作者简介
Karthikeyan Rajendra
NVIDIA 数据科学团队产品经理,前GE工业物联网平台Predix 的首席产品经理,曾在高通、EMC和ZS Associates等公司担任重要的技术和战略岗位。Karthikeyan拥有加州大学洛杉矶分校MBA学位和亚利桑那州立大学的硕士学位。
孟东
NVIDIA 解决方案架构工程师,在大数据平台和加速器性能优化方面有着丰富的经验;负责与公共云服务厂商合作,为机器学习训练/推理和数据分析部署基于云的GPU加速解决方案。
朱禹
Alluxio软件工程师,负责元数据管理和端到端性能基准测试和优化;拥有加州大学伯克利分校博士学位,主攻数据中心的分布式数据管理系统和操作系统。
Adit Madan
Alluxio高级产品经理兼市场经理,同时也是 Alluxio开源项目的核心维护者和PMC成员。在加入 Alluxio 前曾担任惠普实验室的研究工程师,在分布式系统、存储系统和大规模数据分析方面拥有丰富的经验。Adit 拥有卡内基·梅隆大学硕士学位。
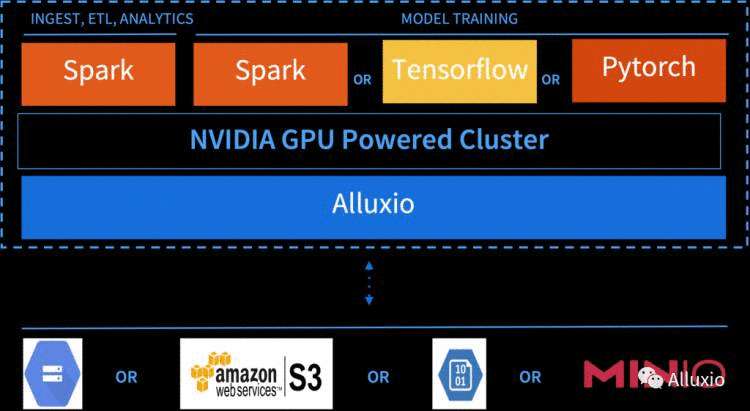
在数据工作流的各个阶段,包括从数据提取-转换-加载(ETL) 到分析和人工智能/机器学习(AI/ML)阶段使用Alluxio数据编排平台的部署架构。
如何通过用于RAPIDS Accelerator for Apache Spark和Alluxio在无需修改任何代码的情况下加速Spark SQL/Dataframe。
使用Alluxio和RAPIDS Accelerator for Apache Spark的最佳实践。
GPU加速的Apache Spark,TensorFlow 或PyTorch在使用 Alluxio时的部署选项。
01
02
03
数据加载
val df = spark.read.parquet("alluxio://ALLUXIO_MASTER_IP:PORT/foo")
--conf spark.rapids.alluxio.pathsToReplace="gs://foo->alluxio://ALLUXIO_MASTER_IP:PORT/foo"
val df = spark.read.parquet("gs://foo")
04
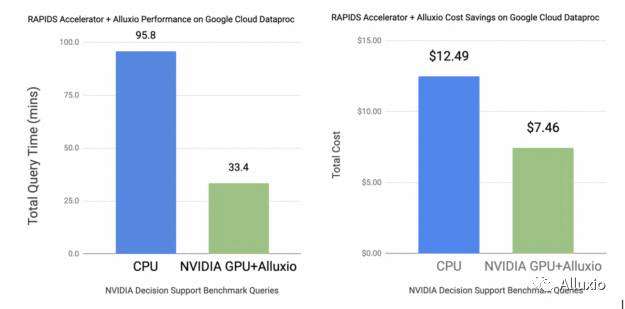
基准测试结果
05
06
想要了解更多有关RAPIDS 如何加速 Apache Spark 的 I/O 的信息,请注册GTC 2021大会演讲——“将RAPIDS加速器用于数据编排”。
想了解如何开始使用Alluxio和RAPIDS Accelerator for Apache Spark,请查阅此文档: https://nvidia.github.io/spark-rapids/docs/get-started/getting-started-alluxio.html
想获取RAPIDS Accelerator for Apache Spark 3.0相关信息和入门指南,请查阅GitHub repo:https://github.com/nvidia/spark-rapids
有关如何在Kubernetes 中使用Alluxio加速基于GPU的深度学习I/O的更多信息,请阅读开发者博客: https://www.alluxio.io/blog/efficient-model-training-in-the-cloud-with-kubernetes-tensorflow-and-alluxio/
近期活动
往期文章回顾
Alluxio 源码完整解析 | 你不知道的开源数据编排系统 (上篇)
Alluxio 源码完整解析 | 你不知道的开源数据编排系统 (下篇)
云知声 Atlas 超算平台: 基于 Fluid + Alluxio 的计算加速实践(上)
云知声 Atlas 超算平台: 基于 Fluid + Alluxio 的计算加速实践(下)
Alluxio
微信公众号 | Alluxio
新浪微博 | Alluxio2021
















 京公网安备 11010802041100号
京公网安备 11010802041100号