 由 DarwinAI 和滑铁卢大学的人工智能研究人员设计的一种新的神经网络架构,将使低功耗、低算力计算设备执行图像分割任务成为可能。图像分割是确定图像中目标物体的边界和区域的过程。人类可以毫不费力地进行图像分割,但对机器学习系统来说,这仍然是的一个关键挑战。图像分割对移动机器人、自动驾驶汽车和其他必须与现实世界互动的人工智能系统至关重要。此前的难题是,图像分割还需要大型的、计算密集型神经网络。这使得在没有云服务器连接的情况下很难运行这些深度学习模型。在最新的研究成果中,DarwinAI 和滑铁卢大学的科学家们已经成功地创建了一个神经网络,它提供了图像分割的近乎最优解,并且足够小,适合资源有限的设备。这个名为 AttendSeg 的神经网络在论文中有详细介绍,该论文已被计算机视觉领域的顶会 CVPR 2021 录用。图像分类、检测和分割人们对机器学习系统越来越感兴趣的一个关键原因是它们可以解决计算机视觉中的问题。机器学习在计算机视觉中的一些最常见的应用包括图像分类、目标检测和图像分割等。图像分类决定了某一类型的对象是否存在于图像中。目标检测是进一步的图像分类,并提供被检测目标所在的边界框。图像分割有两种方式:语义分割和实例分割。语义分割把图像中每个像素赋予一个类别标签(比如汽车、人、建筑、地面、天空、树等)。实例分割将每种类型对象的各个实例分开。在实际应用中,分割网络的输出通常用着色像素表示。图像分割是迄今为止最复杂的分类任务类型。
由 DarwinAI 和滑铁卢大学的人工智能研究人员设计的一种新的神经网络架构,将使低功耗、低算力计算设备执行图像分割任务成为可能。图像分割是确定图像中目标物体的边界和区域的过程。人类可以毫不费力地进行图像分割,但对机器学习系统来说,这仍然是的一个关键挑战。图像分割对移动机器人、自动驾驶汽车和其他必须与现实世界互动的人工智能系统至关重要。此前的难题是,图像分割还需要大型的、计算密集型神经网络。这使得在没有云服务器连接的情况下很难运行这些深度学习模型。在最新的研究成果中,DarwinAI 和滑铁卢大学的科学家们已经成功地创建了一个神经网络,它提供了图像分割的近乎最优解,并且足够小,适合资源有限的设备。这个名为 AttendSeg 的神经网络在论文中有详细介绍,该论文已被计算机视觉领域的顶会 CVPR 2021 录用。图像分类、检测和分割人们对机器学习系统越来越感兴趣的一个关键原因是它们可以解决计算机视觉中的问题。机器学习在计算机视觉中的一些最常见的应用包括图像分类、目标检测和图像分割等。图像分类决定了某一类型的对象是否存在于图像中。目标检测是进一步的图像分类,并提供被检测目标所在的边界框。图像分割有两种方式:语义分割和实例分割。语义分割把图像中每个像素赋予一个类别标签(比如汽车、人、建筑、地面、天空、树等)。实例分割将每种类型对象的各个实例分开。在实际应用中,分割网络的输出通常用着色像素表示。图像分割是迄今为止最复杂的分类任务类型。
图像分类 vs 对象检测 vs 语义分割卷积神经网络(CNN)是计算机视觉任务中常用的深度学习架构,其复杂性通常用其内部参数数量来衡量。神经网络的参数越多,它需要的内存和计算能力就越大。RefineNet 是一种流行的语义分割神经网络,包含超过 8500 万个参数。其中,每个参数 4 字节,这意味着使用 RefineNet 至少需要 340 兆字节(兆字节 = 2²⁰字节)的内存才能运行神经网络。神经网络的性能在很大程度上取决于可以执行快速矩阵乘法的硬件,也就是说,必须将模型加载到显卡或某些其他并行计算单元上,而这些并行计算单元的内存比计算机的 RAM 更为稀缺。边缘设备的机器学习模型由于其硬件要求,大多数图像分割应用程序都需要网络连接将图像发送到可以运行大型深度学习模型的云服务器才能运行。因此,云连接可能会限制图像分割算法的使用场景。例如,如果无人驾驶飞机或机器人将在没有互联网连接的环境中运行,那么图像分割将成为一项艰巨的任务。在其他领域,人工智能不得不在敏感环境中工作,将图像发送到云服务器将受到隐私和安全性约束。在机器学习模型需要实时响应的应用程序中,由往返于云服务器造成的延迟也是一个难题。还有一点需要重视的是,网络硬件本身会消耗大量电能,而向云服务器发送恒定的图像流可能会增加电池负担。综合所有这些原因,边缘 AI 和微型机器学习模型(TinyML)成为学术界和应用 AI 领域的关注热点和研究热点。微型机器学习模型的目标是创建可以在内存和功耗受限的设备上运行而无需连接到云服务器的机器学习模型。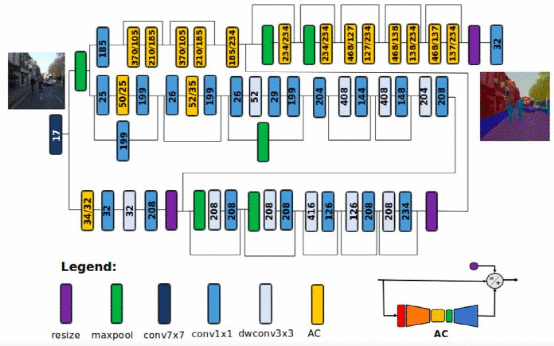 AttendSeg 语义分割神经网络的体系结构通过 AttendSeg,DarwinAI 和滑铁卢大学的研究人员试图解决边缘设备上的语义分割挑战。“推进微型机器学习模型领域的愿望和 DarwinAI 的市场需求推动了 AttendSeg 的相关研究,” DarwinAI 联合创始人、滑铁卢大学副教授 Alexander Wong 说;“高效的边缘图像分割方法有许多工业应用,我认为正是这种反馈和市场需求推动了这种研究。”这篇论文将 AttendSeg 描述为 “一个为微型机器学习模型应用量身定制的低精度、高度紧凑的深层语义分割网络”。AttendSeg 深度学习模型执行语义分割的精确度几乎与 RefineNet 相当,同时将参数数量减少到 119 万个。有趣的是,研究人员还发现,将参数的精度从 32 位(4 字节)降低到 8 位(1 字节)不会导致显著的性能损失,同时使他们能够将 AttendSeg 的内存占用空间缩小四倍。该模型需要的内存仅略高于 1 兆字节,这足以适合大多数边缘设备。“根据我们的实验,[8 位参数] 不会对该网络的通用性构成限制,而且说明了在这种情况下低精度可能会非常有益(只需要使用所需的精度即可),Wong 说。
AttendSeg 语义分割神经网络的体系结构通过 AttendSeg,DarwinAI 和滑铁卢大学的研究人员试图解决边缘设备上的语义分割挑战。“推进微型机器学习模型领域的愿望和 DarwinAI 的市场需求推动了 AttendSeg 的相关研究,” DarwinAI 联合创始人、滑铁卢大学副教授 Alexander Wong 说;“高效的边缘图像分割方法有许多工业应用,我认为正是这种反馈和市场需求推动了这种研究。”这篇论文将 AttendSeg 描述为 “一个为微型机器学习模型应用量身定制的低精度、高度紧凑的深层语义分割网络”。AttendSeg 深度学习模型执行语义分割的精确度几乎与 RefineNet 相当,同时将参数数量减少到 119 万个。有趣的是,研究人员还发现,将参数的精度从 32 位(4 字节)降低到 8 位(1 字节)不会导致显著的性能损失,同时使他们能够将 AttendSeg 的内存占用空间缩小四倍。该模型需要的内存仅略高于 1 兆字节,这足以适合大多数边缘设备。“根据我们的实验,[8 位参数] 不会对该网络的通用性构成限制,而且说明了在这种情况下低精度可能会非常有益(只需要使用所需的精度即可),Wong 说。
实验
表明 AttendSeg 提供了最佳的语义分割方案,同时减少了参数的数量和内存占用计算机视觉的 “注意力冷凝器”AttendSeg 利用 “注意力冷凝器”(Attention condensers)来缩小模型尺寸而不影响性能。Attention 机制是通过关注重要信息来提高神经网络效率的一系列机制。自我关注技术已经成为自然语言处理领域的福音。它们是 Transformers 深度学习架构成功的决定性因素。虽然之前的架构(如递归神经网络)对长序列数据的能力有限,Transformers 使用自我注意机制来扩大其范围。深度学习模型,如 GPT-3,利用 Transformers 和自我注意机制,输出长串的文本,并在长时间内保持连贯性。人工智能研究人员还利用 Attention 机制来提高卷积神经网络的性能。去年,Wong 和他的同事引入了 “注意力冷凝器” 作为一种资源高效的注意力机制,并将其应用于图像分类器机器学习模型。Wong 说:“注意力冷凝器使深度神经网络架构非常紧凑,但仍然可以实现高性能,这使得它们非常适合边缘设备或微型机器学习模型应用。”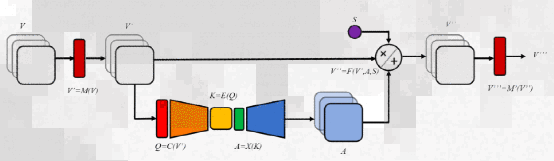
注意力冷凝器以记忆有效的方式提高了卷积神经网络的性能由机器驱动的神经网络设计设计 TinyML 神经网络的关键挑战之一是找到性能最佳的体系结构,同时又要符合目标设备的计算预算。为了解决这一挑战,研究人员使用了 “生成合成” 技术,这是一种机器学习技术,可以基于特定的目标和约束创建神经网络架构。基本上,研究人员为机器学习模型提供了一个问题空间,让它发现最佳组合,而不是手动摆弄各种配置和架构。“由机器驱动的设计过程 (生成合成) 需要人类提供一个初始设计原型和人类指定的预期操作要求 (例如尺寸、精度等),而 MD 设计过程则负责从中学习,并根据操作要求、任务和手头的数据量身定制最佳架构设计。”Wong 说。在实验中,研究人员使用机器驱动的设计为 Nvidia Jetson 调试优化 AttendSeg。Nvidia Jetson 是机器人和边缘人工智能应用程序的硬件套件,但是 AttendSeg 不仅限于 Jetson。Wong 说:“从本质上讲,与先前提出的网络相比,AttendSeg 神经网络能在大多数边缘硬件上快速运行。但是,如果要生成针对特定硬件量身定制的 AttendSeg,则可以使用机器驱动的设计探索方法为其创建一个新的高度定制化的神经网络。”AttendSeg 在自动驾驶无人机,机器人和车辆等方面具有明显的应用,其中语义分割是导航的关键。设备上的语义分割可以有更多的应用。“这种高度紧凑,高效的语义分割神经网络可以用于各种各样的场景,包括制造(零件检查 / 质量评估,机器人控制)、医疗应用(细胞分析,肿瘤识别),卫星遥感应用(土地覆盖物识别)和移动应用(用于增强现实)。” Wong 说。Reference:1、
https://arxiv.org/abs/2104.14623/2、
https://bdtechtalks.com/2021/05/07/attendseg-deep-learning-edge-semantic-segmentation/









 京公网安备 11010802041100号
京公网安备 11010802041100号