者的数据集中,作者介绍了6个需要各种层次因果推理的推理任务。此外,作者还提出了Eclipse视频问答网络。通过学习动态的glimpse策略和自适应的Exit-Policy,作者的网络获得了优异的性能和显著的计算效率。






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有