【文章来源】
A Transition-based Algorithm for AMR Parsing:http://aclweb.org/anthology/N/N15/N15-1040.pdf
我们提出了一个两阶段框架来解析一个句子到它的抽象意义表示(AMR)。 我们首先使用依赖解析器为句子生成依赖关系树。在第二阶段,我们设计了一种新的基于转换的算法,该算法将依赖树转换为AMR图。这种方法有几个优点。首先,依赖项解析器可以在比树到图算法的训练集大得多的训练集上进行训练,从而总体上得到更准确的AMR解析器。与以前的最佳结果相比,我们的解析器在F-measure中的绝对值提高了5%。其次,我们设计的动作在语言上是直观的,并且捕获了依赖结构和句子的AMR之间的映射的规律性。第三,尽管O(n2)的最坏情况复杂,我们的解析器在实践中几乎是线性的。
抽象意义表示(AMR)是一个有根,有向,边缘标记和叶子标记的图形,用于表示句子的含义。 AMR形式主义已被用于注释AMR注释语料库(Banarescu等,2013),这是一个仍在进行扩展的超过一万个句子的语料库。 AMR表示的构建块是它们之间的概念和关系。理解这些概念及其关系对于理解句子的含义至关重要,并且可能有益于许多自然语言应用,例如信息提取,问答和机器翻译。
使AMR成为图形而不是树的属性是AMR允许重入,这意味着相同的概念可以参与多个关系。将句子解析为AMR似乎需要基于图形的算法,但是从我们熟悉的典型基于树的算法转向基于图形的算法是计算复杂性方面的一大步。实际上,在开发语法和有效的基于图形的算法方面已经付出了相当多的努力,这些算法可用于解析AMR(Chiang et al。,2013)。
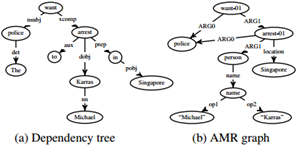
图1:句子的依赖树和AMR图,“警方希望在新加坡逮捕Micheal Karras。”
然而,在语言学上,AMR与句子的依赖结构之间存在许多相似之处。两者都将关系描述为头部与其依赖之间或父母与其子女之间的关系。 AMR概念和关系从实际的单词标记中抽象出来,但是它们的映射有规律性。内容词通常成为概念,而功能词要么成为关系,要么如果它们对句子的含义没有贡献则被省略。如图1所示,AMR中省略了依赖关系树中的“the”和“to”,介词in成为类型location的关系。在AMR中,重入也用于表示共同引用,但这仅在某些有限的上下文中发生。在图1中,“police”既是“逮捕”的一个参数,也是“want”作为控制结构的结果。这表明可以将依赖性树转换为具有有限数量的动作的AMR,并且学习模型以确定在给定对齐的依赖性树和AMR对作为训练数据的情况下采取哪种动作。
这是我们在当前工作中采用的方法,我们提出了一个基于过渡的框架,在该框架中,我们将一个句子解析为AMR,方法是将该句子的依赖树作为输入,并通过一系列操作将其转换为AMR表示。这意味着将句子分两步解析为AMR。在第一步中,将句子解析为具有依赖性解析器的依赖性树,并且在第二步中,将依赖性树转换为AMR图。这种方法的一个优点是依赖性解析器不必在与AMR传感器的依赖性相同的数据集上进行训练。这使我们能够在比AMR注释语料库大得多的数据集上使用更精确的依赖解析器,并拥有更有利的起点。我们的实验表明,这种方法是非常有效的,并且通过Smatch度量(Cai和Knight,2013)测量,在F-score中比先前报道的最佳结果(Flanigan等人,2014)产生5%绝对值的改善。
本文的其余部分如下。 在§2中,我们描述了如何将句子中的单词标记与其AMR对齐以创建跨度图,基于该跨度图,我们将上下文信息提取为特征并执行操作。 在§3中,我们提出了基于转换的解析算法,并描述了用于将句子的依赖关系树转换为AMR的动作。 在§4中,我们提出了学习算法和我们提取的特征来训练过渡模型。 在§5中,我们提出了实验结果。 §6描述了相关工作,我们在§7中作了总结。
与句子的依赖结构不同,其中每个单词标记是依赖树中的节点,并且在句子中的单词标记和依赖树中的节点之间存在固有的对齐,AMR是抽象表示,其中字顺序为 不保留相应的句子。 此外,有些词语成为抽象概念或关系,而其他词语只是被删除,因为它们没有对意义做出贡献。 单词令牌和概念之间的对齐是很重要的,但是为了学习从依赖树到AMR图的转换,我们必须首先建立句子中的单词令牌和AMR中的概念之间的对齐。我们使用JAMR附带的对准器(Flanigan等,2014)来产生这种对齐。 JAMR对齐器试图将AMR图中的每个概念或图片片段与句子中的连续单词标记序列进行贪婪对齐。
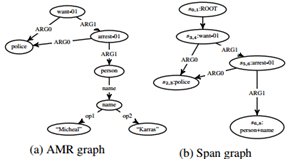
图2 句子的AMR图及其跨度图,“警察想要逮捕Micheal Karras。”
我们使用一种称为跨度图的数据结构来表示与句子中的单词标记对齐的AMR图。对于每个句子,
图3 折叠节点
例如,给定图2a中的AMR图GAMR,其跨度图G可以表示为图2b。在跨度图G中,节点s3,4的句子跨度是(want)并且其概念标签是want-01,其表示AMR中的单个节点want-01。为了简化对齐,在从AMR创建跨度图时,我们还会折叠一些AMR子图,使得它们可以确定性地恢复到其原始状态以进行评估。例如,AMR子图中与span(Micheal,Karras)对应的四个节点折叠为跨度图中的单个节点s6,8,并分配了概念标签person + name,如图3所示。因此,我们的模型预测的概念标签集既包括原始AMR图中的概念,也包括折叠AMR子图的结果。
以这种方式表示AMR图允许我们将AMR解析问题表示为联合学习问题,其中我们可以设计一组动作来同时预测AMR图中的概念(节点)和关系(弧)以及它们上的标签。
与基于转换的依赖解析(Nivre,2008)类似,我们将AMR解析的转换系统定义为四元S =(S,T,s0,St),其中
•S是一组解析状态(配置)。
•T是一组解析动作(转换),每个动作都是一个函数t:S→S。
•s0是初始化函数,将每个输入句子w及其依赖关系树D映射到初始状态。
•St⊆S是一组终端状态。
我们基于转换的解析器的每个状态(配置)都是三元组(σ,β,G)。σ是存储未处理的节点的索引的缓冲区,我们写表示是σ的最顶层元素。 β也是缓冲区![\left [ \beta _0, \beta _1,..., \beta _j \right ]](https://img.php1.cn/3cd4a/1eebe/cd5/b386c433a16f5497.webp)
我们为动作集T定义了8种类型的动作,如表1所示。动作集可以根据缓冲区β的条件分为两类。 当β不为空时,根据边(σ0,β0)做出解析决策;另外,只检查当前节点σ0。此外,为了同时决定概念/关系标签的分配,我们使用额外的参数lr或lc来增加一些动作。 我们定义γ:V→LV作为节点的概念标记函数,δ:A→LA作为弧的关系标记函数。 因此δ[(σ0,β0)→lr]意味着将关系标记lr分配给arc(σ0,β0)。 所有动作都更新缓冲区σ,β并将一些变换G⇒G0应用于局部图。下面描述了8个动作。
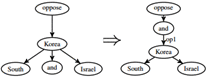
图4 SWAP动作
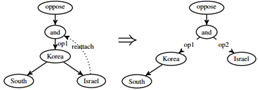
图5 REATTACH动作

图6 REPLACE-HEAD动作
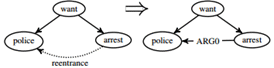
图7 REENTRANCE动作
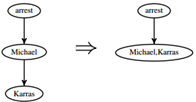
图8 MERGE动作
当β为空时,表示节点σ0的所有输出弧已经处理或σ0没有输出弧,可以应用以下两个动作:
在解析长度为n的句子(不包括特殊根符号w0)时,其对应的依赖树将具有n个节点和n-1个弧。对于基于投影过渡的依赖性解析,解析器需要采取精确的2n-1步或动作。所以复杂性是O(n)。但是,对于上面定义的树到图解析器,所需的操作不再受句子长度的线性限制。假设在解析过程中没有REATTACH,REENTRANCE和SWAP动作,算法将遍历依赖树中的每个节点和边缘,这导致2n个动作。但是,REATTACH和REENTRANCE操作会添加需要重新处理的额外边缘,SWAP操作会添加需要重新访问的节点和边缘。由于所有可能的额外边缘的空间是(n-2)2并且重新访问它们只是线性地添加更多动作,所以我们的算法的总渐近运行时复杂度是O(n2)。
然而,在实践中,由于依赖树和句子的AMR图之间的相似性,REATTACH动作的应用数量远小于最坏情况。此外,AMR中具有重入的节点仅占所有节点的一小部分,从而使REENTRANCE操作在恒定时间发生。这些允许树到图解析器在实践中以近乎线性的时间解析句子。
我们的解析算法类似于(Sartorio等,2013)中的解析器。在每个解析状态s∈S,算法贪婪地选择最大化得分函数得分()的解析动作t∈T。得分函数是在解析动作t和解析状态s上定义的线性模型。
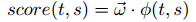
其中
正如(Bohnet和Nivre,2012)中所指出的,可以添加约束来限制在第3行评估的可能操作的数量。可能存在对状态的正式约束,例如不应该两次应用SWAP操作的约束到同一对节点。我们还可以应用软约束来过滤REATTACH和REENTRANCE的不太可能的概念标签,关系标签和候选节点k。在我们的解析器中,我们强制执行约束,即NEXT-NODE-lc只能从与训练数据中当前节点的引理共同出现的概念标签中进行选择。我们还根据经验设定了REATTACHk只能在σ0的祖父母和曾祖父母中选择k的约束。此外,REENTRANCEk只能在其兄弟姐妹中选择k。这些约束极大地减少了搜索空间,从而加速了解析器。
如3.2节所述,我们模型的参数是得分函数中的权向量
对于训练语料库中的每个句子w及其对应的AMR注释GAMR,我们可以使用依赖性解析器获得w的依赖关系树Dw。 然后我们将GAMR表示为跨度图Gw,它作为我们的学习目标。学习算法根据算法1获取训练实例(w,Dw,Gw),解析Dw,并使用当前权重向量获得最佳动作。当前状态s的黄金动作由咨询跨度图Gw给出,我们将其表示为函数oracle()(第5行)。如果gold动作等于我们从解析器获得的最佳动作,那么最佳动作将应用于当前状态;否则,我们更新权重向量(第6-7行)并通过应用gold动作继续解析过程。
对于基于转换的依赖性解析器,解析状态的特征上下文由包含部分解析的堆栈中的单词标记的相邻元素或包含未处理的单词标记的缓冲区表示。相反,在我们的treeto图解析器中,如前所述,缓冲区σ和β仅指定接下来要检查的弧或节点。与当前弧或节点相关联的特征上下文主要从部分图G中提取。结果,特征上下文对于不同类型的动作是不同的,这使得我们的解析器与标准的基于转换的依赖性解析器非常不同。例如,在评估动作SWAP时,我们可能对关于各个节点σ0和β0的特征以及涉及弧的特征(σ0,β0)感兴趣。相反,在评估动作REATTACHk时,我们不仅要提取涉及σ0和β0的特征,还要提取有关重新连接的节点k的信息。为了解决这个问题,我们将特征上下文定义为
单节点特征是涉及每个候选状态-动作对中涉及的所有可能节点的原子特征。我们还包括路径特征和距离特征,如(Flanigan等,2014)中所述。路径特征表示为部分图中节点x和y之间的路径上的依赖性标签和词性。在这里,我们将它与起始节点和结束节点的引理结合起来。距离特征是句子中两个节点x,y的跨度之间的标记数。特定于操作的功能记录应用于给定节点的操作的历史记录。例如,记录节点β0被交换的次数。我们将此功能与节点β0的引理结合起来,以防止解析器交换节点太多次。记录已被节点β0替换的节点的单词特征。此功能有助于预测关系标签。如上所述,在AMR图中,一些功能词被删除为节点,但它们在确定其子和父之间的关系标签时至关重要。
我们的实验是在AMR Annotation Corpus(LDC2013E117)的新闻专线部分(Banarescu等,2013)进行的。我们遵循Flanigan等人的观点建立train/development/test split分组以便于比较:以文件年份1995-2006为标准的4.0k句子作为训练集;将2007年文件作为发展集的2.1k句;将2008年文档作为测试集的2.1k句子,仅使用标记为::首选的AMR。每个句子w都使用Stanford CoreNLP工具包(Manning等,2014)进行预处理,以获得部分语音标签,名称实体信息和基本依赖关系。我们已经验证了Stanford CoreNLP工具包和AMR Annotation Corpus的训练数据之间没有重叠。我们使用Smatch工具(Cai和Knight,2013)评估我们的解析器,该工具旨在最大化两个AMR注释之间的语义重叠。
关于我们上面提到的过渡系统的一个问题是,这里定义的动作集是否可以涵盖涉及依赖于AMR变换的所有情况。虽然正式的理论证明超出了本文的范围,但我们可以凭经验验证行动集在实践中运作良好。为了验证动作,我们首先为每个句子w及其依赖树Dw运行oracle()函数以获得“伪金”。然后我们将与表示为跨度图Gw的金标准AMR图进行比较,看它们是多么相似。在训练数据上,我们得到了所有对的F分数为99%,这表明我们的动作集能够通过一系列动作将每个句子w及其依赖树Dw转换为其金标准AMR图。
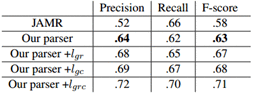
表3给出了Smatch在测试集上给出的解析器的精度,召回率和F值。我们的解析器获得63%的F分数(第3行),结果比使用相同的训练和测试集(第2行)在(Flanigan等人,2014)中报告的第一个公布结果好5%。我们还通过用黄金关系标签或/和黄金概念标签替换解析图来对测试集进行实验。我们可以在表3中看到,当提供黄金概念和关系标签作为输入时,解析准确度提高了大约8%的F得分(第6行)。当解析器仅提供黄金关系标签(第4行)或黄金概念标签(第5行)时,第4行和第5行显示结果,并且结果预期低于提供黄金概念和关系标签作为输入的结果。
表3 测试集结果。这里lgc - gold概念标签;lgr -黄金关系标签;lgrc -黄金概念标签和黄金关系标签。
句子中的单词标记与AMR图中的概念之间的错误对齐占我们AMR解析错误的很大一部分,但是这里我们关注从依赖树到AMR图的转换中的错误。因为在我们的解析模型中,解析过程已经被分解为应用于输入依赖关系树的一系列动作,我们可以在解析期间使用oracle()函数为我们提供正确的动作tg以获取给定的状态s。tg与我们的解析器实际采取的最佳动作之间的比较将让我们了解每种动作的应用准确程度。当我们比较动作时,我们关注AMR解析的结构方面,并且只考虑八种动作类型,忽略附加到它们的概念和边缘标签。例如,当我们计算错误时,NEXT-EDGE-ARG0和NEXT-EDGE-ARG1将被视为相同的动作并计为匹配,即使附加到它们的标签不同。
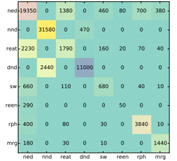
图9 动作的混淆矩阵。垂直方向经过正确的操作类型,水平方向经过解析的操作类型。
图9显示了混淆矩阵,它表示解析器预测的操作与oracle()函数给出的正确操作之间的比较。它表明NEXT-EDGE (ned),NEXTNODE (nnd),和 DELETENODE (dnd)动作占了很大一部分动作。这些操作也更准确地应用。正如所料,解析器在涉及REATTACH (reat), REENTRANCE (reen) 和SWAP (sw)操作时会犯更多错误。REATTACH操作通常用于纠正依赖性解析器所产生的PP附着错误,或者重新调整SWAP操作产生的结构,并且考虑到相对较小的AMR训练集,很难学习。SWAP操作通常与协调结构相关联,其中依赖结构中的头部和AMR图形发散。在斯坦福依赖表示中,它是我们解析器的输入,协调结构的头部是其中一个合取。对于AMR,头部是一个由协调连接之一发出信号的抽象概念。这也是最难学习的行动之一。然而,我们期望随着AMR Annotation Corpus变大,在更大的训练集上训练的解析模型将更好地学习这些动作。
我们的工作与第一个发布的AMR解析器JAMR(Flanigan等,2014)直接相当。 JAMR分两个阶段执行AMR解析:概念识别和关系识别。他们将概念识别视为序列标记任务,并利用半马尔可夫模型将句子中的单词跨度映射到概念图片段。对于关系识别,他们采用基于图的技术进行非投影依赖性解析。他们提出了一种算法,用于找到从第一阶段获得的概念片段的最大跨越连通子图(MSCG),而不是在文字上找到最大得分树。相比之下,我们采用基于过渡的方法,在基于过渡的依赖性解析中找到它的根源(Yamada和Matsumoto,2003; Nivre,2003; Sagae和Tsujii,2008),其中执行一系列动作以将句子转换为依赖树。但是,从我们的描述中可以清楚地看出,我们的解析器中的操作在本质上与基于转换的依赖项解析中使用的操作非常不同。还有另一种研究尝试设计图形语法,如超边界替换语法(HRG)(Chiang et al。,2013)和有效的基于图形的AMR解析算法。沿着这条线的现有工作仍然是理论性的,尚未报告实证结果。
我们提出了一种新的基于转换的句法分析算法,该算法以句子的依赖树为输入,通过一系列动作将句子的依赖树转化为抽象意义表示图。我们证明我们的方法在语言上是直观的,我们的实验结果也表明我们的解析器比以前最好的报告结果有显著的优势。在未来的工作中,我们计划通过改进学习和解码技术来继续完善解析器。








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有