词法分析,是编译器的第一个模块,也是最简单的模块。
最简单,指的是相对于编译器这种大型程序而言,与一般的代码相比还是有点复杂的。
关于词法分析的简介,可以看之前的文章:
词法分析器的简单思路
按照通常的C代码惯例,前缀暂时设置为scf,Simple Compiler Framework,简单编译器框架。
它所需的基本数据结构,就是动态字符串和双向链表,前两篇文章已经做了简单的代码介绍。
用C语言写个动态字符串
用C语言实现Linux风格的双向链表
首先,需要定义一个枚举类型,说明词法分析要支持的单词类型,即各种运算符、常量、标识符。
因为是从C和C++中抽取了容易实现的那部分语法,单词类型还是很多的,见如下几张图片:
第一张图,是各种运算符的类型定义,与流行的编程语言基本一样。
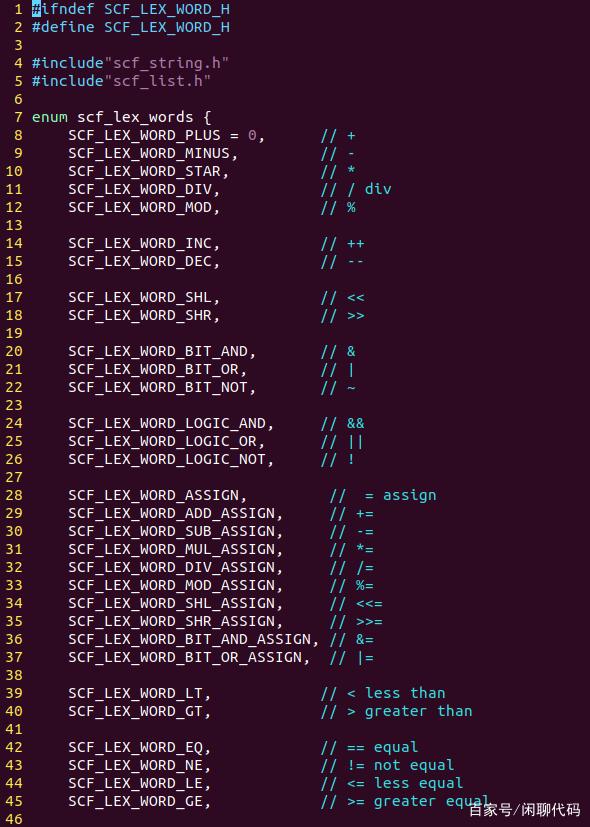 各种运算符
各种运算符
第二张,大小括号、分号、逗号、冒号等语法标示符号,箭头、点号等运算符。
箭头->,一般表示指针。点号,表示取类的成员。
三个点号,表示函数的动态参数,例如printf(const char* fmt, ...)在词法分析时就会用到。
空格,space,在词法分析时作为分隔符之一。它是不需要传递到语法分析阶段的,用完之后需要忽略掉。
EOF,表示源代码文件的结尾,fgetc()之类的函数在文件结束时会返回这个值。把它也作为一个单词,用于提示词法分析过程的结束。
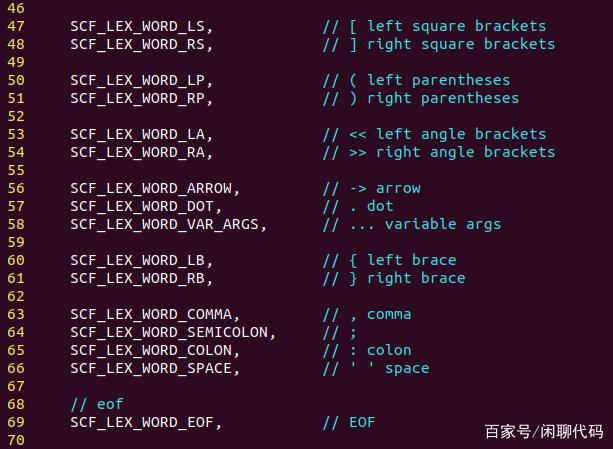 括号之类的也算运算符
括号之类的也算运算符
第三张,主要是用于代码流程控制的关键字。
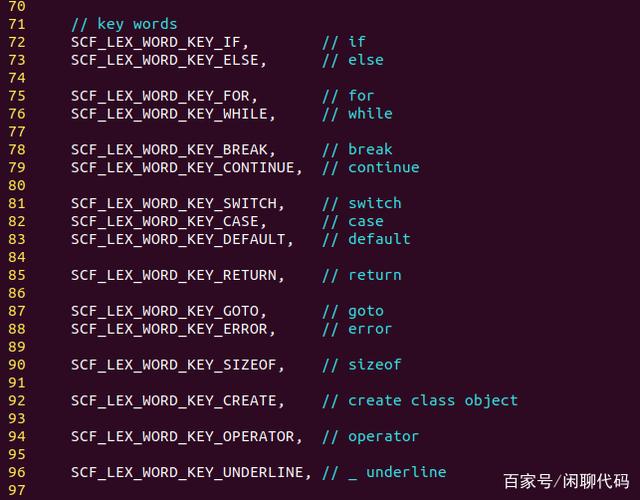 流程控制的关键字
流程控制的关键字
第四张,是用于类型定义的关键字。
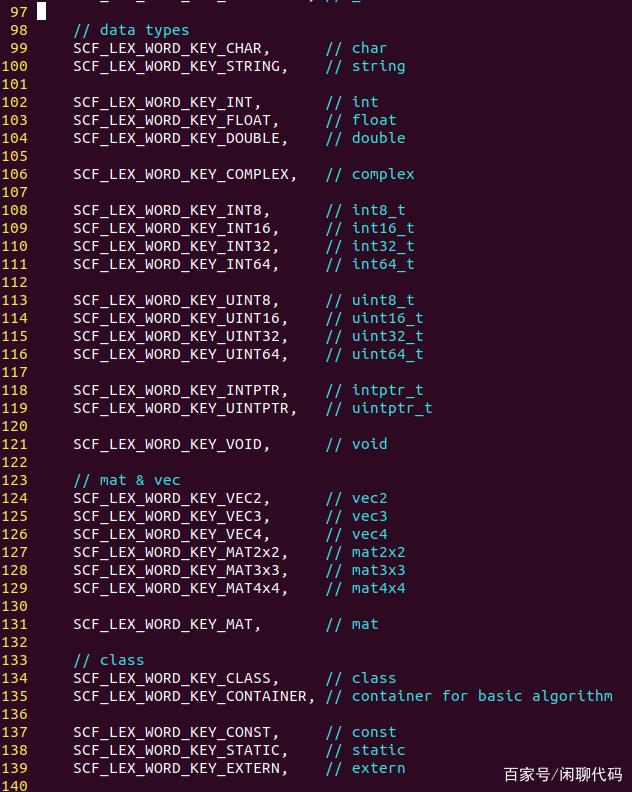 数据类型的关键字
数据类型的关键字
第五张,也是这个枚举的最后一部分,是常量和标识符。
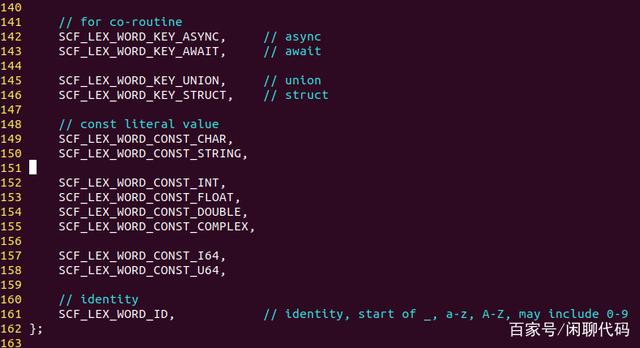 其他
其他
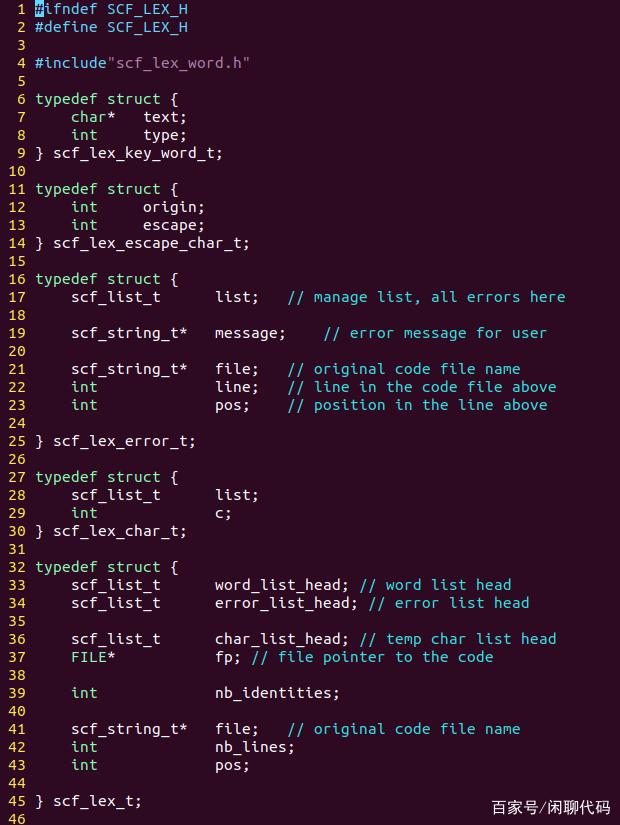
定义完了这个枚举,就可以定义单词的数据结构,如下图:
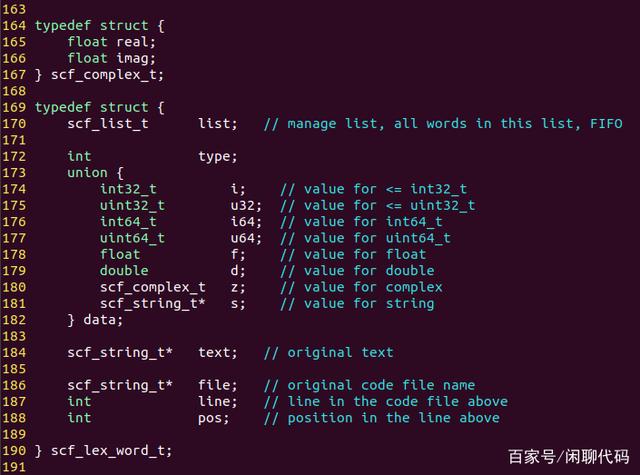
list,用于把它挂载到词法分析器的链表上,按照先进先出顺序(FIFO),以备后续的语法分析时读取。
type,填写为上面那个枚举的其中之一,用于表示这个单词的类型。
data,用于存储常量的值,可以是常量数字或者常量字符串。
text,用于存储单词的原始文本,即这个词的源代码。
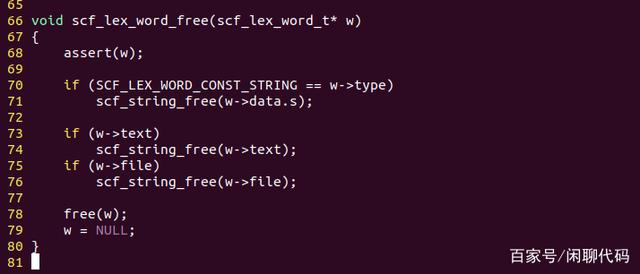
file、line、pos,用于存储单词所在的源码文件名,行号,行内的位置,用于打印错误信息。
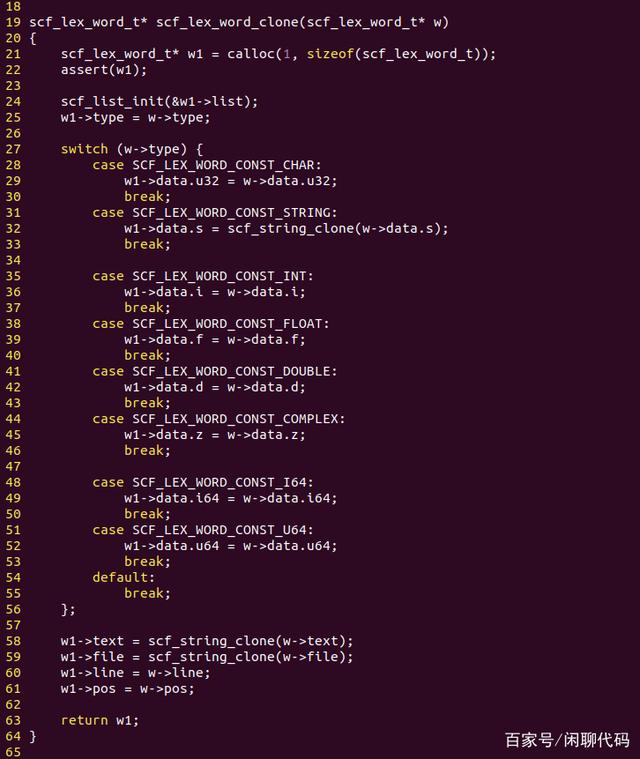
接下来定义几个与单词相关的函数,alloc()、clone()、free(),等等。
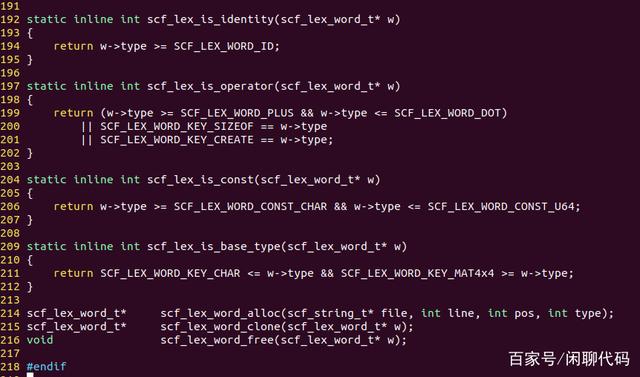
然后在C文件里实现这三个函数。
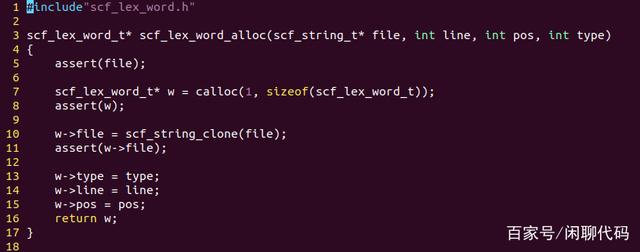
最后,定义词法分析器(lexer)的数据结构,scf_lex_t。
scf_lex_key_word_t,用于定义关键字的源码字符串,和关键字对应的单词类型。
在一门编程语言中,关键字是固定的。
如果在词法分析时获得的字符串,能在关键字列表里查到,那么它就是个关键字。
关键字列表,就是scf_lex_key_word_t类型的数组。
scf_lex_escape_char_t,用于转义字符,一般是\r \n \t \0这4个,以\表示接下来的一个字符是转义字符。
如果能在转义字符列表里查到,要把这两个字符转化为对应的转义ascii码。例如'\n'要转化为一个字节的整数10。
转义字符列表,就是scf_lex_escape_char_t类型的数组。
scf_lex_error_t,用于存储错误信息。因为不一定发现一个错误就立即终止分析(打印错误信息),有可能积累到一定的数量之后再一起打印出来,所以它用于保存错误信息。
scf_lex_char_t,用于表示从源码文件里读取的一个字符。
词法分析,是一个字符一个字符的读取。
如果发现当前字符是下一个单词的,那么就要把它放回去,等分析下一个单词时再把它取出来,所以需要一个链表挂载暂时被放回的单词。
不能真把它写回源码文件再读出来,fgetc()之后文件指针已经变了,再写回去会覆盖掉下一个字符的。把它挂载一个链表上,优先从链表读,链表为空的时候再读源文件,是比较好的处理方法。
从当前单词的末尾字符多查看一个字符(即下一个单词的第一个字符),才能确定当前单词的终止位置,这叫LL1下降分析。这个多查看的字符,也叫终止符。
(这里我不是故意黑龙书,而是就这么点事,它居然真写的云山雾罩,让人一头雾水,读不下去。)
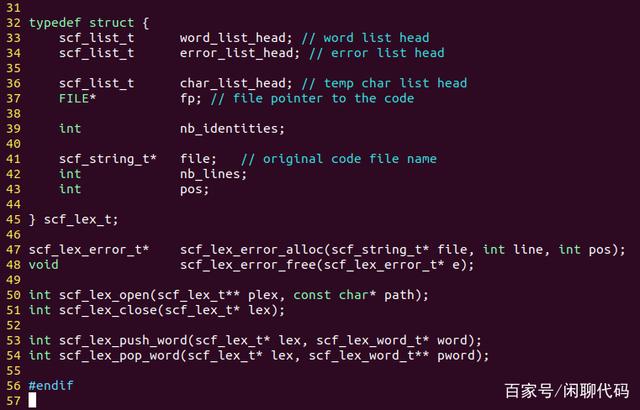
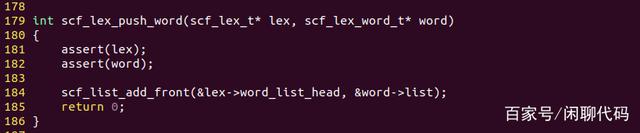
scf_lex_t,词法分析器的数据结构,它有open()、close()、push_word()、pop_word()这4个函数。
其中push_word()和pop_word()是给语法分析器(parser)用的,语法分析时也存在LL1下降分析的场景,push_word()用于放回一个单词。
word_list_head,用于存储语法分析时这个临时被放回的单词,与词法分析的场景类似。
error_list_head,用于存储还没有打印的错误信息。
char_list_head,用于存储临时被放回的字符。
FILE* fp,源码文件的文件指针,从它这里读取字符。
nb_identities,标识符的个数。随着分析过程这个值是不断增加的,要根据它的值给获取的每一个标识符编不同的号码。
所有数据结构的定义说完了,接下来是代码实现。
scf_lex_open()的path是源码文件的路径,二级指针plex用于返回创建的词法分析器。
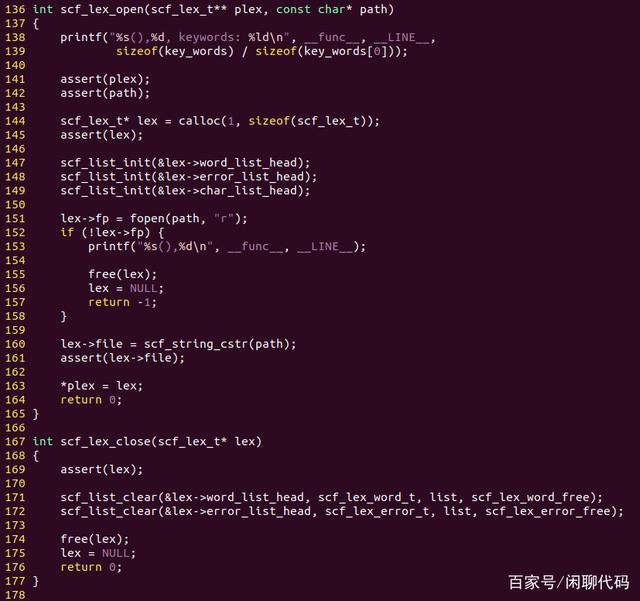
open、close、push_word,都比较简单,真正的词法分析在pop_word()函数里。
语法分析器(parser)在需要一个单词时,就调用词法分析器(lexer)的pop_word()函数,获取下一个单词。
之所以这么设计,而不是先完成整个源码文件的词法分析,是为了减少单词的库存,毕竟分析完的单词也是要占内存的。如果源码文件比较大,万一内存不够了就尴尬了,所以采取现使用现生产的JIT模式,暂时用不着的单词就让它在源码文件里存着。
在具体的词法分析之前,先准备关键字列表和转义字符列表。
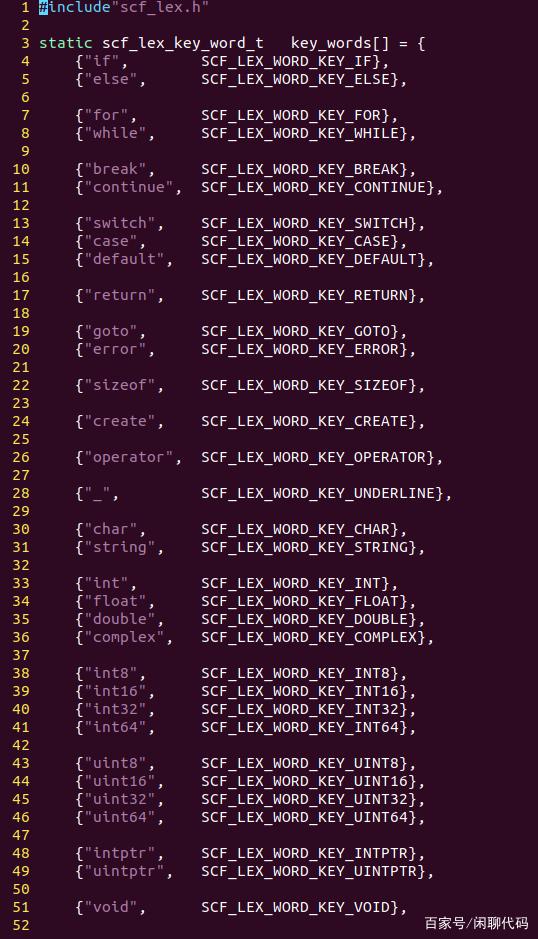
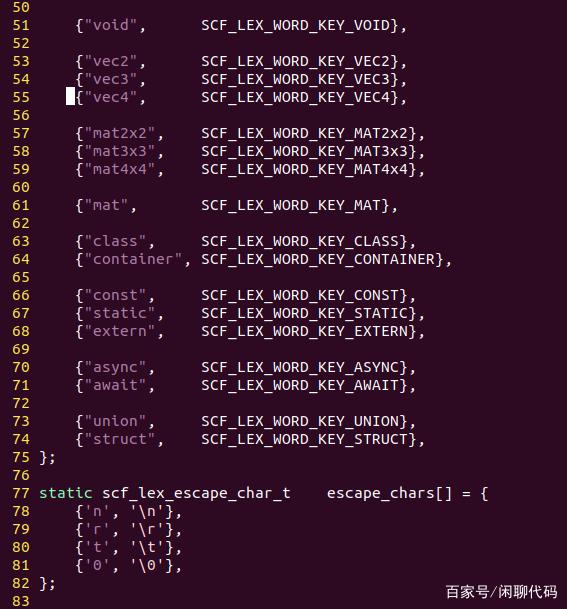
更改这个关键字数组,就可以给词法分析器添加关键字。
转义字符暂时设置了4个,也可以更改这个数组添加。
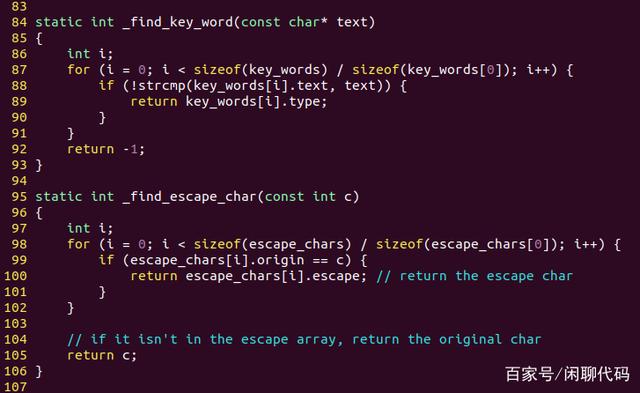
下图是两个查找函数,用于查找关键字和转义字符。
接下来,是词法分析的核心函数,scf_lex_pop_word(),它声明是:
int scf_lex_pop_word(scf_lext_t* lex, scf_lex_word_t** pword);
二级指针用于返回单词,返回值用于返回错误码,成功返回0,失败返回一个负数(一般是-1)。
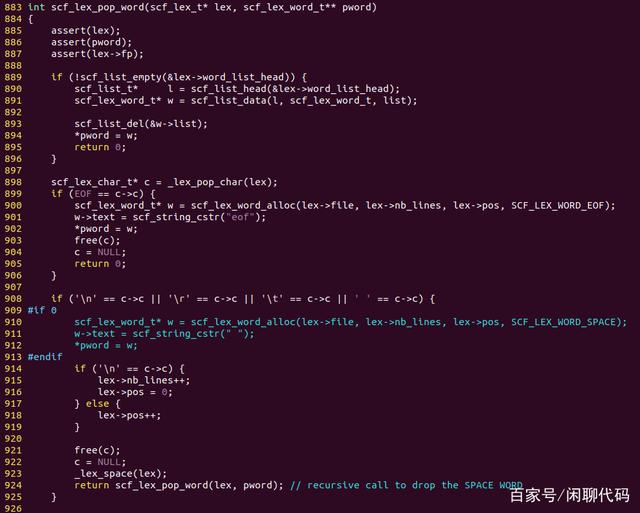 pop_word1
pop_word1
它被语法分析器调用(也可以直接被main函数调用,只做词法分析),所以在单词链表不空的情况下(有被语法分析器放回的单词),优先返回链表头部的单词。
在单词链表空的情况下,调用_lex_pop_char()获取一个字符,开始新单词的分析。
如果是EOF,源码已经读完了,就返回一个EOF单词,获得这个词之后语法分析就会结束,同时词法分析也结束了。
如果是\n \r \t和空格,一律当作空格丢弃,但是\n时要更新行号,其他字符要更新列号。
_lex_space()函数会丢弃所有被当作空格的字符。它包含一个递归调用,用于处理连续的空格。如果当前字符不被当作空格,它就调用_lex_push_char(),把它放回到字符链表上。
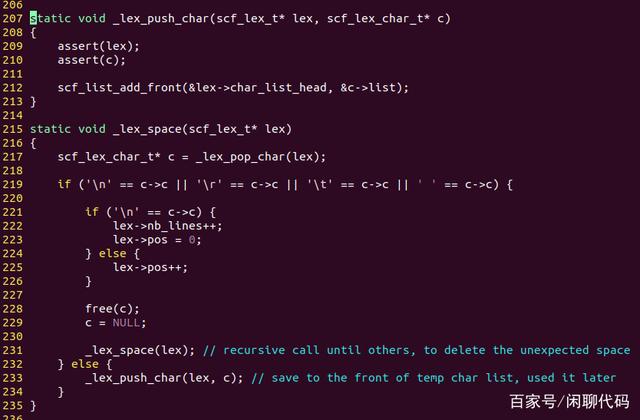
丢弃完空格之后,继续分析下一个单词。
接着图片pop_word1的代码926行,如下图的pop_word2。
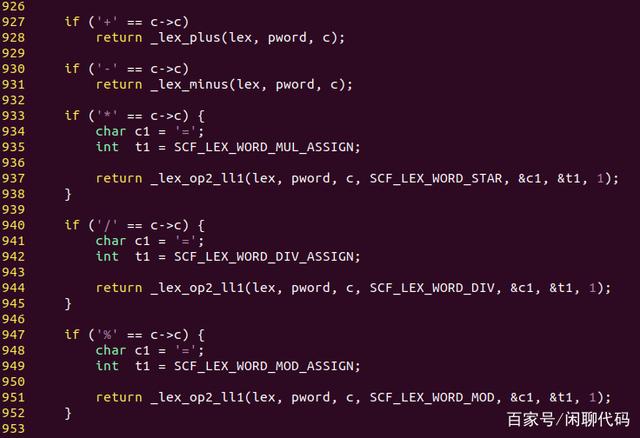 pop_word2
pop_word2
它分析+ - * / %开头的运算符,例如+ += ++,- -= --,* *=,/ /=,% %=这些运算符。
图pop_word3主要是一些单个字符的特殊运算符,各种括号,逗号,冒号,分号。
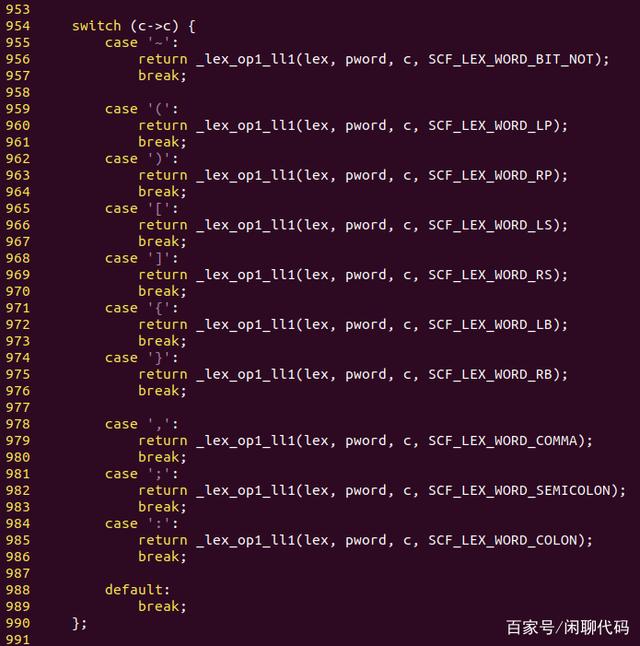 pop_word3
pop_word3
pop_word4,是以& | ! =开头的运算符,例如& && &=,| || |=,= ==。
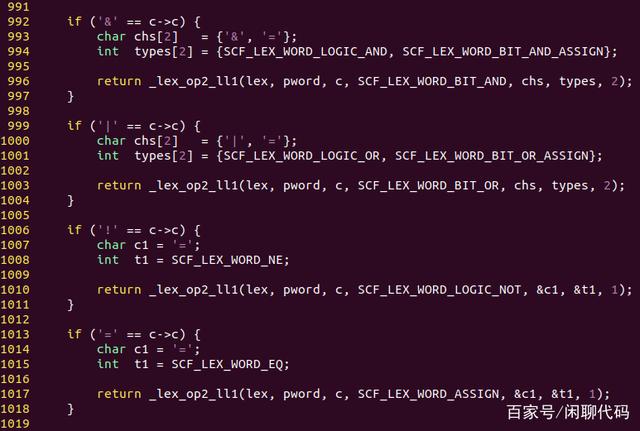 pop_word4
pop_word4
最后一张,图pop_word5。
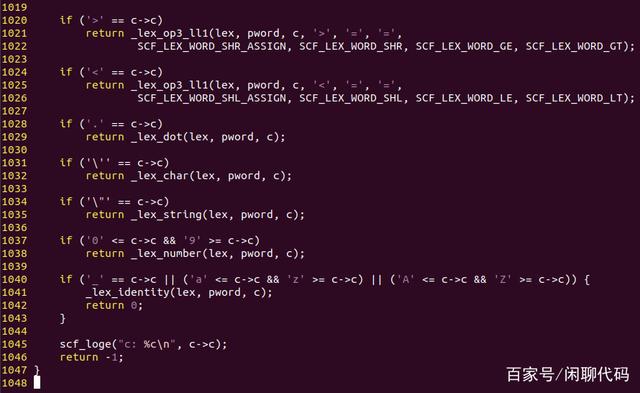 pop_word5
pop_word5
前几行是分析以>和 >> >= >>=,<<<<= <<=。
然后是点号,它可能是1个点或者3个点,分别表示类的成员和函数的可变参数。
以&#39;开始的是字符,以"开始的是字符串,它们都需要做转义字符分析。在词法分析时,它们都是起始字符和终止字符,用于标示字符和字符串的起始和终止。
转义字符在源代码里实际是2个字符,要转义成1个。
字符串,可以是包含或者不包含转义字符的多个字符。
0到9开头的是常量数字,即使是16进制以0x开头,8进制以0开头,开始也是0。
10进制的开头0到9都可能。
暂时不支持直接以点号开头的浮点数,所以0.5必须写成0.5,不能写成.5,否则报词法错误。
标识符,以下划线_或者a-z或者A-Z开头,中间可以包含数字。
总体结构说完了,里面的一些具体分析的函数,接下来几篇再说。
最后还是推荐下龙书,编译原理,因为编译器领域的著作比较少,另外两本虎书和鲸书更难读。
举报/反馈








 京公网安备 11010802041100号
京公网安备 11010802041100号