作者:朱衅赝 | 来源:互联网 | 2023-08-08 10:32
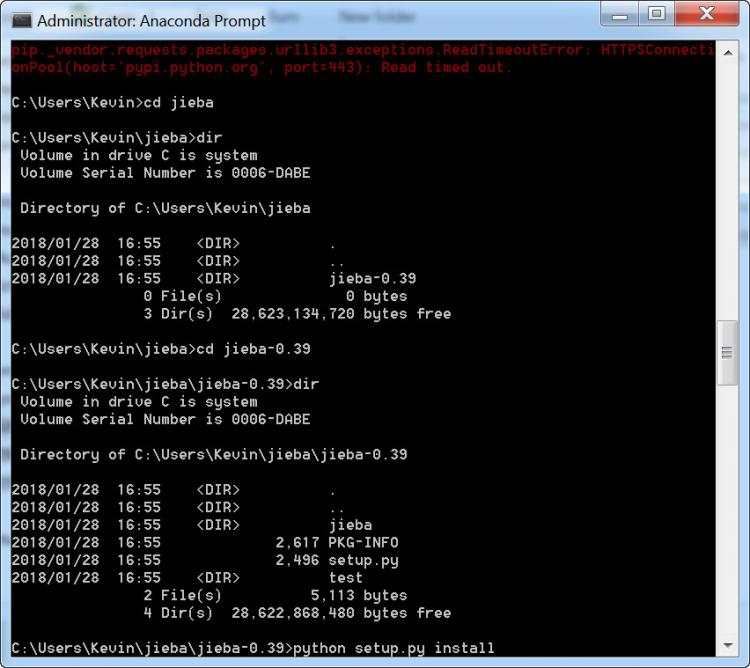
CNN实现时间序列预测工具集Python3.8PyTorch1.10Jupyter6.3.0具体安装过程就不多赘述了:)数据集介绍本次实验使用的数据集是关于乙醇年销售额数据,该数据
CNN实现时间序列预测
工具集
Python3.8
PyTorch1.10
Jupyter6.3.0
具体安装过程就不多赘述了:)
数据集介绍
本次实验使用的数据集是关于乙醇年销售额数据,该数据集是一个单变量时间序列,数据集链接在本文末尾。
数据集格式: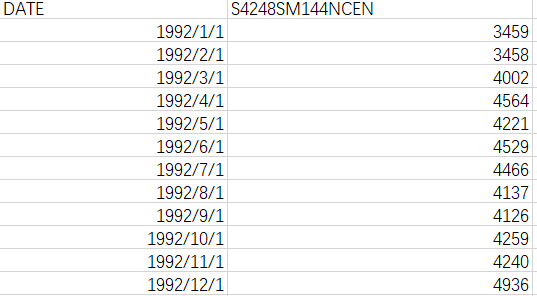
数据处理
加载数据集import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
Dataset = pd.read_csv('..\data\Alcohol_Sales.csv',
index_col=0,parse_dates=True)
查看数据集len(Dataset)
Dataset.head()

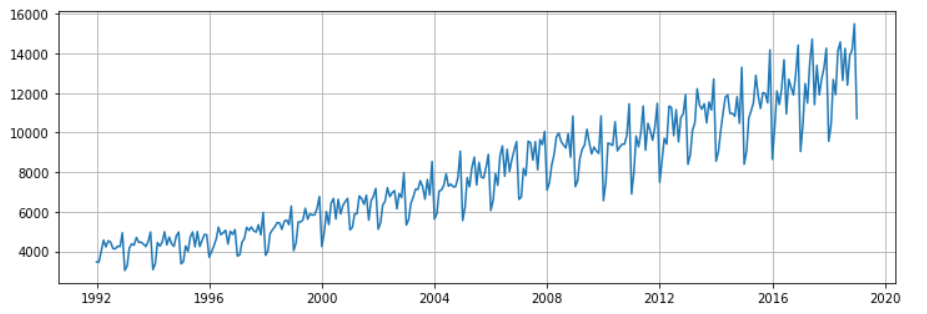
plt.figure(figsize=(12,4))
plt.grid(True)
plt.plot(df['S4248SM144NCEN'])
plt.show()
数据预处理y = df['S4248SM144NCEN'].values.astype(float)
test_size = 12
# 划分训练和测试集,最后12个值作为测试集
train_set = y[:-test_size]
test_set = y[-test_size:]
from sklearn.preprocessing import MinMaxScaler
# 归一化处理
scaler = MinMaxScaler(feature_range=(-1, 1))
train_norm = scaler.fit_transform(train_set.reshape(-1, 1))
归一化的具体作用是归纳统一样本的统计分布性。归一化在0-1之间是统计的概率分布,归一化在-1–+1之间是统计的坐标分布。归一化有同一、统一和合一的意思。无论是为了建模还是为了计算,首先基本度量单位要同一,神经网络是以样本在事件中的统计分别几率来进行训练(概率计算)和预测的,且sigmoid函数的取值是0到1之间的,网络最后一个节点的输出也是如此,所以经常要对样本的输出归一化处理。归一化是统一在0-1之间的统计概率分布,当所有样本的输入信号都为正值时,与第一隐含层神经元相连的权值只能同时增加或减小,从而导致学习速度很慢。另外在数据中常存在奇异样本数据,奇异样本数据存在所引起的网络训练时间增加,并可能引起网络无法收敛。为了避免出现这种情况及后面数据处理的方便,加快网络学习速度,可以对输入信号进行归一化,使得所有样本的输入信号其均值接近于0或与其均方差相比很小。
创建训练集# 转换成 tensor
train_norm = torch.FloatTensor(train_norm).view(-1)
window_size = 12
#将数据按window_size一组分段,每次输入一段后,会输出一个预测的值y_pred
#y_pred与每段之后的window_size+1个数据作为对比值,用于计算损失函数
#例如前5个数据为(1,2,3,4,5),取前4个进行CNN预测,得出的值与(5)比较计算loss
#这里使用每组13个数据,最后一个数据作评估值,即window_size=12
def input_data(seq,ws):
out = []
L = len(seq)
for i in range(L-ws):
window = seq[i:i+ws]
label = seq[i+ws:i+ws+1]
out.append((window, label))
return out
train_data = input_data(train_norm,window_size)
# 打印一组数据集
train_data[0]
建立CNN模型
对于CNN处理时序数据,通常使用一维卷积网络Conv1d
本实验模型结构:卷积层通过 2*2 卷积核将1维数据展开为3维张量,使用激活函数ReLU将小于0的数据剔除,再使用全连接层将3维张量变为1维张量,接着通过两次Linear线性变换得到最后预测值。
卷积层-》ReLU-》全连接层-》线性层-》线性层
import torch
import torch.nn as nn
class CNNnetwork(nn.Module):
def __init__(self):
super().__init__()
self.conv1d = nn.Conv1d(1,64,kernel_size=2)
self.relu = nn.ReLU(inplace=True)
self.Linear1= nn.Linear(64*11,50)
self.Linear2= nn.Linear(50,1)
def forward(self,x):
x = self.conv1d(x)
x = self.relu(x)
x = x.view(-1)
x = self.Linear1(x)
x = self.relu(x)
x = self.Linear2(x)
return x
数据训练
import time
torch.manual_seed(101)
model =CNNnetwork()
# 设置损失函数,这里使用的是均方误差损失
criterion = nn.MSELoss()
# 设置优化函数和学习率lr
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 设置训练周期
epochs = 100
model.train()
start_time = time.time()
for epoch in range(epochs):
for seq, y_train in train_data:
# 每次更新参数前都梯度归零和初始化
optimizer.zero_grad()
# 注意这里要对样本进行reshape,
# 转换成conv1d的input size(batch size, channel, series length)
y_pred = model(seq.reshape(1,1,-1))
loss = criterion(y_pred, y_train)
loss.backward()
optimizer.step()
print(f'Epoch: {epoch+1:2} Loss: {loss.item():10.8f}')
print(f'\nDuration: {time.time() - start_time:.0f} seconds')
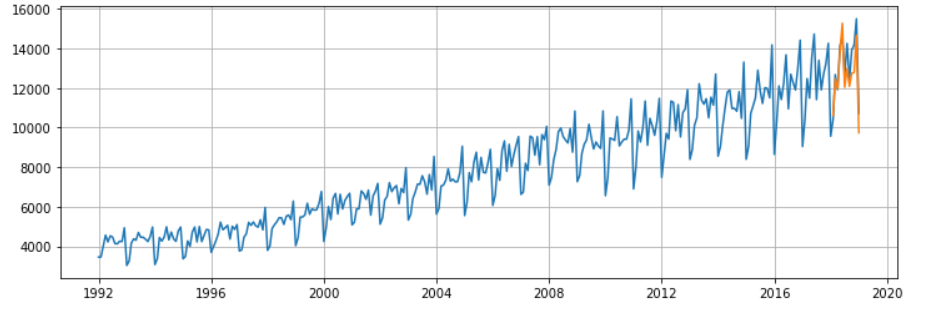
数据预测
future = 12
# 选取序列最后12个值开始预测
preds = train_norm[-window_size:].tolist()
# 设置成eval模式
model.eval()
# 循环的每一步表示向时间序列向后滑动一格
for i in range(future):
seq = torch.FloatTensor(preds[-window_size:])
with torch.no_grad():
preds.append(model(seq.reshape(1,1,-1)).item())
# 逆归一化还原真实值
true_predictions = scaler.inverse_transform(np.array(preds[window_size:]).reshape(-1, 1))
# 对比真实值和预测值
plt.figure(figsize=(12,4))
plt.grid(True)
plt.plot(df['S4248SM144NCEN'])
x = np.arange('2018-02-01', '2019-02-01', dtype='datetime64[M]').astype('datetime64[D]')
plt.plot(x,true_predictions)
plt.show()
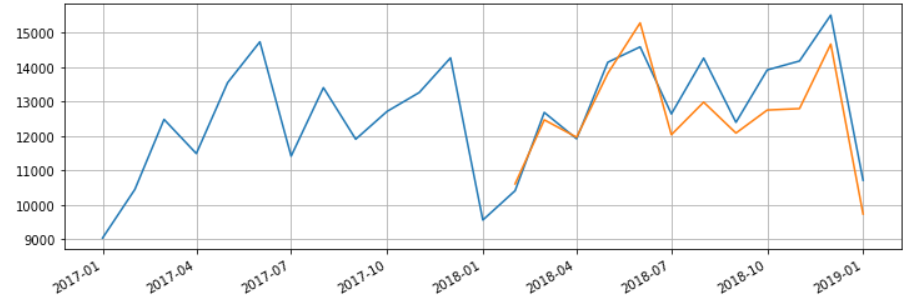
放大看一下
fig = plt.figure(figsize=(12,4))
plt.grid(True)
fig.autofmt_xdate()
plt.plot(df['S4248SM144NCEN']['2017-01-01':])
plt.plot(x,true_predictions)
plt.show()
总结
可以看出CNN处理时间序列数据表现得也可以,可以考虑结合CNN-LSTM进行实验。
第一次写文,若有错误,欢迎批评指正(0.0)!
数据集及源码
链接:https://pan.baidu.com/s/1Hwl8usFf4xpNAhV3jtLwhQ
提取码:s58a
来源:freshfish丶






 京公网安备 11010802041100号
京公网安备 11010802041100号