Spark Streaming是构建在Spark Core基础之上的流处理框架,是Spark非常重要的组成部分。Spark Streaming于2013年2月在Spark0.7.0版本中引入,发展至今已经成为了在企业中广泛使用的流处理平台。在2016年7月,Spark2.0版本中引入了Structured Streaming,并在Spark2.2版本中达到了生产级别,Structured Streaming是构建在Spark SQL之上的流处理引擎,用户可以使用DataSet/DataFreame API进行流处理,目前Structured Streaming在不同的版本中发展速度很快。值得注意的是,本文不会对Structured Streaming做过多讲解,主要针对Spark Streaming进行讨论,包括以下内容:
Spark Streaming是构建在Spark Core的RDD基础之上的,与此同时Spark Streaming引入了一个新的概念:DStream(Discretized Stream,离散化数据流),表示连续不断的数据流。DStream抽象是Spark Streaming的流处理模型,在内部实现上,Spark Streaming会对输入数据按照时间间隔(如1秒)分段,每一段数据转换为Spark中的RDD,这些分段就是Dstream,并且对DStream的操作都最终转变为对相应的RDD的操作。如下图所示:
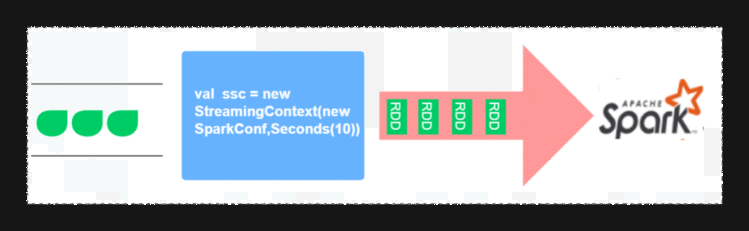
如上图,这些底层的RDD转换操作是由Spark引擎来完成的,DStream的操作屏蔽了许多底层的细节,为用户提供了比较方便使用的高级API。
在Flink中,批处理是流处理的特例,所以Flink是天然的流处理引擎。而Spark Streaming则不然,Spark Streaming认为流处理是批处理的特例,即Spark Streaming并不是纯实时的流处理引擎,在其内部使用的是microBatch模型,即将流处理看做是在较小时间间隔内(batch interval)的一些列的批处理。关于时间间隔的设定,需要结合具体的业务延迟需求,可以实现秒级或者分钟级的间隔。
Spark Streaming会将每个短时间间隔内接收的数据存储在集群中,然后对其作用一系列的算子操作(map,reduce, groupBy等)。执行过程见下图:

如上图:Spark Streaming会将输入的数据流分割成一个个小的batch,每一个batch都代表这一些列的RDD,然后将这些batch存储在内存中。通过启动Spark作业来处理这些batch数据,从而实现一个流处理应用。

经过上面的分析,对Spark Streaming有了初步的认识。那么该如何编写一个Spark Streaming应用程序呢?一个Spark Streaming一般包括一下几个步骤:
StreamingContextDStream来定义输入源 object StartSparkStreaming {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName("Streaming")
// 1.创建StreamingContext
val ssc = new StreamingContext(conf, Seconds(5))
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
Logger.getLogger("org.apache.hadoop").setLevel(Level.OFF)
// 2.创建DStream
val lines = ssc.socketTextStream("localhost", 9999)
// 3.定义流计算处理逻辑
val count = lines.flatMap(_.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
// 4.输出结果
count.print()
// 5.启动
ssc.start()
// 6.等待执行
ssc.awaitTermination()
}
}
DStream是不可变的, 这意味着不能直接改变它们的内容,而是通过对DStream进行一系列转换(Transformation)来实现预期的应用程序逻辑。每次转换都会创建一个新的DStream,该DStream表示来自父DStream的转换后的数据。DStream转换是惰性(lazy)的,这意味只有执行output操作之后,才会去执行转换操作,这些触发执行的操作称之为output operation。
Spark Streaming提供了丰富的transformation操作,这些transformation又分为了有状态的transformation和无状态的transformation。除此之外,Spark Streaming也提供了一些window操作,值得注意的是window操作也是有状态的。具体细节如下:
无状态的transformation是指每一个micro-batch的处理是相互独立的,即当前的计算结果不受之前计算结果的影响,Spark Streaming的大部分算子都是无状态的,比如常见的map(),flatMap(),reduceByKey()等等。
对源DStream的每个元素,采用func函数进行转换,得到一个新的Dstream
/** Return a new DStream by applying a function to all elements of this DStream. */
def map[U: ClassTag](mapFunc: T => U): DStream[U] = ssc.withScope {
new MappedDStream(this, context.sparkContext.clean(mapFunc))
}
与map相似,但是每个输入项可用被映射为0个或者多个输出项
/**
* Return a new DStream by applying a function to all elements of this DStream,
* and then flattening the results
*/
def flatMap[U: ClassTag](flatMapFunc: T => TraversableOnce[U]): DStream[U] = ssc.withScope {
new FlatMappedDStream(this, context.sparkContext.clean(flatMapFunc))
}
返回一个新的DStream,仅包含源DStream中满足函数func的项
/** Return a new DStream containing only the elements that satisfy a predicate. */
def filter(filterFunc: T => Boolean): DStream[T] = ssc.withScope {
new FilteredDStream(this, context.sparkContext.clean(filterFunc))
}
通过创建更多或者更少的分区改变DStream的并行程度
/**
* Return a new DStream with an increased or decreased level of parallelism. Each RDD in the
* returned DStream has exactly numPartitions partitions.
*/
def repartition(numPartitions: Int): DStream[T] = ssc.withScope {
this.transform(_.repartition(numPartitions))
}
利用函数func聚集源DStream中每个RDD的元素,返回一个包含单元素RDDs的新DStream
/**
* Return a new DStream in which each RDD has a single element generated by reducing each RDD
* of this DStream.
*/
def reduce(reduceFunc: (T, T) => T): DStream[T] = ssc.withScope {
this.map((null, _)).reduceByKey(reduceFunc, 1).map(_._2)
}
统计源DStream中每个RDD的元素数量
/**
* Return a new DStream in which each RDD has a single element generated by counting each RDD
* of this DStream.
*/
def count(): DStream[Long] = ssc.withScope {
this.map(_ => (null, 1L))
.transform(_.union(context.sparkContext.makeRDD(Seq((null, 0L)), 1)))
.reduceByKey(_ + _)
.map(_._2)
}
返回一个新的DStream,包含源DStream和其他DStream的元素
/**
* Return a new DStream by unifying data of another DStream with this DStream.
* @param that Another DStream having the same slideDuration as this DStream.
*/
def union(that: DStream[T]): DStream[T] = ssc.withScope {
new UnionDStream[T](Array(this, that))
}
应用于元素类型为K的DStream上,返回一个(K,V)键值对类型的新DStream,每个键的值是在原DStream的每个RDD中的出现次数,比如lines.flatMap(_.split(" ")).countByValue().print(),对于输入:spark spark flink,将输出:(spark,2),(flink,1),即按照元素值进行分组,然后统计每个分组的元素个数。
从源码可以看出:底层实现为map((_,1L)).reduceByKey((x: Long, y: Long) => x + y, numPartitions),即先按当前的元素映射为一个tuple,其中key即为当前元素的值,然后再按照key做汇总。
/**
* Return a new DStream in which each RDD contains the counts of each distinct value in
* each RDD of this DStream. Hash partitioning is used to generate
* the RDDs with `numPartitions` partitions (Spark's default number of partitions if
* `numPartitions` not specified).
*/
def countByValue(numPartitions: Int = ssc.sc.defaultParallelism)(implicit ord: Ordering[T] = null)
: DStream[(T, Long)] = ssc.withScope {
this.map((_, 1L)).reduceByKey((x: Long, y: Long) => x + y, numPartitions)
}
当在一个由(K,V)键值对组成的DStream上执行该操作时,返回一个新的由(K,V)键值对组成的DStream,每一个key的值均由给定的recuce函数(func)聚集起来
比如:lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _).print()
对于输入:spark spark flink,将输出:(spark,2),(flink,1)
/**
* Return a new DStream by applying `reduceByKey` to each RDD. The values for each key are
* merged using the associative and commutative reduce function. Hash partitioning is used to
* generate the RDDs with Spark's default number of partitions.
*/
def reduceByKey(reduceFunc: (V, V) => V): DStream[(K, V)] = ssc.withScope {
reduceByKey(reduceFunc, defaultPartitioner())
}
当应用于两个DStream(一个包含(K,V)键值对,一个包含(K,W)键值对),返回一个包含(K, (V, W))键值对的新Dstream
/**
* Return a new DStream by applying 'join' between RDDs of `this` DStream and `other` DStream.
* Hash partitioning is used to generate the RDDs with Spark's default number of partitions.
*/
def join[W: ClassTag](other: DStream[(K, W)]): DStream[(K, (V, W))] = ssc.withScope {
join[W](other, defaultPartitioner())
}
当应用于两个DStream(一个包含(K,V)键值对,一个包含(K,W)键值对),返回一个包含(K, Seq[V], Seq[W])的元组
// 输入:spark
// 输出:(spark,(CompactBuffer(1),CompactBuffer(1)))
val DS1 = lines.flatMap(_.split(" ")).map((_,1))
val DS2 = lines.flatMap(_.split(" ")).map((_,1))
DS1.cogroup(DS2).print()
/**
* Return a new DStream by applying 'cogroup' between RDDs of `this` DStream and `other` DStream.
* Hash partitioning is used to generate the RDDs with Spark's default number
* of partitions.
*/
def cogroup[W: ClassTag](
other: DStream[(K, W)]): DStream[(K, (Iterable[V], Iterable[W]))] = ssc.withScope {
cogroup(other, defaultPartitioner())
}
通过对源DStream的每个RDD应用RDD-to-RDD函数,创建一个新的DStream。支持在新的DStream中做任何RDD操作
// 输入:spark spark flink
// 输出:(spark,2)、(flink,1)
val lines = ssc.socketTextStream("localhost", 9999)
val resultDStream = lines.transform(rdd => {
rdd.flatMap(_.split("\\W")).map((_, 1)).reduceByKey(_ + _)
})
resultDStream.print()
/**
* Return a new DStream in which each RDD is generated by applying a function
* on each RDD of 'this' DStream.
*/
def transform[U: ClassTag](transformFunc: RDD[T] => RDD[U]): DStream[U] = ssc.withScope {
val cleanedF = context.sparkContext.clean(transformFunc, false)
transform((r: RDD[T], _: Time) => cleanedF(r))
}
有状态的transformation是指每个micro-batch的处理不是相互独立的,即当前的micro-batch处理依赖于之前的micro-batch计算结果。常见的有状态的transformation主要有countByValueAndWindow, reduceByKeyAndWindow , mapWithState, updateStateByKey等等。其实所有的基于window的操作都是有状态的,因为追踪整个窗口内的数据。
关于有状态的transformation和Window Operations,参见下文。
使用Output operations可以将DStream写入多外部存储设备或打印到控制台。上文提到,Spark Streaming的transformation是lazy的,因此需要Output Operation进行触发计算,其功能类似于RDD的action操作。具体详见下文Spark Streaming 数据汇(Sinks)。
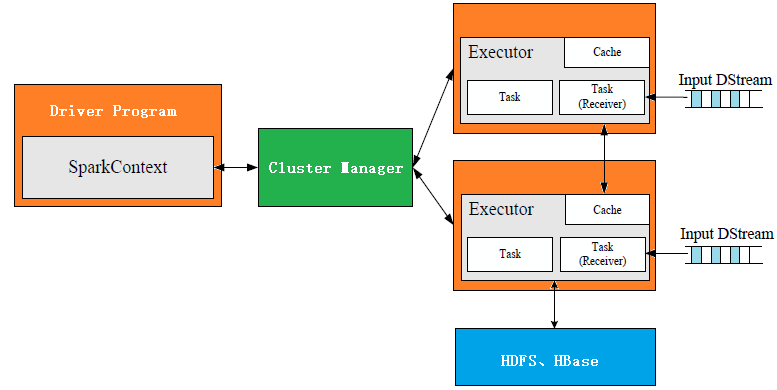
Spark Streaming的目的是成为一个通用的流处理框架,为了实现这一目标,Spark Streaming使用Receiver来集成各种各样的数据源。但是,对于有些数据源(如kafka),Spark Streaming支持使用Direct的方式去接收数据,这种方式比Receiver方式性能要好。
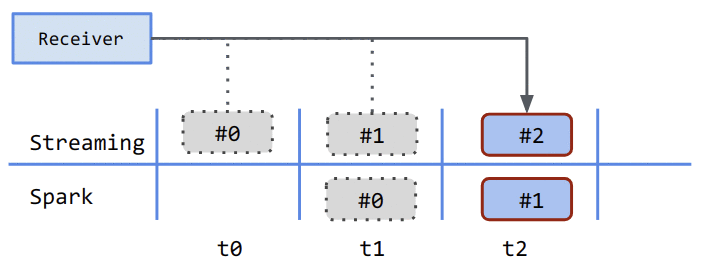
Receiver的作用是从数据源收集数据,然后将数据传送给Spark Streaming。基本原理是:随着数据的不断到来,在相对应的batch interval时间间隔内,这些数据会被收集并且打包成block,只要等到batch interval时间完成了,收集的数据block会被发送给spark进行处理。
如上图:当Spark Streaming启动时,receiver开始收集数据。在t0的batch interval结束时(即收集完了该时间段内的数据),收集到的block #0会被发送到Spark进行处理。在t2时刻,Spark会处理t1的batch interval的数据block,与此同时会不停地收集t2的batch interval对应的block**#2**。
常见的基于Receiver的数据源包括:Kafka, Kinesis, Flume,Twitter。除此之外,用户也可以通过继承 Receiver抽象类,实现onStart()与onStop()两个方法,进行自定义Receiver。本文不会对基于Receiver的数据源做过多讨论,主要针对基于Direct的Kafka数据源进行详细解释。
Spark 1.3中引入了这种新的无Receiver的Direct方法,以确保更强的端到端保证。该方法不是使用Receiver来接收数据,而是定期查询Kafka每个topic+partition中的最新偏移量,并相应地定义要在每个批次中处理的偏移量范围。启动用于处理数据的作业时,Kafka的简单consumer API用于读取Kafka定义的偏移量范围(类似于从文件系统读取文件)。请注意,此功能是在Scala和Java API的Spark 1.3引入的,在Python API的Spark 1.4中引入的。
基于Direct的方式具有以下优点:
如果要读取多个partition,不需要创建多个输入DStream然后对他们进行union操作。Spark会创建跟Kafka partition一样多的RDD partition,并且会并行从kafka中读取数据。所以在kafka partition和RDD partition之间,有一一对应的关系。
如果要保证数据零丢失,在基于Receiver的方式中,需要开启WAL机制。这种方式其实效率很低,因为数据实际被复制了两份,kafka自己本身就有高可靠的机制,会对数据复制一份,而这里又会复制一份到WAL中。而基于Direct的方式,不依赖于Receiver,不需要开启WAL机制,只要kafka中做了数据的复制,那么就可以通过kafka的副本进行恢复。
基于Receiver的方式,使用kafka的高阶API来在Zookeeper中保存消费过的offset。这是消费kafka数据的传统方式。这种方式配合WAL机制,可以保证数据零丢失的高可靠性,但是却无法保证Exactly-once语义(Spark和Zookeeper之间可能是不同步的)。基于Direct的方式,使用kafka的简单API,Spark Streaming自己就负责追踪消费的offset,并保存在checkpoint中。Spark自己一定是同步的,因此可以保证数据时消费一次且仅消费一次。
使用KafkaUtils添加Kafka数据源,源码如下:
def createDirectStream[K, V](
ssc: StreamingContext,
locationStrategy: LocationStrategy,
consumerStrategy: ConsumerStrategy[K, V]
): InputDStream[ConsumerRecord[K, V]] = {
val ppc = new DefaultPerPartitionConfig(ssc.sparkContext.getConf)
createDirectStream[K, V](ssc, locationStrategy, consumerStrategy, ppc)
}
具体参数解释:
K:Kafka消息key的类型
V:Kafka消息value的类型
ssc:StreamingContext
locationStrategy: LocationStrategy,根据Executor中的主题的分区来调度consumer,即尽可能地让consumer靠近leader partition。该配置可以提升性能,但对于location的选择只是一种参考,并不是绝对的。可以选择如下方式:
注意:多数情况下使用PreferConsisten,其他两种方式只是在特定的场景使用。这种配置只是一种参考,具体的情况还是会根据集群的资源自动调整。
consumerStrategy:消费策略,主要有下面三种方式:
注意:大多数情况下使用Subscribe方式。
object TolerateWCTest {
def createContext(checkpointDirectory: String): StreamingContext = {
val sparkConf = new SparkConf()
.set("spark.streaming.backpressure.enabled", "true")
//每秒钟从kafka分区中读取的records数量,默认not set
.set("spark.streaming.kafka.maxRatePerPartition", "1000") //
//Driver为了获取每个leader分区的最近offsets,连续进行重试的次数,
//默认是1,表示最多重试2次,仅仅适用于 new Kafka direct stream API
.set("spark.streaming.kafka.maxRetries", "2")
.setAppName("TolerateWCTest")
val ssc = new StreamingContext(sparkConf, Seconds(3))
ssc.checkpoint(checkpointDirectory)
val topic = Array("testkafkasource2")
val kafkaParam = Map[String, Object](
"bootstrap.servers" -> "kms-1:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "group0",
"auto.offset.reset" -> "latest", //默认latest,
"enable.auto.commit" -> (false: java.lang.Boolean)) //默认true,false:手动提交
val lines = KafkaUtils.createDirectStream(
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topic, kafkaParam))
val words = lines.flatMap(_.value().split(" "))
val wordDstream = words.map(x => (x, 1))
val stateDstream = wordDstream.reduceByKey(_ + _)
stateDstream.cache()
//参照batch interval设置,
//不得低于batch interval,否则会报错,
//设为batch interval的2倍
stateDstream.checkpoint(Seconds(6))
//把DStream保存到MySQL数据库中
stateDstream.foreachRDD(rdd =>
rdd.foreachPartition { record =>
var conn: Connection = null
var stmt: PreparedStatement = null
// 给每个partition,获取一个连接
conn = ConnectionPool.getConnection
// 遍历partition中的数据,使用一个连接,插入数据库
while (record.hasNext) {
val wordcounts = record.next()
val sql = "insert into wctbl(word,count) values (?,?)"
stmt = conn.prepareStatement(sql);
stmt.setString(1, wordcounts._1.trim)
stmt.setInt(2, wordcounts._2.toInt)
stmt.executeUpdate()
}
// 用完以后,将连接还回去
ConnectionPool.returnConnection(conn)
})
ssc
}
def main(args: Array[String]) {
val checkpointDirectory = "hdfs://kms-1:8020/docheckpoint"
val ssc = StreamingContext.getOrCreate(
checkpointDirectory,
() => createContext(checkpointDirectory))
ssc.start()
ssc.awaitTermination()
}
}
Spark Streaming提供了下面内置的Output Operation,如下:
打印数据数据到标准输出,如果不传递参数,默认打印前10个元素
将DStream内容存储到文件系统,每个batch interval的文件名称为`prefix-TIME_IN_MS[.suffix]
将DStream的内容保存为序列化的java对象的SequenceFile,每个batch interval的文件名称为prefix-TIME_IN_MS[.suffix],Python API不支持此方法。
将DStream内容保存为Hadoop文件,每个batch interval的文件名称为prefix-TIME_IN_MS[.suffix],Python API不支持此方法。
通用的数据输出算子,func函数将每个RDD的数据输出到外部存储设备,比如将RDD写入到文件或者数据库。
/**
* Apply a function to each RDD in this DStream. This is an output operator, so
* 'this' DStream will be registered as an output stream and therefore materialized.
*/
def foreachRDD(foreachFunc: RDD[T] => Unit): Unit = ssc.withScope {
val cleanedF = context.sparkContext.clean(foreachFunc, false)
foreachRDD((r: RDD[T], _: Time) => cleanedF(r), displayInnerRDDOps = true)
}
/**
* Apply a function to each RDD in this DStream. This is an output operator, so
* 'this' DStream will be registered as an output stream and therefore materialized.
*/
def foreachRDD(foreachFunc: (RDD[T], Time) => Unit): Unit = ssc.withScope {
// because the DStream is reachable from the outer object here, and because
// DStreams can't be serialized with closures, we can't proactively check
// it for serializability and so we pass the optional false to SparkContext.clean
foreachRDD(foreachFunc, displayInnerRDDOps = true)
}
private def foreachRDD(
foreachFunc: (RDD[T], Time) => Unit,
displayInnerRDDOps: Boolean): Unit = {
new ForEachDStream(this,
context.sparkContext.clean(foreachFunc, false), displayInnerRDDOps).register()
}
foreachRDD是一个非常重要的操作,用户可以使用它将处理的数据输出到外部存储设备。关于foreachRDD的使用,需要特点别注意一些细节问题。具体分析如下:
如果将数据写入到MySQL,需要获取连接Connection。用户可能不经意的在Spark Driver中创建一个连接对象,然后在Work中使用它将数据写入外部设备,代码如下:
dstream.foreachRDD { rdd =>
val connection = createNewConnection() // ①注意:该段代码在driver上执行
rdd.foreach { record =>
connection.send(record) // ②注意:该段代码在worker上执行
}
}
尖叫提示:上面的使用方式是错误的,因为需要将connection对象进行序列化,然后发送到driver节点,而这种connection对象是不能被序列化,所以不能跨节点传输。上面代码会报序列化错误,正确的使用方式是在worker节点创建connection,即在
rdd.foreach内部创建connection。方式如下:
dstream.foreachRDD { rdd =>
rdd.foreach { record =>
val connection = createNewConnection()
connection.send(record)
connection.close()
}
}
上面的方式解决了不能序列化的问题,但是会为每个RDD的record创建一个connection,通常创建一个connection对象是会存在一定性能开销的,所以频繁创建和销毁connection对象会造成整体的吞吐量降低。一个比较好的做法是将rdd.foreach替换为``rdd.foreachPartition,这样就不用频繁为每个record创建connection,而是为RDD的partition创建connection,大大减少了创建connection带来的开销。
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(record => connection.send(record))
connection.close()
}
}
其实上面的使用方式还可以进一步优化,可以通过在多个RDD或者批数据间重用连接对象。用户可以维护一个静态的连接对象池,重复使用池中的对象将多批次的RDD推送到外部系统,以进一步节省开销:
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection)
}
}
/**
* 简易版的连接池
*/
public class ConnectionPool {
// 静态的Connection队列
private static LinkedList connectionQueue;/**
* 加载驱动
*/static {try {
Class.forName("com.mysql.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}/**
* 获取连接,多线程访问并发控制
*
* @return
*/public synchronized static Connection getConnection() {try {if (connectionQueue == null) {
connectionQueue = new LinkedList();for (int i = 0; i 10; i++) {
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/wordcount", "root","123qwe");
connectionQueue.push(conn);
}
}
} catch (Exception e) {
e.printStackTrace();
}return connectionQueue.poll();
}/**
* 用完之后,返回一个连接
*/public static void returnConnection(Connection conn) {
connectionQueue.push(conn);
}
}
object WordCount {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("NetworkWordCount").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
// 存储到MySQL
wordCounts.foreachRDD { rdd =>
rdd.foreachPartition { partition =>
var conn: Connection = null
var stmt: PreparedStatement = null
// 给每个partition,获取一个连接
conn = ConnectionPool.getConnection
// 遍历partition中的数据,使用一个连接,插入数据库
while (partition.hasNext) {
val wordcounts = partition.next()
val sql = "insert into wctbl(word,count) values (?,?)"
stmt = conn.prepareStatement(sql);
stmt.setString(1, wordcounts._1.trim)
stmt.setInt(2, wordcounts._2.toInt)
stmt.executeUpdate()
}
// 用完以后,将连接还回去
ConnectionPool.returnConnection(conn)
}
}
ssc.start()
ssc.awaitTermination()
}
}
由于篇幅限制,本文主要对Spark Streaming执行机制、Transformations与Output Operations、Spark Streaming数据源(Sources)、Spark Streaming 数据汇(Sinks)进行了讨论。下一篇将分享基于时间的窗口操作、有状态的计算、检查点Checkpoint、性能调优等内容。
往期精彩回顾第一篇|Spark概览 在看是一种动力 分享是一种美德
在看是一种动力 分享是一种美德






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有