作者:手机用户2602922857 | 来源:互联网 | 2023-05-17 18:02
python+mongodb数据抓取详细介绍是千自学中一篇关于MongoDB的文章简介:分享点干货!!!Python数据抓取分析编程模块:requests,lxml,pymongo,time,BeautifulSoup首先获取所有产品的分类网址:def
分享点干货!!!
Python数据抓取分析
编程模块:requests,lxml,pymongo,time,BeautifulSoup
首先获取所有产品的分类网址:
def step():
try:
headers = {
。。。。。
}
r = requests.get(url,headers,timeout=30)
html = r.content
soup = BeautifulSoup(html,"lxml")
url = soup.find_all(正则表达式)
for i in url:
url2 = i.find_all('a')
for j in url2:
step1url =url + j['href']
print step1url
step2(step1url)
except Exception,e:
print e
我们在产品分类的同时需要确定我们所访问的地址是产品还是又一个分类的产品地址(所以需要判断我们访问的地址是否含有if判断标志):
def step2(step1url):
try:
headers = {
。。。。
}
r = requests.get(step1url,headers,timeout=30)
html = r.content
soup = BeautifulSoup(html,"lxml")
a = soup.find('div',id='divTbl')
if a:
url = soup.find_all('td',class_='S-ITabs')
for i in url:
classifyurl = i.find_all('a')
for j in classifyurl:
step2url = url + j['href']
#print step2url
step3(step2url)
else:
postdata(step1url)
当我们if判断后为真则将第二页的分类网址获取到(第一个步骤),否则执行postdata函数,将网页产品地址抓取!
def producturl(url):
try:
p1url = doc.xpath(正则表达式)
for i in xrange(1,len(p1url) + 1):
p2url = doc.xpath(正则表达式)
if len(p2url) > 0:
producturl = url + p2url[0].get('href')
count = db[table].find({'url':producturl}).count()
if count <= 0:
sn = getNewsn()
db[table].insert({"sn":sn,"url":producturl})
print str(sn) + 'inserted successfully'
else:
'url exist'
except Exception,e:
print e
其中为我们所获取到的产品地址并存入mongodb中,sn作为地址的新id。
下面我们需要在mongodb中通过新id索引来获取我们的网址并进行访问,对产品进行数据分析并抓取,将数据更新进数据库内!
其中用到最多的BeautifulSoup这个模块,但是对于存在于js的价值数据使用BeautifulSoup就用起来很吃力,所以对于js中的数据我推荐使用xpath,但是解析网页就需要用到HTML.document_fromstring(url)方法来解析网页。
对于xpath抓取价值数据的同时一定要细心!如果想了解xpath就在下面留言,我会尽快回答!
def parser(sn,url):
try:
headers = {
。。。。。。
}
r = requests.get(url, headers=headers,timeout=30)
html = r.content
soup = BeautifulSoup(html,"lxml")
dt = {}
#partno
a = soup.find("meta",itemprop="mpn")
if a:
dt['partno'] = a['content']
#manufacturer
b = soup.find("meta",itemprop="manufacturer")
if b:
dt['manufacturer'] = b['content']
#description
c = soup.find("span",itemprop="description")
if c:
dt['description'] = c.get_text().strip()
#price
price = soup.find("table",class_="table table-condensed occalc_pa_table")
if price:
cost = {}
for i in price.find_all('tr'):
if len(i) > 1:
td = i.find_all('td')
key=td[0].get_text().strip().replace(',','')
val=td[1].get_text().replace(u'\u20ac','').strip()
if key and val:
cost[key] = val
if cost:
dt['cost'] = cost
dt['currency'] = 'EUR'
#quantity
d = soup.find("input",id="ItemQuantity")
if d:
dt['quantity'] = d['value']
#specs
e = soup.find("div",class_="row parameter-container")
if e:
key1 = []
val1= []
for k in e.find_all('dt'):
key = k.get_text().strip().strip('.')
if key:
key1.append(key)
for i in e.find_all('dd'):
val = i.get_text().strip()
if val:
val1.append(val)
specs = dict(zip(key1,val1))
if specs:
dt['specs'] = specs
print dt
if dt:
db[table].update({'sn':sn},{'$set':dt})
print str(sn) + ' insert successfully'
time.sleep(3)
else:
error(str(sn) + '\t' + url)
except Exception,e:
error(str(sn) + '\t' + url)
print "Don't data!"
最后全部程序运行,将价值数据分析处理并存入数据库中!
以上就是本文关于python+mongodb数据抓取详细介绍的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站:Python探索之创建二叉树、Python探索之修改Python搜索路径、浅谈python中copy和deepcopy中的区别等,有什么问题,欢迎留言一起交流讨论。
推荐阅读
-
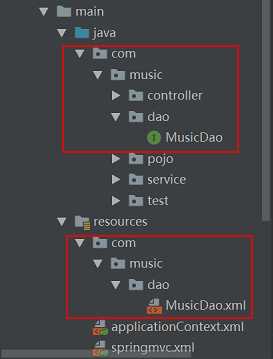
在将Spring与MyBatis进行整合时,作者遇到了“无效绑定语句(未找到):com.music.dao.MusicDao.findAll”的问题。该问题主要出现在使用XML文件配置DAO层的情况下,而注解方式配置则未出现类似问题。作者详细分析了两个配置文件之间的差异,并最终找到了解决方案。本文将详细介绍问题的原因及解决方法,帮助读者避免类似问题的发生。 ...
[详细]
蜡笔小新 2024-11-01 11:37:01
-
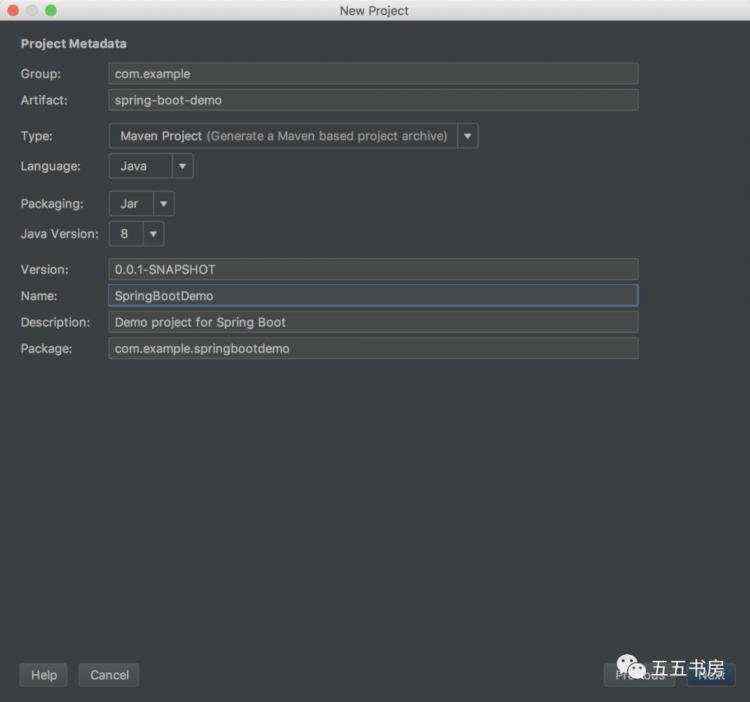
从零起步:使用IntelliJ IDEA搭建Spring Boot应用的详细指南 ...
[详细]
蜡笔小新 2024-11-01 11:34:01
-
-
本文作为“实现简易版Spring系列”的第五篇,继前文深入探讨了Spring框架的核心技术之一——控制反转(IoC)之后,将重点转向另一个关键技术——面向切面编程(AOP)。对于使用Spring框架进行开发的开发者来说,AOP是一个不可或缺的概念。了解AOP的背景及其基本原理,对于掌握这一技术至关重要。本文将通过具体示例,详细解析AOP的实现机制,帮助读者更好地理解和应用这一技术。 ...
[详细]
蜡笔小新 2024-10-31 19:58:14
-
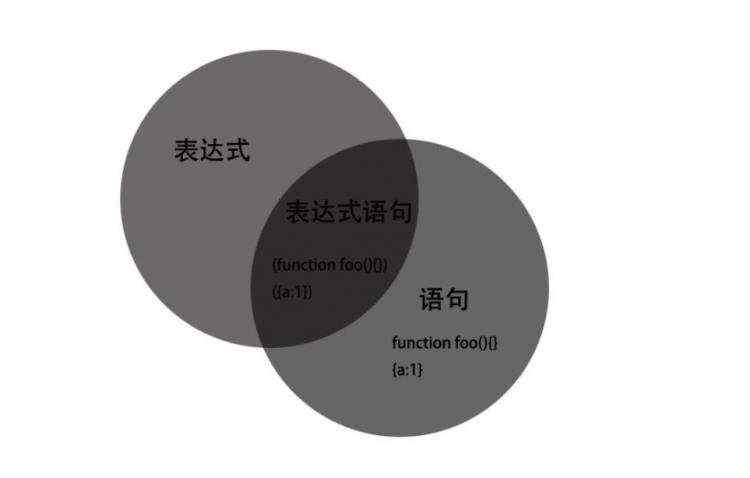
深入解析:JavaScript中的表达式与语句有何不同 ...
[详细]
蜡笔小新 2024-10-31 15:20:33
-
Spring框架是Java Web开发中广泛应用的轻量级应用框架,以其卓越的功能和出色的性能赢得了广大开发者的青睐。本文为初学者提供了详尽的学习指南,涵盖基础概念、核心组件及实际应用案例,帮助新手快速掌握Spring框架的核心技术与实践技巧。 ...
[详细]
蜡笔小新 2024-10-31 13:26:04
-
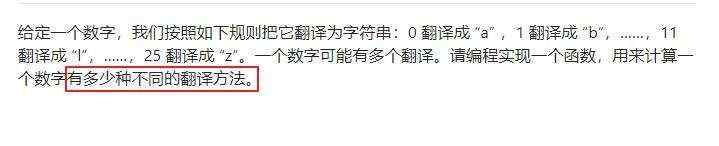
循环结构与零钱问题:多题型综合解析与应用 ...
[详细]
蜡笔小新 2024-10-31 12:32:27
-
C#编程指南:实现列表与WPF数据网格的高效绑定方法 ...
[详细]
蜡笔小新 2024-10-31 10:46:47
-
当前,众多初创企业对全栈工程师的需求日益增长,但市场中却存在大量所谓的“伪全栈工程师”,尤其是那些仅掌握了Node.js技能的前端开发人员。本文旨在深入探讨全栈工程师在现代技术生态中的真实角色与价值,澄清对这一角色的误解,并强调真正的全栈工程师应具备全面的技术栈和综合解决问题的能力。 ...
[详细]
蜡笔小新 2024-10-31 10:28:12
-
深入解析Tomcat:开发者的实用指南 ...
[详细]
蜡笔小新 2024-10-31 09:46:02
-
为了优化直播应用底部聊天框的弹出机制,确保在不同设备上的布局稳定性和兼容性,特别是在配备虚拟按键的设备上,我们对用户交互流程进行了调整。首次打开应用时,需先点击首个输入框以准确获取键盘高度,避免直接点击第二个输入框导致的整体布局挤压问题。此优化通过调整 `activity_main.xml` 布局文件实现,确保了更好的用户体验和界面适配。 ...
[详细]
蜡笔小新 2024-10-30 15:06:55
-
从 Java 过渡到 Ruby,不仅是一次编程语言的转换,更是一段技术进阶的旅程。本文将深入探讨两种语言在语法、生态系统和开发模式上的差异,帮助开发者顺利实现转型,并在新的环境中高效地编写高质量代码。 ...
[详细]
蜡笔小新 2024-10-30 14:27:54
-
在Spring框架中,基于Schema的异常通知与环绕通知的实现方法具有重要的实践价值。首先,对于异常通知,需要创建一个实现ThrowsAdvice接口的通知类。尽管ThrowsAdvice接口本身不包含任何方法,但开发者需自定义方法来处理异常情况。此外,环绕通知则通过实现MethodInterceptor接口来实现,允许在方法调用前后执行特定逻辑,从而增强功能或进行必要的控制。这两种通知机制的结合使用,能够有效提升应用程序的健壮性和灵活性。 ...
[详细]
蜡笔小新 2024-10-30 13:30:04
-
SQL注入工具如SQLMap等在网络安全测试中广泛应用。SQLMap是一款开源的自动化SQL注入工具,支持12种不同的数据库,具体支持的数据库类型可在其插件目录中查看。作为当前最强大的注入工具之一,SQLMap在实际应用中具有极高的效率和准确性。 ...
[详细]
蜡笔小新 2024-10-30 11:16:15
-
目录
lxmlwindows安装
读取示例
可视化
生成示例
上面是代码,下面有调用示例
api调用代码,其实只有几行:这个生成代码也很简 ...
[详细]
蜡笔小新 2024-10-30 09:23:45
-
探索JavaScript倒计时功能的三种高效实现方法及代码示例 ...
[详细]
蜡笔小新 2024-10-29 20:54:36
-
手机用户2602922857
这个家伙很懒,什么也没留下!



 京公网安备 11010802041100号
京公网安备 11010802041100号