在数据立方体计算完毕后,有一个任务(Convert Cuboid Data to HFile),其职责是将reduce输出的运算结果(Cuboid Data)转化成Hbase中的存储载体(HFile),最终将HFile 加载到Hbase表中便于查询。其中表的rowkey由维度组合而成,维度组合对应的度量值构成了column family,为了查询减少存储空间,会对RowKey和column family的值进行编码,默认编码是Snappy。
Irish budget airline Ryanair announced plans to significantly increase its route network from Frankfurt Airport, marking a direct challenge to Lufthansa, Germany's leading carrier. ...
[详细]
 当前Apache kylin构建(build)数据立方体,采用逐层算法(By Layer Cubing)。未来的发布中将采用快速立方体算法(Fast Cubing)。下面简单介绍一下逐层算法:
当前Apache kylin构建(build)数据立方体,采用逐层算法(By Layer Cubing)。未来的发布中将采用快速立方体算法(Fast Cubing)。下面简单介绍一下逐层算法: 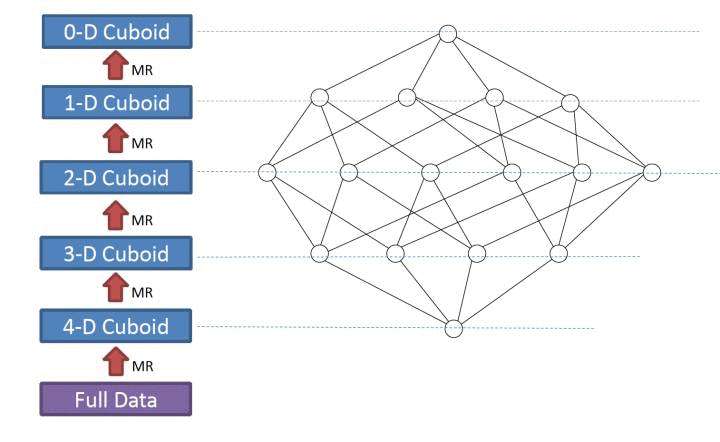 在数据立方体计算完毕后,有一个任务(Convert Cuboid Data to HFile),其职责是将reduce输出的运算结果(Cuboid Data)转化成Hbase中的存储载体(HFile),最终将HFile 加载到Hbase表中便于查询。其中表的rowkey由维度组合而成,维度组合对应的度量值构成了column family,为了查询减少存储空间,会对RowKey和column family的值进行编码,默认编码是Snappy。
在数据立方体计算完毕后,有一个任务(Convert Cuboid Data to HFile),其职责是将reduce输出的运算结果(Cuboid Data)转化成Hbase中的存储载体(HFile),最终将HFile 加载到Hbase表中便于查询。其中表的rowkey由维度组合而成,维度组合对应的度量值构成了column family,为了查询减少存储空间,会对RowKey和column family的值进行编码,默认编码是Snappy。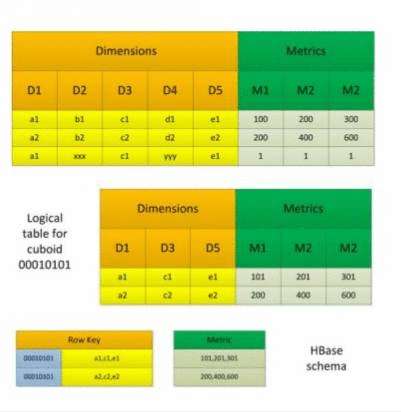 整个数据立方体的构建流程如下:
整个数据立方体的构建流程如下: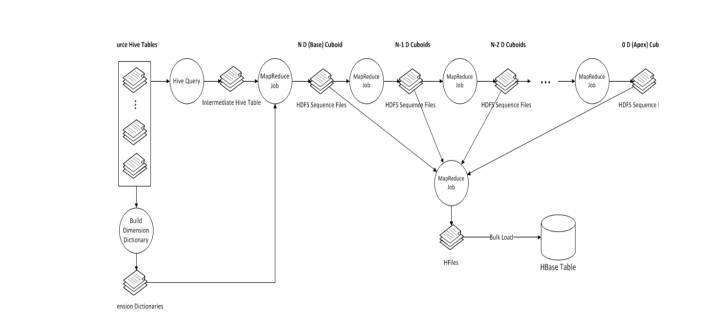
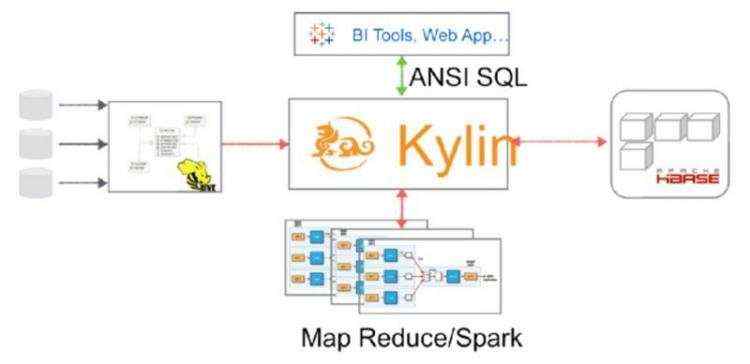
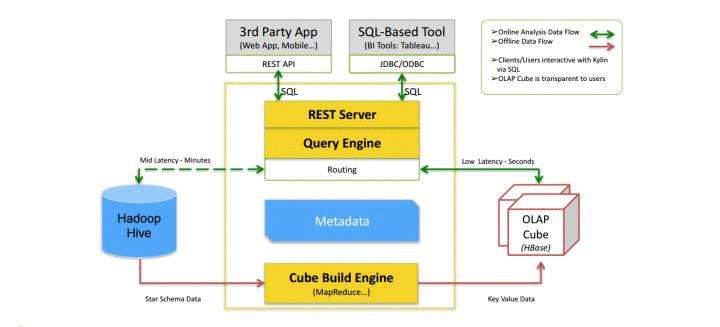 核心组件:
核心组件:







 京公网安备 11010802041100号
京公网安备 11010802041100号