TensorFlow 和 PyTorch 的框架之争愈演愈烈。二者各有优缺点,选择起来需要费一番脑筋。但是,有句话说得好,「小孩子才做选择,成年人全都要」。为此,来自Petuum Inc 和卡内基梅隆大学的研究者开源了一个通用机器学习包——Texar-PyTorch,结合了 TensorFlow 和 PyTorch 中的许多实用功能与特性。

项目地址:https://github.com/asyml/texar
Texar-PyTorch 对各类不同的机器学习任务有着广泛的支持,尤其是自然语言处理(NLP)和文本生成任务。
基于其已有的 TensorFlow 版本,Texar-PyTorch 结合了 TensorFlow 和 PyTorch 中的许多实用功能与特性。同时,Texar-PyTorch 具有高度可定制性,提供了不同抽象层级的 API,以方便新手和经验丰富的用户。
Texar-PyTorch 将实用的 TensorFlow (TF) 模块融合进了 PyTorch,显著增强了 PyTorch 现有的功能。这些模块包括:
Texar-PyTorch 功能
通过结合 TF 中的最佳特性与 PyTorch 的直观编程模型,Texar-Pytorch 为构建 ML 应用提供全面支持:
代码示例 1 演示了使用 Texar-PyTorch 搭建并训练用于摘要生成或机器翻译的条件GPT-2 模型的完整代码。
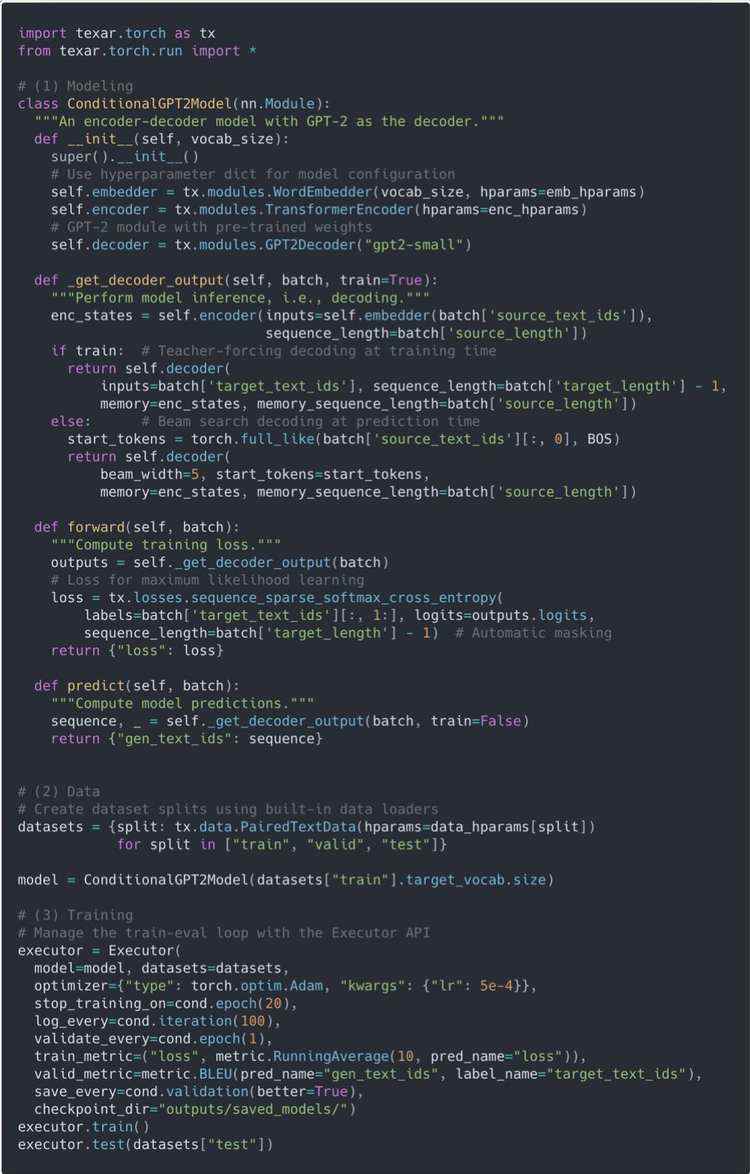 代码示例 1:使用 Texar-PyTorch 搭建并训练条件 GPT-2 模型 (用于摘要生成等任务)。
代码示例 1:使用 Texar-PyTorch 搭建并训练条件 GPT-2 模型 (用于摘要生成等任务)。
为何选择 Texar?
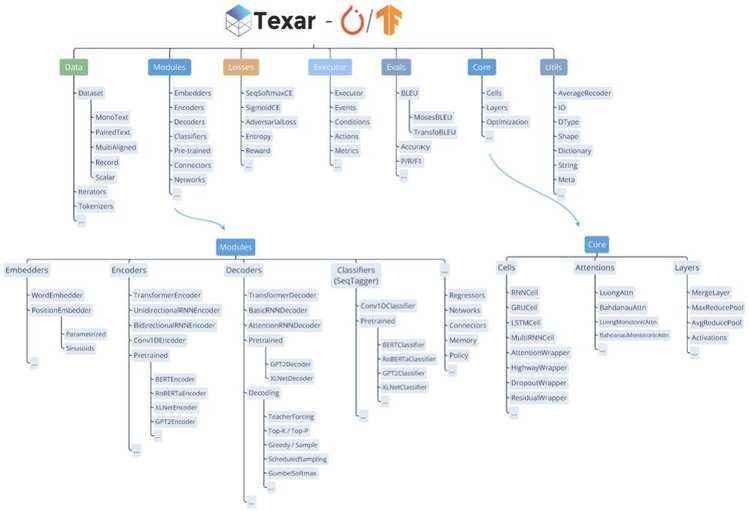
图 1:Texar 为数据处理、模型架构、损失函数、训练、评估以及一系列先进的预训练 ML/NLP 模型 (例如,BERT, GPT-2 等) 提供了全套的模块。
接下来将更详细地介绍 Texar-PyTorch 中建模、数据处理和模型训练这三个关键部分。
建模模块
如图 1 所示,Texar-Pytorch 提供了全套的 ML 模块集。通过精心设计的界面,用户可以通过组合模块自由地构建任意模型。
下面的实例展示了如何灵活运用模块接口,以满足不同的机器学习算法的需要,如最大似然学习和对抗性学习。此外,Texar 为具有不同专业知识的用户提供多个抽象层级的接口。例如:
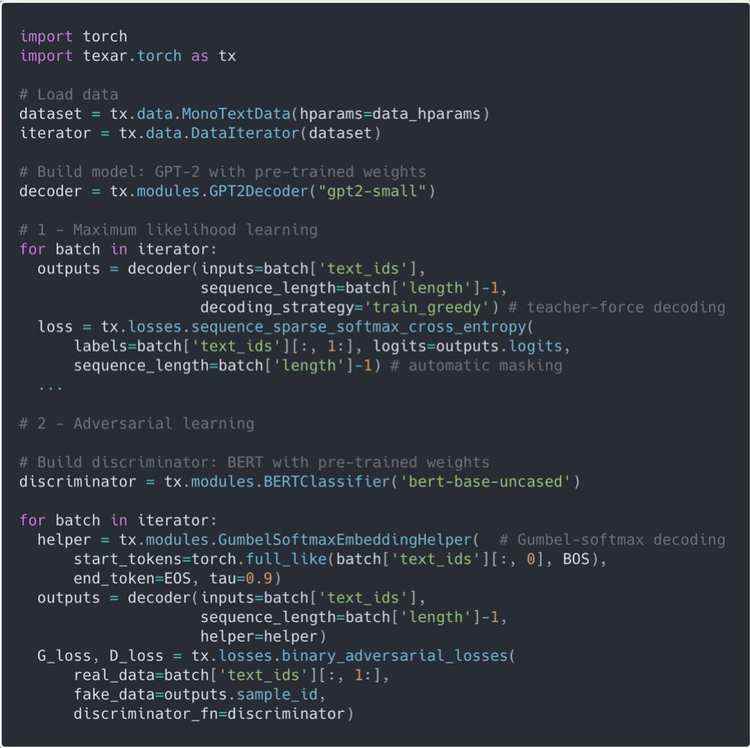
代码示例 2:构建预训练的 GPT-2 语言模型,使用最大似然学习和对抗学习 (使用 BERT 作为判别器) 进行微调。
总之,使用 Texar-PyTorch 建模具有以下主要优势:
数据
Texar-Pytorch 的数据模块旨在为任意 ML 和 NLP 任务提供简单、高效和可自定义的数据处理。结合 Tensorflow tf.data 中的最佳实践,这些模块极大地增强了 Pytorch 内置的 DataLoader 模块:
解耦单个实例预处理和批次构建 – 以获得更清晰的程序逻辑和更简便的自定义。
基于缓冲区的随机打乱、缓存和惰性加载 – 以提高效率。
通用的数据集迭代器 – 无需额外的用户配置。
更直观的 APIs – 在项目中获得最佳实践不需要任何专业知识。
Texar-PyTorch 内置数据模块
对于常见类型的数据集,Texar-Pytorch 已经包含了可以使用的模块,如下图 2 所示。
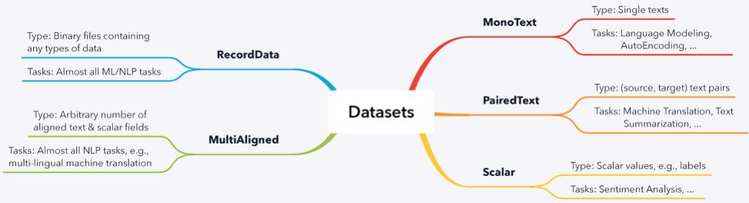
图 2:Texar-Pytorch 内置大量 ML 和 NLP 任务的数据模块。
特别的是,RecordData 相当于 TensorFlow 著名的 TFRecordData,后者以二进制格式读取文件,从而允许从文本到图像的任意数据类型。太酷了,不是吗?更重要的是 – 它的使用方式与 TFRecordData 类似。下面的例子说明了一切。
假设你想运行一个图像描述模型。每个数据示例通常包含一个图像、一个描述和其他元信息。如何使用 Texar-Pytorch 如下。

代码示例 3:使用 Texar-Pytorch RecordData 加载复杂的图像标题数据。
创建自定义数据集
用户可以自定义如何处理数据实例和创建批次,而 Texar 将为你处理缓存、惰性处理和迭代。下面的示例说明了这一点。
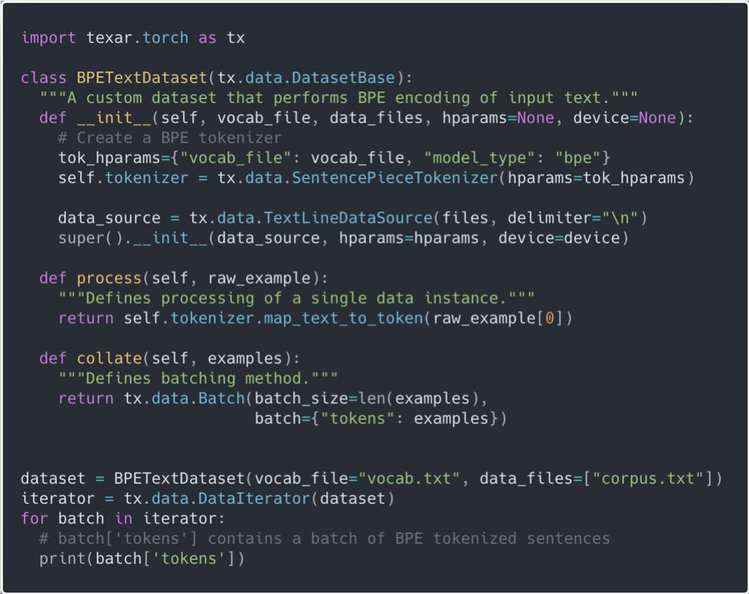
代码示例 4:对输入文本执行 BPE 分词的自定义数据集。
训练器
每当开始一个新的项目时,你是否厌烦了一次又一次地编写训练和评估代码?你是否需要一个 API 来实现自动化训练,并配备日志记录、保存中间模型、可视化和超参数调优功能? 你是否希望 API 灵活适应你的非传统算法,例如,在对抗学习中交替优化多个损失函数?Texar 训练器(Executor)是你的不二选择。
Executor 与广泛使用的 TF Estimator 和 tf.keras.Model 类似,但是更加轻量级,更易自定义。
为了演示 Executor 的功能,开发者展示了一般的训练代码,并与 Executor 作对比:
假设我们希望在项目中具有以下功能:
上面的步骤描述了一个很常见的训练循环。以下是一般的训练循环的实例:
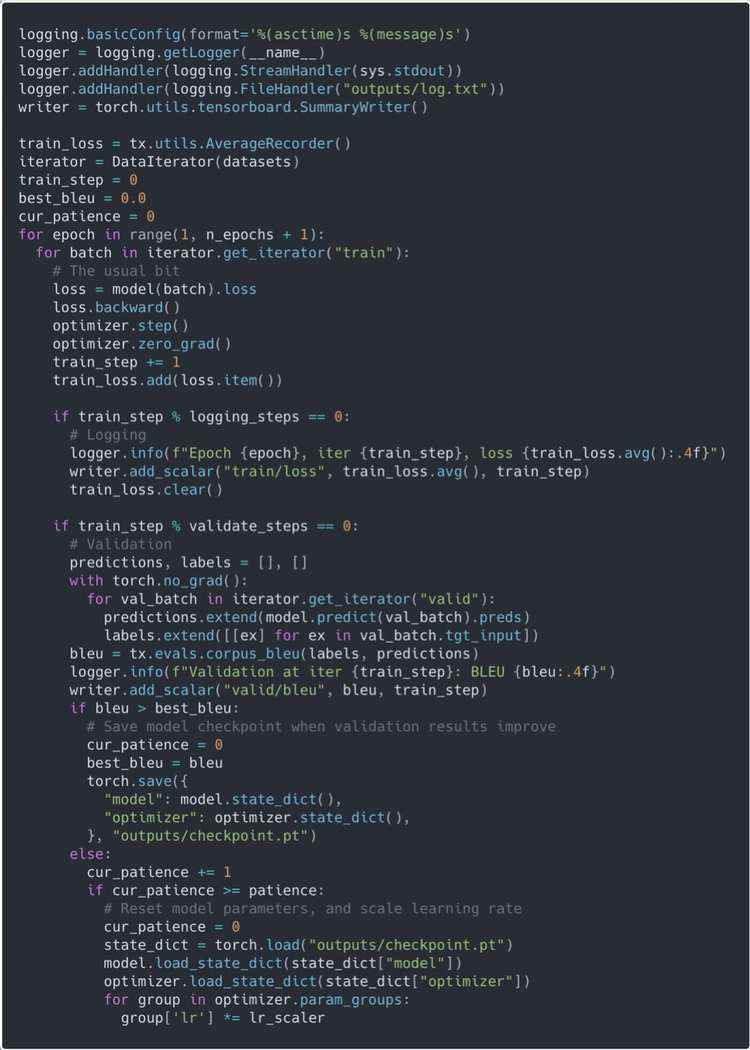
代码示例 5:典型的手写 train-eval 循环。
代码非常冗长。当你需要添加或更改一些功能时,事情会变得更加复杂。现在,如果使用 Executors,该代码将是什么样子?
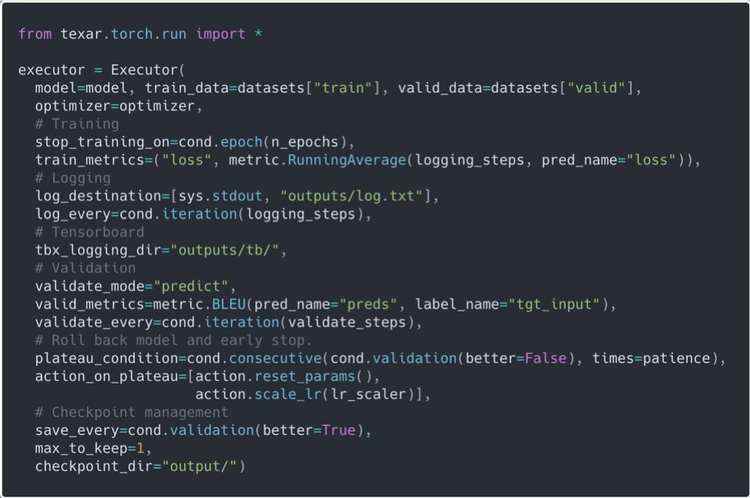
代码示例 6:使用 Executor 的相同 train-eval 循环。
Executor 在命令行的输出如下:

在这里,你可以看到验证 BLEU 分数是根据已有结果不断更新的。这要归功于 Executor 流处理度量,它允许对度量值进行增量计算。无需等到最后才能看到验证集的结果!
正如我们所见,使用 Executor 的代码结构化更强,可读性更高。它还具有更强的可扩展性:
问:如果我们还想在每个周期结束后在验证集上评估呢?
答:只需将` validate_every` 更改为:

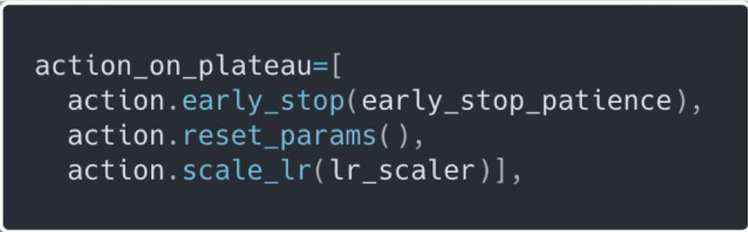
问:如果我们想在调整学习率`early_stop_patience`次后提前停止训练呢?
答:只需将`action_on_plateau`改为:
问:如果我们还想测量单词级别的损失呢?
答:只需在`valid_metrics`中添加一个新的度量即可:

问:如果我们想要进行超参数调优并多次训练模型,该怎么办?
答:只需为你想要测试的每一组超参数创建 Executor。由于 Executor 负责模型创建之外的所有进程,所以不需要担心消耗额外的内存或意外地保留以前运行的对象。这是一个在 Hyperopt 中使用 Executor 的示例。
问:如果在每个周期结束后,我们想把当前的模型权重上传到服务器,发送一封电子邮件汇报进度,然后出门去遛狗,该如何操作?
答:很奇怪,但没问题。只需在你选择的条件下注册一个自定义操作,并做你想做的任何事情:

Texar-TF 与 Texar-PyTorch 互相切换
如果你是 Texar-TF 用户,毫不费力就可切换到 Texar-PyTorch。相比 Texar TensorFlow,Texar PyTorch 具有几乎相同的接口,可以轻松切换底层框架。
尽管有类似的接口,但开发者也遵循每个框架的编码风格,这样你无需学习一种新的子语言。为此,他们更改了一些较低层级的可扩展接口,以便紧密匹配对应框架的原生设计。大多数更改都在数据和训练器模块中,但正如你所见,它们非常容易上手。
开始使用 Texar-PyTorch
请访问该项目的 GitHub repository,并按照安装说明进行操作。实用的资源包括:











 京公网安备 11010802041100号
京公网安备 11010802041100号