作者:pigwangrq | 来源:互联网 | 2023-10-12 14:49
数据湖就像是一个“ 大水池” , 是一种把各类异构数据进行集中存储的架构。 数据湖是一种存储架构, 在阿里云上可以利用 OSS 对象存储, 来当数据湖的地基。 企业基于阿里云服务, 可以快速挖出一个适合自己的"湖", 而且这个"湖"根据需求, 可大可小, 按"注水量"付费。 在挖好这个"湖"后, 重要的步骤就是如何把各种异构数据注入到湖里。 在传统的大数据领域用户经常使用 HDFS 作为异构数据的底层存储来储存大量的数据, 其中大部分可通过离线数据迁移来注入到以 OSS 作为底层存储的数据湖中。 在进行数据迁移、 数据拷贝的场景中, 大家选择最常用的离线数据迁移工具是 Hadoop 自带的 DistCp 工具, 但是它不能很好利用对象存储系统如 OSS 的特性, 导致效率低下并且不能最终保证一致性, 提供的功能选项也比较简单, 不能很好的满足用户的需求。 此时一个高效、 功能丰富的离线数据迁移工具成为影响离线数据入湖效率的重要因素。
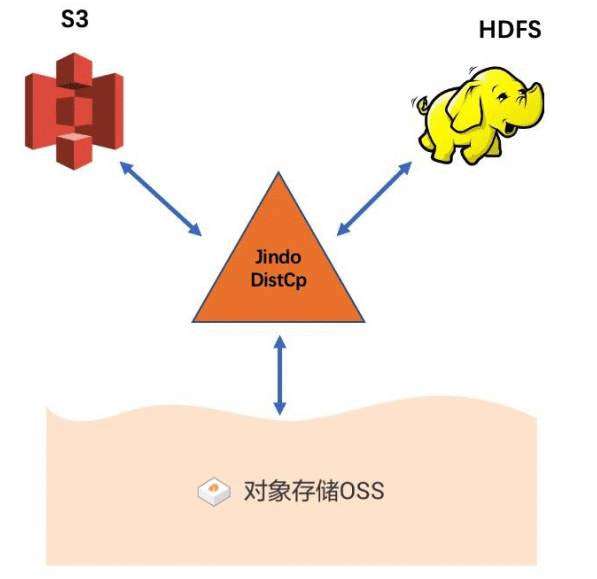
随着阿里云 JindoFS SDK 的全面放开使用, 基于 JindoFS SDK 的数据湖离线数据迁移利器 JindoDistCp 现在也全面面向用户开放使用。 JindoDistCp 是阿里云E-MapReduce 团队开发的大规模集群内部和集群之间分布式文件拷贝的工具。 它使用MapReduce 实现文件分发, 错误处理和恢复, 把文件和目录的列表作为 map/reduce 任务的输入, 每个任务会完成源列表中部分文件的拷贝。 目前全面支持 HDFS/S3/OSS 之间的数据拷贝场景, 提供多种个性化拷贝参数和多种拷贝策略。 重点优化从 HDFS 和 S3 到数据湖底座 OSS 的数据拷贝场景, 通过定制化 CopyCommitter, 实现 No-Rename 拷贝, 并保证数据拷贝落地的一致性。 功能覆盖 S3DistCp 和 HadoopDistCp 的功能, 性能较 HadoopDistCp 有较大提升, 目标提供高效、 稳定、 安全的数据湖离线数据迁移工具。
本文主要介绍如何使用 JindoDistCp 来进行基本离线数据迁移, 以及如何在不同场景下提高离线数据迁移性能。 值得一提的是, 此前 JindoDistCp 仅限于 E-MapReduce 产品内部使用, 此次全方位面向整个阿里云 OSS/HDFS 用户放开, 并提供官方维护和支持技术,欢迎广大用户集成和使用。
HadoopDistCP
HadoopDistCp 是 Hadoop 集成的分布式数据迁移工具, 提供了基本文件拷贝、 覆盖拷贝、 指定 map 并行度、 log 输出路径等功能。 在 Hadoop2x 上对 DistCp 进行了部分优化例如拷贝策略的选择, 默认使用 uniformsize( 每个 map 会平衡文件大小) 如果指定dynamic, 则会使用 DynamicInputFormat。 这些功能优化了普通 hdfs 间数据拷贝, 但是对于对象存储系统如 OSS 缺少数据写入方面的优化。
S3DistCp
S3DistCp 是 AWS 为 S3 上存储提供的 distcp 工具, S3DistCp 是 HadoopDistCp的扩展, 它进行了优化使得其可以和 S3 结合使用, 并新增了一些实用功能。 新增功能如增量复制文件、 复制文件时指定压缩方式、 根据模式进行数据聚合、 按照文件清单进行拷贝等。
JindoDistCp
JindoDistCp 是一个简单易用的分布式文件拷贝工具, 目前主要用在 E-Mapreduce集群内, 主要提供 HDFS 和 S3 到 OSS 的数据迁移服务, 相比于 HadoopDistCp 和S3DistCp, JindoDistCp 做了很多优化以及新增了许多个性化功能, 并且深度结合 OSS对象存储的特性, 定制化 CopyCommitter, 实现 No-Rename 拷贝, 大大缩短离线数据入湖迁移时间消耗。
本文地址:https://blog.csdn.net/asmartkiller/article/details/108877516











 京公网安备 11010802041100号
京公网安备 11010802041100号