Batch Normalization: Accelerating Deep Network Training byReducing Internal Covariate Shift
文章试图解决的问题
- 内部协变量转移(internal covariate shift):在训练进行时,网络中的参数不断改变,导致每一层的输入分配会进行变化,这个现象被称作
内部协变量转移 - 由于分布变化,所以需要更小的学习率,小心的初始化。但导致训练速度降低,本文就是要解决这个问题
- 内部协变量转移不符合IID(独立同分布)的假设
常见的优化
- 我们都知道,对初始数据减均值或者白化可以加快学习速度
优点
内容
-
我们知道对每一层进行白化的不可行,所以我们考虑做两个必要的简化。
-
1、我们考虑单独normalize每一个特征,使其均值为0,方差为1;而不是在输入输出上共同normalize
-
对一个d维的input x=(x(1),...x(d))x=(x^{(1)},...x^{(d)})x=(x(1),...x(d)),我们normalize每一维
x^(k)=x(k)−E[x(k)]Var[x(k)]\hat x^{(k)}=\frac{x^{(k)-E[x^{(k)}]}}{\sqrt{Var[x^{(k)}]}} x^(k)=Var[x(k)]x(k)−E[x(k)]
- 期望和方差在总体的数据集上计算
- 仅仅是这一个简化,就能加速收敛
- 这个简化导致数据分布是零均值的,毕竟各层的分布都差不多了
-
我们知道如果只这样干不行,会降低网络的表达能力,如在sigmoid之前这样干会把sigmoid非线性极值变成线性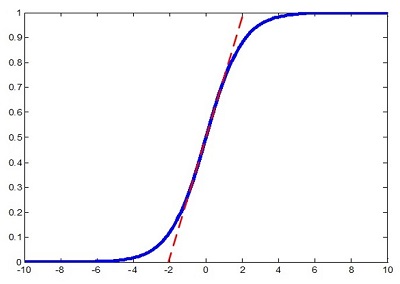
- 所以我们对每一个激活值x^(k)\hat x^{(k)}x^(k)引进两个参数
y(k)=γ(k)x^(k)+β(k)y^{(k)}=\gamma^{(k)}\hat x^{(k)}+\beta^{(k)} y(k)=γ(k)x^(k)+β(k)
-
这些参数和原始网络一起学习,并恢复网络的表达能力
-
事实上,通过设定γ(k)=Var[x(k)],β(k)=E[x(k)\gamma^{(k)}=\sqrt{Var[x^{(k)}]},\beta^{(k)}=E[x^{(k)}γ(k)=Var[x(k)],β(k)=E[x(k)是最理想的方法
- 2、我们这样设置的训练步骤是基于整个网络的,,但是我们在进行SGD的时候是不行的。所以我们有了第二个简化:我们每次用一个Batch(小批量)的均值和方差来作为对整个数据集的估计
然后我们在测试和训练的时候是不一样的,因为训练的时候可以用mini_batch,而测试的时候我们用的是一张张的图片,所以此时直接用所有的均值和方差来做无偏估计,然后训练的网络要用net.eval()来使得参数不变
eval会把网络的参数固定住,比如dropout和BN的参数,不会取平均
![[论文笔记] Crowdsourcing Translation: Professional Quality from Non-Professionals (ACL, 2011)](https://img1.php1.cn/3cd4a/24cea/882/e4b637de1cdddf51.jpeg)







 京公网安备 11010802041100号
京公网安备 11010802041100号