作者:__
编译:ronghuaiyang
导读
非常简单直白的语言解释了BERT中的嵌入层的组成以及实现的方式。
介绍
在本文中,我将解释BERT中嵌入层的实现细节,即token嵌入、Segment嵌入和Position嵌入。
简介
这是一张来自论文的图,它恰当地描述了BERT中每一个嵌入层的功能:
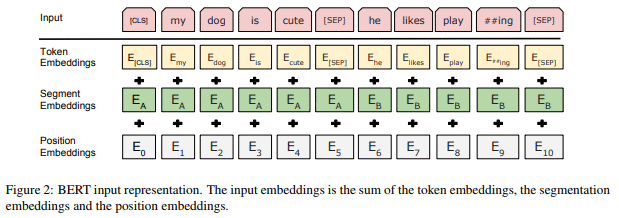
与大多数旨在解决nlp相关任务的深度学习模型一样,BERT将每个输入token(输入文本中的单词)通过token嵌入层传递,以便将每个token转换为向量表示。与其他深度学习模型不同,BERT有额外的嵌入层,以Segment嵌入和Position嵌入的形式。这些附加的嵌入层的原因会在本文的最后变得清楚。
Token嵌入
目的
如前一节所述,token嵌入层的作用是将单词转换为固定维的向量表示形式。在BERT的例子中,每个单词都表示为一个768维的向量。
实现
假设输入文本是“I like strawberries”。下图描述了token嵌入层的作用:

在将输入文本传递到token嵌入层之前,首先对其进行token化。另外,在tokens的开始([CLS])和结束([SEP])处添加额外的tokens。这些tokens的目的是作为分类任务的输入表示,并分别分隔一对输入文本(更多细节将在下一节中介绍)。
tokens化是使用一种叫做WordPiece token化的方法来完成的。这是一种数据驱动的token化方法,旨在实现词汇量和非词汇量之间的平衡。这就是“strawberries”被分成“straw”和“berries”的方式。对这种方法的详细描述超出了本文的范围。感兴趣的读者可以参考Wu et al. (2016)和Schuster & Nakajima (2012)中的第4.1节。单词token化的使用使得BERT只能在其词汇表中存储30522个“词”,而且在对英语文本进行token化时,很少会遇到词汇表以外的单词。
token嵌入层将每个wordpiece token转换为768维向量表示形式。这将使得我们的6个输入token被转换成一个形状为(6,768)的矩阵,或者一个形状为(1,6,768)的张量,如果我们包括批处理维度的话。
Segment嵌入
目的
BERT能够解决包含文本分类的NLP任务。这类问题的一个例子是对两个文本在语义上是否相似进行分类。这对输入文本被简单地连接并输入到模型中。那么BERT是如何区分输入的呢?答案是Segment嵌入。
实现
假设我们的输入文本对是(“I like cats”, “I like dogs”)。下面是Segment嵌入如何帮助BERT区分这个输入对中的tokens :

Segment嵌入层只有两个向量表示。第一个向量(索引0)分配给属于输入1的所有tokens,而最后一个向量(索引1)分配给属于输入2的所有tokens。如果一个输入只有一个输入语句,那么它的Segment嵌入就是对应于Segment嵌入表的索引为0的向量。
Position嵌入
目的
BERT由一堆Transformers 组成的,广义地说,Transformers不编码其输入的顺序特征。在这个博客文章:https://medium.com/@init/how-self-attention-with-relatedposition-representations-works-28173b8c245a的动机部分更详细地解释了我的意思。总之,有Position嵌入将允许BERT理解给定的输入文本,比如:
I think, therefore I am
第一个“I”不应该与第二个“I”具有相同的向量表示。
实现
BERT被设计用来处理长度为512的输入序列。作者通过让BERT学习每个位置的向量表示来包含输入序列的顺序特征。这意味着Position嵌入层是一个大小为(512,768)的查找表,其中第一行是第一个位置上的任意单词的向量表示,第二行是第二个位置上的任意单词的向量表示,等等。因此,如果我们输入“Hello world”和“Hi there”,“Hello”和“Hi”将具有相同的Position嵌入,因为它们是输入序列中的第一个单词。同样,“world”和“there”的Position嵌入是相同的。
合并表示
我们已经看到,长度为n的token化输入序列将有三种不同的表示,即:
token嵌入,形状(1,n, 768),这只是词的向量表示
Segment嵌入,形状(1,n, 768),这是向量表示,以帮助BERT区分成对的输入序列。
Position嵌入,形状(1,n, 768),让BERT知道其输入具有时间属性。
对这些表示进行元素求和,生成一个形状为(1,n, 768)的单一表示。这是传递给BERT的编码器层的输入表示。
总结
在本文中,我描述了BERT的每个嵌入层的用途及其实现。如果你有任何问题,请在评论中告诉我。

—END—
英文原文:https://medium.com/@init/why-bert-has-3-embedding-layers-and-their-implementation-details-9c261108e28a
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦












 京公网安备 11010802041100号
京公网安备 11010802041100号