随着深度学习项目从实验到生产的发展,越来越多的应用需要对深度学习模型进行大规模和实时的分布式推理服务。虽然已经有一些 工具 可用于相关任务(如模型优化、服务、集群调度、工作流管理等等),但对于许多深度学习的工程师和科学家来说,开发和部署能够透明地扩展到大型集群的分布式推理工作流仍然是一个具有挑战性的过程。

为了应对这一挑战,我们在 Analytics Zoo 0.7.0 版本中发布了 Cluster Serving 的支持。Analytics Zoo Cluster Serving 是一个轻量级、分布式、实时的模型服务解决方案,支持多种深度学习模型(例如 TensorFlow*、PyTorch*、Caffe*、BigDL 和 OpenVINO™的模型)。它提供了一个简单的 pub/sub API(发布 / 订阅),用户可以轻松地将他们的推理请求发送到输入队列(使用一个简单的 Python API)。然后,Cluster Serving 将使用分布式流框架(如 Apache Spark* Streaming、Apache Flink* 等等)在大型集群中进行实时模型推理和自动扩展规模。Analytics Zoo Cluster Serving 的总体架构如图 1 所示。
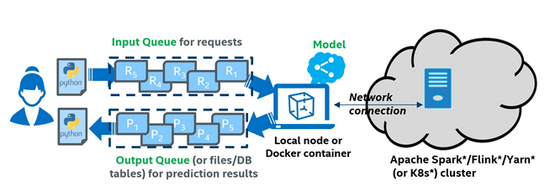
图 1Analytics Zoo Cluster Serving 解决方案总体框架
Cluster Serving 的工作原理
你可以按照下面的三个简单步骤使用 Cluster Serving 解决方案(如图 2 所示)。
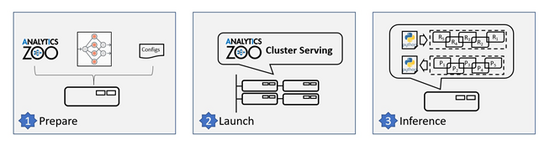
图 2使用 Analytics Zoo Cluster Serving 解决方案的步骤
-
在本地节点安装和准备 Cluster Serving 环境
- 将已经完成训练的模型复制到本地节点。当前支持的模型包括 TensorFlow、PyTorch、Caffe、BigDL 和 OpenVINO 的模型。
- 在本地节点上安装 Analytics Zoo(例如使用单个 pip Install 命令即可完成)
- 在本地节点上配置集群服务器,包括模型的文件路径和集群地址(如 Apache Hadoop*YARN 集群、Spark 集群、Kubernetes* 集群等)
请注意这一点,Cluster Serving 解决方案只需要部署在本地节点上,集群(YARN 或者 Kubernetes)并不需要做任何改动。
-
启动 Cluster Serving 服务
通过在本地节点上运行 startup script 脚本启动 Cluster Serving 服务,例如:
start-cluster-serving.sh
在后台,Cluster Serving 将自动部署训练好的模型,并以分布式的方式跨集群服务于模型推理请求。您可以使用 TensorBoard* 监测其运行时状态(例如推理吞吐量)。
-
分布式实时(流式)推理
Cluster Serving 提供了一个简单的 pub/sub API(发布 / 订阅),你可以使用这个简单的 Python API 将推理请求轻松地发送到输入队列(当前使用的是 Redis* Streams),例如:
input =InputQueue()
input.enqueue_image(id,image)
然后,Cluster Serving 将从 Redis* Streams 读取请求,使用 Spark Streaming 或 Flink 跨集群运行分布式实时推理,并通过 Redis 返回结果。最后,您可以再次使用这个简单的 Python API 获得推理结果,例如:
output= OutputQueue()
results= output.dequeue()
快速入门示例
你也可以通过运行 Analytics Zoo 0.7.0 版本中提供的快速入门示例来尝试使用 Cluster Serving。快速入门示例包含了使用 Cluster Serving 运行分布式推理流程所需的所有组件,首次使用它的用户能够在几分钟内启动并运行。快速入门示例包含:
- 一个 Analytics Zoo Cluster Serving 的 Docker Image (已安装所有依赖)
- 一个示例配置文件
- 一个训练好的 TensorFlow 模型,以及推理样本数据
- 一个示例 Python 客户端程序
按照下面的步骤运行快速入门示例。有关详细说明,请参阅 Analytics Zoo Cluster Serving 编程指南 。
-
启动 Analytics Zoo docker
#dockerrun-itd --namecluster-serving --net=host intelanalytics/zoo-cluster-serving:0.7.0 bash
-
登录 container 并转到我们准备好的工作目录
#dockerexec-it cluster-serving bash
#cdcluster-serving
-
在 container 内启动 Cluster Serving
#cluster-serving-start
-
运行 Python 客户端程序,开始推理
#pythonquick_start.py
以下推理结果应该出现在你本地终端显示上:
image: fish1.jpeg,classification-result:class:1'sprob:0.9974158
image: cat1.jpeg,classification-result:class:287'sprob:0.52377725
image: dog1.jpeg,classification-result:class:207'sprob:0.9226527
如果你希望构建和部署定制的 Cluster Serving 流程,可以从修改快速入门示例中提供的示例配置文件和示例 Python 程序开始。下面是这些文件的大致结构,仅供参考。有关更多详细信息,请参阅 Cluster Serving 编程指南 。
配置文件(config.yaml)如下所示:
## Analytics Zoo Cluster Serving Config Example
model:
# model path must be set
path:/opt/work/model
data:
# default, localhost:6379
src:
# default, 3,224,224
image_shape:
params:
# default, 4
batch_size:
# default, 1
top_n:
spark:
# default, local[*], change this to spark://, yarn, k8s:// etc if you want to run on cluster
master:local[*]
# default, 4g
driver_memory:
# default, 1g
executor_memory:
# default, 1
num_executors:
# default, 4
executor_cores:
# default, 4
total_executor_cores:
Python 程序( quick_start.py )如下所示:
from zoo.serving.clientimportInputQueue, OutputQueue
importos
importcv2
importjson
importtime
if__name__=="__main__":
input_api= InputQueue()
base_path="../../test/zoo/resources/serving_quick_start"
ifnot base_path:
raise EOFError("You have to set your image path")
output_api= OutputQueue()
output_api.dequeue()
path= os.listdir(base_path)
for pinpath:
ifnot p.endswith("jpeg"):
continue
img= cv2.imread(os.path.join(base_path, p))
img= cv2.resize(img, (224,224))
input_api.enqueue_image(p, img)
time.sleep(5)
# get all results and dequeue
result= output_api.dequeue()
for kinresult.keys():
output="image: "+ k +", classification-result:"
tmp_dict= json.loads(result[k])
for class_idxintmp_dict.keys():
output +="class: "+ class_idx +"'s prob: "+ tmp_dict[class_idx]
print(output)
结论
我们很高兴与您分享 Analytics Zoo 0.7.0 版本中提供的这种新的群集模型服务支持,并希望此解决方案有助于简化您的分布式推理工作流并提高您的工作效率。我们很乐意在 GitHub 和邮件列表上听到您的问题和反馈。我们将持续对 Analytics Zoo 进行开发工作,构建统一数据分析和人工智能平台,敬请期待更多关于 Analytics Zoo 的信息。











 京公网安备 11010802041100号
京公网安备 11010802041100号