TCP服务端支持并发
解决方式:开多线程
服务端
基础版
import socket
"""
服务端1.要有固定的IP和PORT2.24小时不间断提供服务3.能够支持并发
"""server = socket.socket()
server.bind(('127.0.0.1',8080))
server.listen(5)def talk(conn):while True:try:data = conn.recv(1024)if len(data) == 0:breakprint(data.decode('utf-8'))conn.send(data.upper())except ConnectionResetError as e:print(e)breakconn.close()while True:conn, addr = server.accept() # 监听 等待客户端的连接 阻塞态print(addr)
进阶版:支持并发
import socket
from threading import Thread # ①多导入了这个"""
服务端1.要有固定的IP和PORT2.24小时不间断提供服务3.能够支持并发
"""server = socket.socket()
server.bind(('127.0.0.1',8080))
server.listen(5)def talk(conn):while True:try:data = conn.recv(1024)if len(data) == 0:breakprint(data.decode('utf-8'))conn.send(data.upper())except ConnectionResetError as e:print(e)breakconn.close()while True:conn, addr = server.accept() # 监听 等待客户端的连接 阻塞态print(addr)t = Thread(target=talk,args=(conn,)) # ②加了这个t.start() # ③加了这个
客户端
import socket
# 客户端都是一样的
client = socket.socket()
client.connect(('127.0.0.1',8080))while True:client.send(b'hello')data = client.recv(1024)print(data.decode('utf-8'))
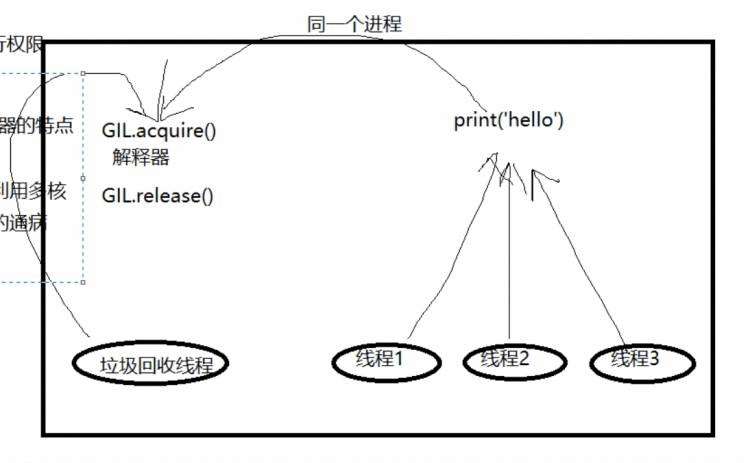
GIL全局解释器锁
ps:python解释器有很多种 最常见的就是CPython解释器,GIL也是在CPython中的。
GIL本质也是一把互斥锁:(是加在解释器上的)
GIL的存在是因为CPython解释器的内存管理不是线程安全的
GIL工作原理:将并发变成串行牺牲效率保证数据的安全 ,用来阻止同一个进程下的多个线程的同时执行
?上面第二行的内存管理(也就是垃圾回收机制) (需要自己查一查背一背以下三个的描述)
1.引用计数:值与变量的绑定关系的个数
2.标记清除 :当内存快要满的时候,会自动停止程序的运行,检测所有的变量和值得绑定关系
给没有绑定关系的值打上标记,最后一次性清除
3.分代回收:(垃圾回收机制也是需要消耗资源的,而正常一个程序的运行,内部会使用到很多变量和值,并且有一部分类似于常量python中没有常量的概念,减少垃圾回收消耗的时间,应该对变量和值的绑定关系做一个分类)
新生代(5s) >>> 青春代(10s) >>> 老年代(20s)
垃圾回收机制扫描一定次数发现关系还在,会将该对关系移至下一代
随着代数的递增 扫描频率是降低的
GIL是python的特点吗?
答:不是,是CPython解释器的特点。
单进程下多个线程无法利用多核优势是所有解释型语言的通病
答:正确,没有很好的解决方法,当前阶段用GIL解决(并非最佳解决方案)
针对不同的设备应该加不同的锁进行处理
验证:有了GIL之后在同一个进程内开多个线程还需不需要再加锁
from threading import Thread
import timen = 100def task():global ntmp = ntime.sleep(1) # 这里睡一秒,是IO操作,会将锁自动释放# 这里所有人都先拿到n等于100,然后都睡一觉,都把锁放了,#再转到下面的代码,都把自己的数据改成99n = tmp -1# 如果上面的把time.sleep(1)注释掉的话,线程1会拿到锁然后执行到最后一行,# 把100改成99,执行结束了,就把锁放了,然后让下一个线程来抢,# 因为之前已经把全局修改为99,线程2会接着执行到代码结束得到98然后放掉锁,# 以此类推,最后输出的结果是:0t_list = []
for i in range(100):t = Thread(target=task)t.start()t_list.append(t)for t in t_list:t.join()print(n)
(同一个进程内多个线程无法实现并行但是可以实现并发)
思考: python的多线程没法利用多核优势 ,是不是就是没有用了?
研究python的多线程是否有用
需要分情况讨论
四个任务 计算密集型的 10s
单核情况下
开线程更省资源
多核情况下
开进程 10s (可以用到多核同时执行)
开线程 40s
计算密集型
from multiprocessing import Process
from threading import Thread
import os,time
def work():res=0for i in range(100000000):res*=iif __name__ == '__main__':l=[]print(os.cpu_count()) # 本机为6核start=time.time()for i in range(6):# p=Process(target=work) #开进程耗时 4.732933044433594p=Thread(target=work) #开线程耗时 22.83087730407715# 本来是6核能一起运行的时间,现在是只用一个核,# 所以 计算密集型里(用线程的时间)≈(用进程的时间*核心数)l.append(p)p.start()for p in l:p.join()stop=time.time()print('run time is %s' %(stop-start))
四个任务 IO密集型的
单核情况下
开线程更节省资源
多核情况下
开线程更节省资源
# IO密集型
from multiprocessing import Process
from threading import Thread
import threading
import os,time
def work():time.sleep(2)if __name__ == '__main__':l=[]print(os.cpu_count()) #本机为6核start=time.time()for i in range(400):p=Process(target=work) #耗时9.001083612442017s多,大部分时间耗费在创建进程上# p=Thread(target=work) #耗时2.051966667175293s多# IO密集型里明显能感觉到,开线程更合理l.append(p)p.start()for p in l:p.join()stop=time.time()print('run time is %s' %(stop-start))
python的多线程到底有没有用
需要看情况而定 并且肯定是有用的
并不能说明多线程和多进程一定是哪种最好,还是要多进程+多线程配合使用
以下都是了解知识点,代码多为伪代码
死锁与递归锁
死锁就是下面Lock可能出现的
递归锁就是下面的RLock
递归锁可以被连续的acquire( 前提是只有第一个抢到的人才能连续acquire )
只有RLock的引用计数为0才能被抢
只有第一个抢到RLock的线程才能将引用计数release为0
from threading import Thread,Lock,current_thread,# ①这里导入 RLock 加上下面的操作是解决死锁的方法之一(递归锁)
import time
"""
Rlock可以被第一个抢到锁的人连续的acquire和release
每acquire一次锁身上的计数加1
每release一次锁身上的计数减1
只要锁的计数不为0 其他人都不能抢"""
mutexA = Lock()
mutexB = Lock() # 这里两把锁是不一样的
# mutexA = mutexB = RLock() # A B现在是同一把锁 ② 这里换成这一句,就能解决死锁class MyThread(Thread):def run(self): # 创建线程自动触发run方法 run方法内调用func1 func2相当于也是自动触发self.func1()self.func2()def func1(self):mutexA.acquire()print('%s抢到了A锁'%self.name) # self.name等价于current_thread().namemutexB.acquire()print('%s抢到了B锁'%self.name)mutexB.release()print('%s释放了B锁'%self.name)mutexA.release()print('%s释放了A锁'%self.name)def func2(self):mutexB.acquire()print('%s抢到了B锁'%self.name)time.sleep(1)mutexA.acquire()print('%s抢到了A锁' % self.name)mutexA.release()print('%s释放了A锁' % self.name)mutexB.release()print('%s释放了B锁' % self.name)for i in range(10):t = MyThread()t.start()
上面的代码块大概第十行,两个锁不一样,这里是说明:
# class Demo(object):
# # pass
# #
# # obj1 = Demo()
# # obj2 = Demo()
# # print(id(obj1),id(obj2)) # 这里id不同
"""
只要类加括号实例化对象
无论传入的参数是否一样生成的对象肯定不一样
单例模式除外(单例是人为限制住了)
"""
自己千万不要轻易处理锁的问题
信号量
信号量可能在不同的领域中 对应不同的知识点
互斥锁:单个卫生间(一个坑位)
信号量:多个卫生间(多个坑位)
from threading import Semaphore,Thread
import time
import randomsm = Semaphore(5) # 造了一个含有五个的坑位的公共厕所def task(name):sm.acquire()print('%s占了一个坑位'%name)time.sleep(random.randint(1,3))sm.release()for i in range(40):t = Thread(target=task,args=(i,)) # 这里args=(i,)就是给name传值,# 这里给name传的值就是it.start()
task里面的sleep 如果里面的值是“1” 那就是五个人先抢到坑位,然后五个人同时释放,再让接下来5个人抢
如果是上面的randint(1,3)就不是五个人同时出来了
event事件
之前学过的join()方法是主进程等待子进程结束
是否让一个子进程等待另一个子进程结束呢?
下面是一个线程等另一个线程的模型
from threading import Event,Thread
import time# 先生成一个event对象
e = Event()def light(): # 红绿灯print('红灯正亮着')time.sleep(3)e.set() # 发信号print('绿灯亮了')def car(name): # 汽车print('%s正在等红灯'%name)e.wait() # 等待信号print('%s加油门飙车了'%name)t = Thread(target=light)
t.start()for i in range(10):t = Thread(target=car,args=('伞兵%s'%i,))t.start()
这里就是子线程car等待子线程light
线程q
import queue
"""
同一个进程下的多个线程本来就是数据共享 为什么还要用队列?
因为队列是管道+锁 使用队列你就不需要自己手动操作锁的问题
因为锁操作的不好极容易产生死锁现象
"""q = queue.Queue()
q.put('hahha')
print(q.get()) # 结果:hahha (这就是普通的 Queue )--------------------------------------------------
q = queue.LifoQueue() # last in first out (堆栈)
q.put(1)
q.put(2)
q.put(3)
print(q.get()) # 结果:3 (因为这是最后一个加的)
--------------------------------------------------q = queue.PriorityQueue() # 优先级 Queue (支持手动设计优先级)
# 数字越小 优先级越高
q.put((10,'haha')) # 注意得传元组,元组里面两个值,第一个值是优先级,第二个是参数
q.put((100,'hehehe'))
q.put((0,'xxxx'))
q.put((-10,'yyyy'))
print(q.get()) # 结果:yyyy (因为这个优先级最高)







 京公网安备 11010802041100号
京公网安备 11010802041100号