作者:liunian007 | 来源:互联网 | 2023-07-18 12:30
广东移动新版清帐单系统已经上线承载全省1.2亿用户的实时清单和账单服务,性能和实时性要求非常高。通过上百台X3650PC服务器组构建出集群,采用INTEL提供的Hadoop产品,B
系统介绍
背景
广东移动新版清帐单系统已经上线承载全省1.2亿用户的实时清单和账单服务,性能和实时性要求非常高。系统背端用的是上百台PC服务器组成分布式集群支撑系统性能服务。通过上百台X3650 PC服务器组构建出集群,采用INTEL提供的Hadoop产品(下面简称IDH),BOSS省中心和生产BOSS将清单和账单文件提供给清帐单中心,上清帐单中心对入库和查询进行业务处理。存储使用上百台PC机身硬盘作分布式存储,每台PC配置6TB磁盘容量,按每 份数据存放3份计算。
INTEL在2014年已经彻底放弃了大数据业务模块,所以现在idh是一套遗留的旧系统。
现状
- 入库,每小时成千上万的上游文件经过FTP采集,传送到LINUX文件系统上面,再经过BULK LOAD转换解析后导入分布式数据库Hbase。
- 分布式数据库Hbase对外提供清单和帐单的查询能力。
- 分布式数据库Hive对内提供清单和帐单的报表统计和提数分析。
未来挑战
拨打电话形成的记录是清单,月结形成的记录是帐单,随着集团业务发展的需求,每天入库的数据越来越多,最初集群上线只有500TB的数据,两年后集群总数据已经达到800TB,预计将来每年要增加100TB左右,每天有接近2TB的数据文件需要入库并进行汇总分析,入库要及时,否则查询会出现滞时,现在从数据的增长情况来看,数据入库越来越慢,个别出现拨打电话后30分钟仍然无法进行查询的情况。
未来平台发展战略是中台路线,除了清帐单内容数据,以后根据业务需求还会流入行为数据、交易数据、日志数据等,多种数据融汇贯通,目前来看当前平台数据架构满足不了需求。另外应用无法做到多样化、差异化,因为IDH只有一个hbase数据产品 ,不但无法满足应用的丰富性,而且无法确保it与业务一致,为企业集团改革、转型和提高适应性提供支撑。
融合计费清帐单平台的痛点如下,亟待一个新兴技术的平台带来强大的技术优势,从战略上帮助组织快速改变产品,服务和数据。
业务痛点
- 难以满足用户需求,idh hadoop只有唯一 一个mapreduce引擎,没有支持实时分析计算引擎spark,月报表需要T +1 ,当天的需求第二天才能出结果,甚至更多的时间才能出来。
- 维护成本的费用较高,CPU经常满负荷 ,磁盘使用100%,甚至网络使用也在一个高段的使用状态,经常有datanode或者regionserver的节点宕掉,idh manager监控不力,需要定时有人巡检,并启动相关服务。
- 缺乏知识性能力文档,hadoop1已经是过去式,hadoop2正在成为主流,hadoop1相关资料在互联网查阅资源少,idh的资料更少。
- 存在安全风险,严重安全问题无法防范kernel级安全的风险,如果平台出了致命问题,除了应急响应慢,而且也是束手无策,当前安全问题jobtrack集计算调度和资源管理功能,资源抢占时会导致任务挂起,运行时发生中断。
- 无法兼容其它生态系统,不支持yarn,不支持flink,未来很长一段时间都无法与第三方系统集成,现有的架构根本无法扩容。
系统架构方案设计
Transwarp Data Hub(简称TDH)是国内首个全面支持Spark的Hadoop发行版,也是国内落地案例最多的商业版本,是国内外领先的高性能平台,比开源基于Hadoop MapReduce计算框架的版本快10x~100x倍。TDH应用范围覆盖各种规模和不同数据量的企业,通过内存计算、高效索引、执行优化和高度容错的技术,使得一个平台能够处理10GB到100PB的数据,并且在每个数量级上,都能比现有技术提供更快的性能;企业客户不再需要混合架构,TDH可以伴随企业客户的数据增长,动态不停机扩容,避免MPP或混合架构数据迁移的棘手问题。
星环的大数据平台TDH包含四个组成部分: Transwarp Hadoop企业版,Transwarp Inceptor分布式内存分析引擎,Transwarp Hyperbase分布式实时在线数据处理引擎和Transwarp Stream流处理引擎,四个产品组件构成了完整的大数据平台。
在统一的分布式存储之上数据平台上通过Transwarp YARN提供统一的资源管理调度,结合LDAP与Kerberos提供完备的权限管理控制,不同的部门以及使用租户可以按需创建计算集群访问其授权数据,包括基于Spark计算框架的SQL类统计分析应用与数据挖掘类应用,或者基于MapReduce计算框架的应用。同时,平台通过使用Hyperbase结合Inceptor,提供基于SQL的高并发的查询以及分析能力。在数据导入与交换方面,数据平台提供多样的数据导入与交换形式,包括Flume提供海量数据文件的聚合汇总到HDFS的功能,FTP Over HDFS提供文件通过FTP传入HDFS的通道,Sqoop提供与关系型数据库的数据交换以及Kafka消息队列集群接收实时流数据。此外,TDH数据平台提供实时的流处理能力,通过消息队列Kafka接收实时数据流,做到数据不丢不重,通过Transwarp Stream基于Spark Streaming提供类似与批处理系统的计算能力、健壮性、扩展性的同时,将数据时延降低至秒级甚至毫秒级。
数据平台对外提供JDBC/ODBC接口以提供基于Inceptor支持SQL的查询统计分析;提供R语言编程接口,结合Inceptor中内置的并行算法库进行数据挖掘;提供REST API接口WebHDFS和StarGate,方便访问HDFS与Hyperbase;提供Java API编程接口,完全兼容Hadoop生态圈中全部API。
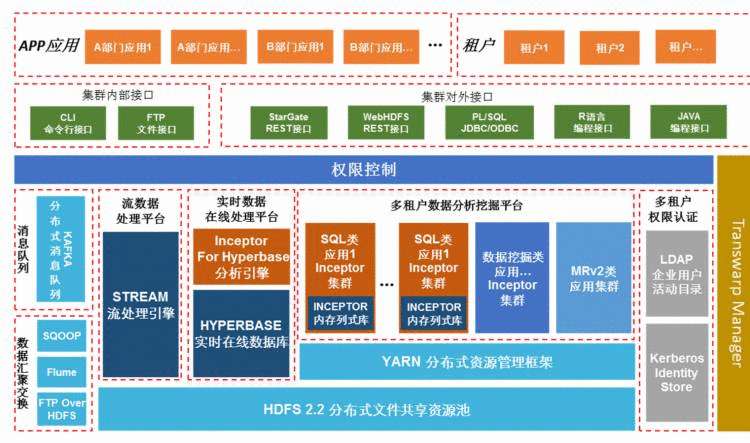
Transwarp Data Hub对开源组件进行了集成、增强,对外提供强大、稳定、高效、便捷的存储、访问、读取、分析、计算、挖掘能力,TDH平台集成了开源众多的组件,集成的组件所提供的功能能够满足企业对数据平台应用的全部场景的要求,涉及的重要组件说明描述如下:

针对每个组件的详细描述如下:
Transwarp Manager
Transwarp Manager是统一的图形界面的管理工作台,提供图形化、自动化的安装、部署、配置、监控、报警等功能,提供用户管理、权限管理、服务管理、健康监测、许可管理等,提供丰富的图标展示,极大的方便用户在同一个界面对集群进行高效、便捷的管理。
HDFS
HDFS (Hadoop分布式文件系统)是运行在通用硬件上的分布式文件系统,本平台采用基于HDFS2.2的大数据存储和在线服务系,兼容现有Hadoop2.0稳定版本,支持文件数据、流数据、互联网数据的分布式存储于计算,同时支持Erasure Code以及HDFS文件加密。HDFS 提供了一个高度容错性和高吞吐量的海量数据存储解决方案。HDFS 已经在各种大型在线服务和大型存储系统中得到广泛应用,已经成为海量数据存储的事实标准。
Hyperbase
Hyperbase是一个列存储的、基于Apache HBase的实时分布式数据库。用来解决关系型数据库在处理海量数据时的理论和实现上的局限性。Hyberbase通过列存储可极大压缩数据大小,有效降低磁盘I/O,提高利用率。同时具有灵活的表结构,可动态改变和增加(包括行、列和时间戳)Column以及Column Family,并支持单行的ACID事务处理。平台提供的Hyperbase通过使用索引来加快数据的查询速度。包括三种索引:本地索引、全局索引、全文索引。
Hyperbase支持分布式事务,图计算,可以通过SQL直接访问Hyperbase中的数据。
Stream
Stream是实时流式计算系统同时具备分布式、水平扩展、高容错和低延迟特性。系统通过在软件层面通过冗余、重放、借助外部存储等方式实现容错,可以避免数台服务器故障、网络突发阻塞等问题造成的数据丢失的问题。Stream前端通过分布式的消息缓冲队列缓冲实时数据。
MapReduce
提供Hadoop平台的MapReduce编程模型,可用于大规模数据集的并行运算。"Map(映射)"和"Reduce(归约)"的编程方式极大地方便了编程人员在分布式系统上进行分布式并行编程。通过实现指定的一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组,来完成分布式编程。
Inceptor
Inceptor是基于Apache Spark的分布式内存计算引擎,Inceptor在开源的Spark上做了很多的改造,无论从性能、稳定性还是易用性都做了上都远远超过开源的Spark。在数据挖掘与机器学习等需要多次迭代的任务中,性能更是比MapReduce快10100倍,比MPP数据库性能提升210倍,比Hive快10~100倍。平台提供的Spark,能够在TB级规模数据上高效进行各种稳定的统计分析、数据挖掘、机器学习的任务。支持SQL 2003,PL/SQL标准,提供分布式列式数据缓存Holodesk。
YARN
在基于Hadoop 2.5.2的大数据平台上,对于资源的管理通过YARN来进行,并且对在Yarn上运行的Spark集群进行了CPU、内存的资源管理调度优化,为其创造更优的Spark运行环境,同时也可以支持其他的流行计算框架,如MapReduce等。Hadoop 1.0中通过JobTracker进行的作业的控制和资源管理,它存在诸多问题,包括存在单点故障,扩展受限等,而为了解决这些问题,Apache Hadoop 2.0对MapReduce 1.0进行了改进,提出了YARN,YARN将 JobTracker中的作业控制和资源管理两个功能分开,分别由两个不同的进程处理,进而解决了原有JobTracker存在的问题。经过架构调整之 后,YARN已经完全不同于MapReduce 1.0,它已经变成了一个资源管理平台,或者说应用程序管理框架。
Zookeeper
TDH平台通过Zookeeper进行协调服务。Zookeeper是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
Titan
TDH平台提供Titan组件,Titan 是一个分布式的图形数据库,特别为存储和处理大规模图形而优化。Titan和Hadoop生态系统紧密结合,可以将海量图关系数据存储在Hyperbase之中,支持并发处理图操作,在秒级时间内返回复杂的图关系检索分析。
Pig
TDH平台提供Pig组件,Pig 是一个高级过程语言,适用于 Hadoop 和 MapReduce 平台查询大型半结构化数据集。通过允许对分布式数据集进行类似 SQL 的查询,Pig 可以简化 Hadoop 的使用。
Oozie
TDH平台提供Oozie组件,OOozie工作流是放置在控制依赖DAG(有向无环图Direct Acyclic Graph)中的一组动作(例如,Hadoop的Map/Reduce作业、Pig作业等),其中指定了动作执行的顺序。我们会使用hPDL(一种XML流程定义语言)来描述这个图。Oozie为以下类型的动作提供支持: Hadoop map-reduce、Hadoop文件系统、Pig、Java和Oozie的子工作流。Oozie也可以调度执行Inceptor中SQL任务。
Oozie可以支持现存的Hadoop用于负载平衡、灾难恢复的机制。这些任务主要是异步执行的(只有文件系统动作例外,它是同步处理的)。这意味着对于大多数工作流动作触发的计算或处理任务的类型来说,在工作流操作转换到工作流的下一个节点之前都需要等待,直到计算或处理任务结束了之后才能够继续。Oozie可以通过两种不同的方式来检测计算或处理任务是否完成,也就是回调和轮询。当Oozie启动了计算或处理任务的时候,它会为任务提供唯一的回调URL,然后任务会在完成的时候发送通知给特定的URL。在任务无法触发回调URL的情况下(可能是因为任何原因,比方说网络闪断),或者当任务的类型无法在完成时触发回调URL的时候,Oozie有一种机制,可以对计算或处理任务进行轮询,从而保证能够完成任务。
Sqoop
TDH平台提供Sqoop组件,Sqoop主要用于在HDFS、Inceptor与Hyperbase与传统的数据库(mysql、postgresql等)间进行数据的传递,可以将一个关系型数据库(MySQL、Oracle、Postgres等)中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导出到关系型数据库中。
Flume
TDH平台提供Flume组件,Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据。同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Squrriel
TDH平台提供对Squirrel工具的整合,Squirrel是用Java编写的图形化的Java客户端,允许查看以JDBC连接的数据库表的结构,浏览数据库对象,发出SQL命令等。
Pentaho
TDH平台提供与Pentaho的集成,Pentaho是一个以工作流为核心的、强调面向解决方案而非工具组件的BI套件,整合了多个开源项目,包括一个web server平台和几个工具软件:报表、分析、图表、数据集成、数据挖掘等。它偏向于与业务流程相结合的BI解决方案,侧重于大中型企业应用。它允许商业分析人员或开发人员创建报表,仪表盘,分析模型,商业规则和BI流程。
Elastic Search
TDH平台提供与Elastic Search集成,Elastic Search是一个基于Lucene的搜索服务器。它提供了一个分布式多租户的全文搜索引擎,基于RESTful web接口。Elastic Search是用Java开发的,设计用于云计算中,能够实时搜索,具有稳定、可靠、快速等特点,安装使用方便。
Hyperbase中提供了全文索引的功能,通过Elastic Search能够对Hyperbase中的数据进行全文检索。
Mahout
TDH平台提供对Mahout算法库的集成,Mahout提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多算法的实现,包括聚类、分类、推荐过滤、频繁子项挖掘。
TranswarpR
TDH平台提供TranswarpR的进行数据分析挖掘,TranswarpR 中封装了基于Spark的常用的机器学习算法库以及统计算法库,机器学习算法库包含逻辑回归、朴素贝叶斯、支持向量机、聚类、线性回归、推荐算法等,统计算法库包含均值、方差、中位数、直方图、箱线图等。
Kafka
TDH整合了分布式消息系统Kafka,Kafka是一个分布式、可分区、可复制的消息系统。它提供了普通消息系统的功能,但具有自己独特的设计:
- Kafka将消息以Topic为单位进行归纳;
- 向Kafka topic发布消息的程序称为Producers;
- 预订topics并消费消息的程序称为Consumer;
- Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker。
Producers通过网络将消息发送到Kafka集群,集群向消费者提供消息,如下图所示:
客户端和服务端通过TCP协议通信。Kafka提供了Java客户端,并且对多种语言都提供了支持。
升级改造过程
星环2014开始跟踪这个项目,遗留系统最大的工作量就是数据迁移,迁移的方式再多也可以归纳全量数据迁移和增量数据迁移两种。两种迁移方案不同如下。
- 全量数据和增量的共同点都需要优先布署一个新平台系统。
- 全量数据迁移需要专门的停服时间来保证数据的一致性,迁移前需要多次反复做消防演练,保证信服当天能够顺利成功 。
- 增量数据迁移不需要停服,但是相对全量需要较多的接口联调和系统适配。
融合计费清帐单涉及到将近1000TB的数据,关系到hbase、hdfs、mapreduce、hive等系统组件以及相关应用。经过星环专家评估后,应用迁移和系统迁移安全风险等级低,高的是数据迁移,没有合适的中间缓存区保存中间数据。经过多次商议和讨论后,我们采用的是全量数据迁移和增量数据迁移同时进行的办法。
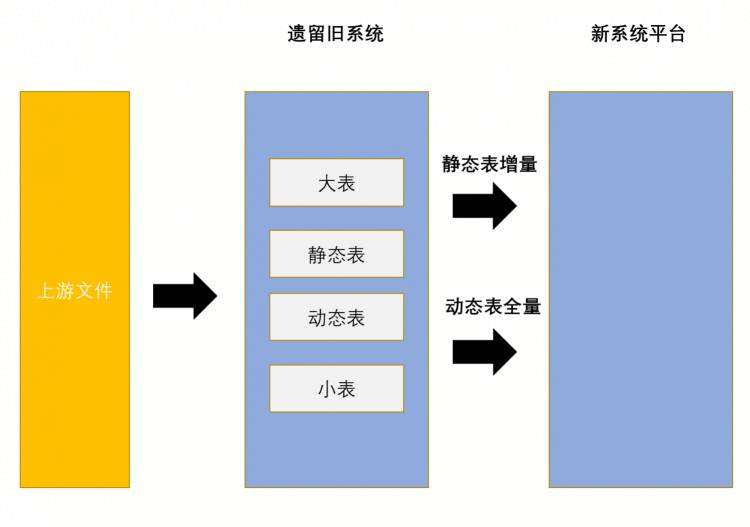
数据迁移
对梳理的表进行分级分类分为大表和小表、静态表和动态表,对小于10TB的表定义为小表,对大于10TB的表定义大表。静态表指数据量已经固化,恒定不变的表,动态表则指数据在实时变化中的表。
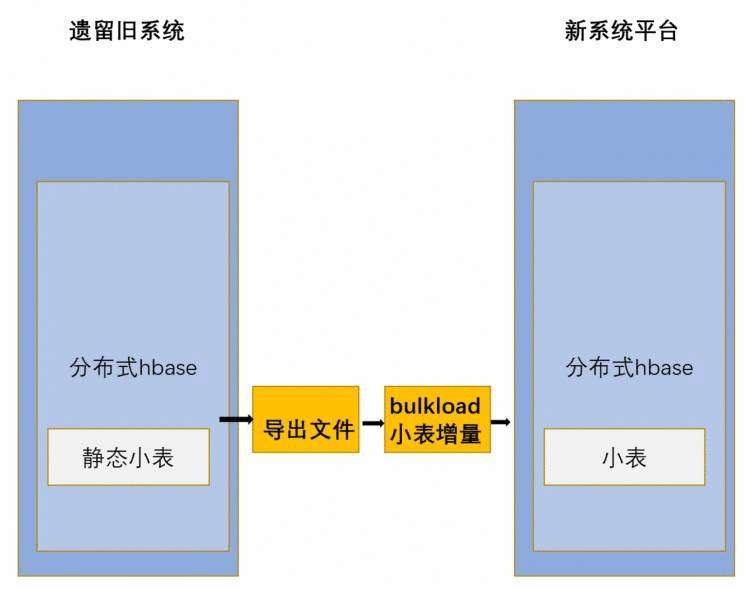
小表数据迁移,主要导出CSV文件的方式,然后通过新入库程序对其数据进行加工处理,导入到新系统平台。
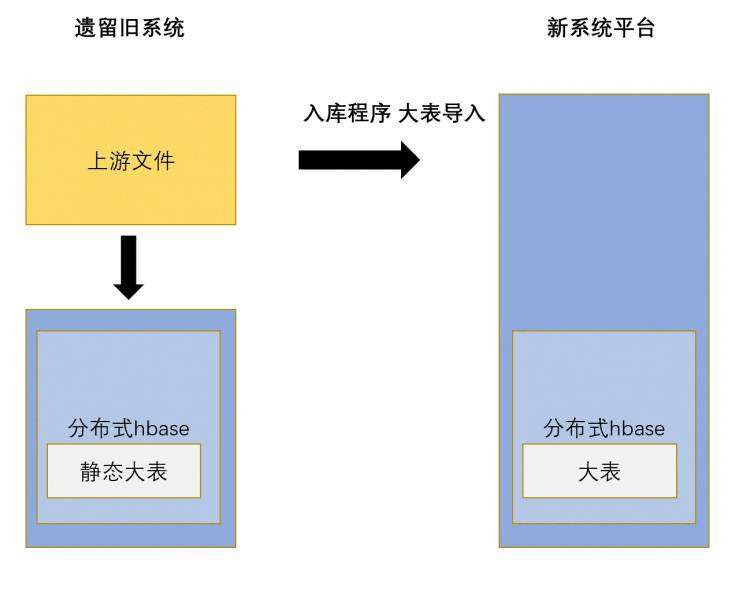
大表数据迁移,由于数据实在太大,羊毛长在羊身上,新入库程序对接上游的原始数据文件,将数据进行入库,同时验证新入库程序的性能。
针对动态表的数据迁移,由于动态表都是实时更新,所以停服让动态表的数据稳定下来,然后进行两边的数据同步,由于业务停顿时间不要太长,工程需要反复演练,保证两边口径和规范,相关hadoop参数调到最优。
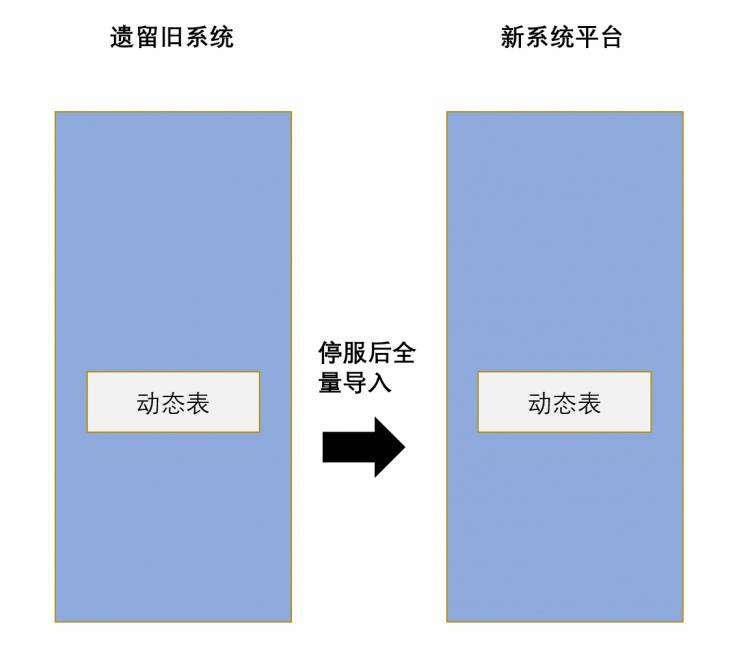
idh hadoop自带的是oozie调度管理,而且版本低,运行期间产生了大量的ETL任务,经过与甲方交流沟通,甲方认为ETL任务可以不迁移。同样,mysql数据库内部存储的hive元数据以及idh管理控制平台。
应用改造
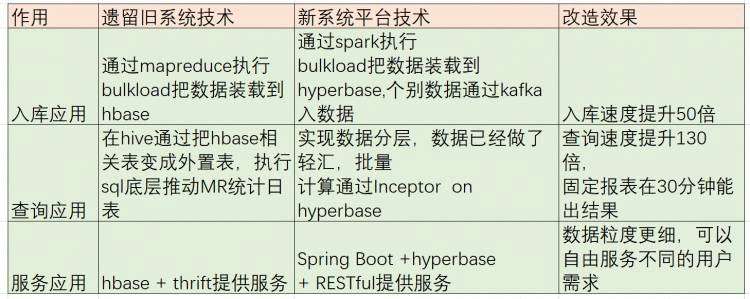
遗留系统的数据应用【hadoop1】在新平台系统【hadoop2】由于api和接口的环境变动,全部无法正常使用,改造目录如下
收益成果
THD成为广东省大数据融合计费清帐单的基础管理平台后 ,通过对清帐单数据的分层管理 ,实现数据域界限分明,数据层面达到轻汇、高汇的不同分工,进一步可以组装不同的数据模型,提供不同的数据服务,并对其他地市进行数据共享,对其它部门可以进行数据分发。
- 提升的效益明显,当初的固定报表需要第二天才能出结果,现在不到30分钟,BI工程师转移集中精力思考清帐单的数据模型如何服务其它部门和其它集市。星环以统一的结构支持多种不同的数据产品模型,也提高多种不同应用并存的可能性。
- 降低维护成本,星环自带监控报警管理系统,以统一的WEB界面对各个数据对象以及数据产品、业务库进行管理,网管理在一个视图可以宏观全局,点击展开也可以知道各个组件的工作状态。
- 知识性能力文档丰富,星环的技术性文档齐全,本身已经建立自己的社区网站,提供大数据证书培训。
- 安全等级提升,星环在一线城市都有分公司,并且承诺提供24小时的技术支持服务,响应快,服务周到。
- 兼容开源生态系统,虽然星环是自主研发的闭源架构,但是底层用的是apache hadoop,可以自由的与第三方系统集成。








 京公网安备 11010802041100号
京公网安备 11010802041100号