一、数据湖的角色和定位
随着移动互联网,物联网技术的发展,数据的应用逐渐从 BI 报表可视化往机器学习、预测分析等方向发展,即 BI 到 AI 的转变。
数据的使用者也从传统的业务分析人员转为数据科学家,算法工程师。此外对数据的实时性要求越来越高,也出现了越来越多的非结构化的数据。
目前的数据仓库技术出现了一定的局限性,比如单一不变的 schema 和模型已经无法满足各类不同场景和领域的数据分析的要求,并且数据科学家更愿意自己去处理原始的数据,而不是直接使用被处理过的数据。
比如对于数据缺失这种情况,数据科学家会尝试各种不同的算法去弥补缺失数据,针对不同的业务场景也会有不同的处理方式。
目前数据湖相关的技术是业界针对这些问题的一种解决方案。
下表展示了数据仓库和数据湖在各个维度上的特性:
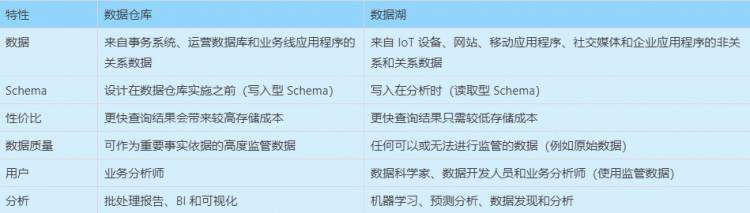
相比于数据仓库,数据湖会保留最原始的数据,并且是读取时确定 Schema,这样可以在业务发生变化时能灵活调整。
最原始的数据湖技术其实就是对象存储,比如 Amazon S3,Aliyun OSS,可以存储任意形式的原始数据,但是如果不对这些存储的原始文件加以管理,就会使数据湖退化成数据沼泽(dataswamp)。
所以必须有相关的技术发展来解决这些问题。
我们都知道一个大数据处理系统分为:
分布式文件系统:HDFS,S3
基于一定的文件格式将文件存储在分布式文件系统:Parquet,ORC, ARVO
用来组织文件的元数据系统:Metastore
处理文件的计算引擎,包括流处理和批处理:SPARK,FLINK
简单的说,数据湖技术是计算引擎和底层存储格式之间的一种数据组织格式,用来定义数据、元数据的组织方式。
目前并没有针对数据湖的比较成熟的解决方案,几个大厂在开发相关技术来解决内部遇到的一些痛点后,开源了几个项目,比较著名的有Databrics 的 Dalta Lake,Uber 开源的 Hudi,Netflix 开源的 Iceberg。
二、Delta Lake
传统的 lambda 架构需要同时维护批处理和流处理两套系统,资源消耗大,维护复杂。
基于 Hive 的数仓或者传统的文件存储格式(比如 parquet / ORC),都存在一些难以解决的问题:
小文件问题;
并发读写问题;
有限的更新支持;
海量元数据(例如分区)导致 metastore 不堪重负
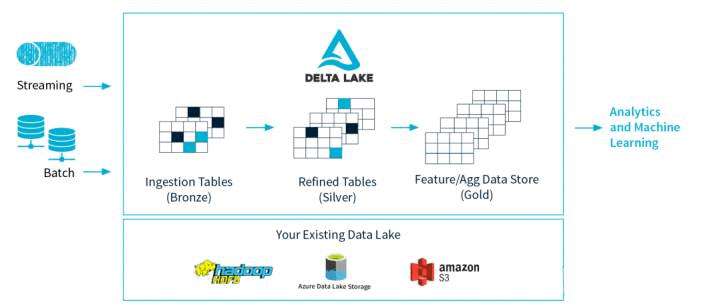
如上图,Delta Lake 是 Spark 计算框架和存储系统之间带有 Schema 信息的存储中间层。
它有一些重要的特性:
设计了基于 HDFS 存储的元数据系统,解决 metastore 不堪重负的问题;
支持更多种类的更新模式,比如 Merge / Update / Delete 等操作,配合流式写入或者读取的支持,让实时数据湖变得水到渠成;
流批操作可以共享同一张表;
版本概念,可以随时回溯,避免一次误操作或者代码逻辑而无法恢复的灾难性后果。
Delta Lake 是基于 Parquet 的存储层,所有的数据都是使用 Parquet 来存储,能够利用 parquet 原生高效的压缩和编码方案。
Delta Lake 在多并发写入之间提供 ACID 事务保证。每次写入都是一个事务,并且在事务日志中记录了写入的序列顺序。
事务日志跟踪文件级别的写入并使用乐观并发控制,这非常适合数据湖,因为多次写入/修改相同的文件很少发生。在存在冲突的情况下,Delta Lake 会抛出并发修改异常以便用户能够处理它们并重试其作业。
Delta Lake 其实只是一个 Lib 库,不是一个 service,不需要单独部署,而是直接依附于计算引擎的,但目前只支持 spark 引擎,使用过程中和 parquet 唯一的区别是把 format parquet 换成 delta 即可,可谓是部署和使用成本极低。
三、Apache Hudi
Hudi 是什么 一般来说,我们会将大量数据存储到HDFS/S3,新数据增量写入,而旧数据鲜有改动,特别是在经过数据清洗,放入数据仓库的场景。
且在数据仓库如 hive中,对于update的支持非常有限,计算昂贵。另一方面,若是有仅对某段时间内新增数据进行分析的场景,则hive、presto、hbase等也未提供原生方式,而是需要根据时间戳进行过滤分析。
Apache Hudi 代表 Hadoop Upserts anD Incrementals,能够使HDFS数据集在分钟级的时延内支持变更,也支持下游系统对这个数据集的增量处理。
Hudi数据集通过自定义的 nputFormat 兼容当前 Hadoop 生态系统,包括 Apache Hive,Apache Parquet,Presto 和 Apache Spark,使得终端用户可以无缝的对接。
如下图,基于 Hudi 简化的服务架构,分钟级延迟。
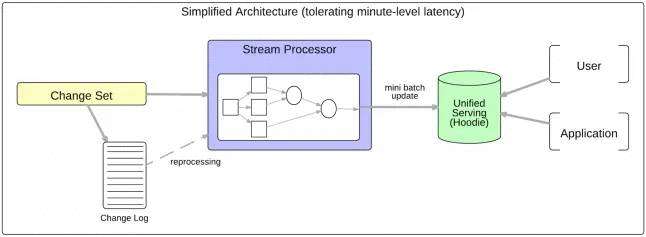
Hudi 存储的架构
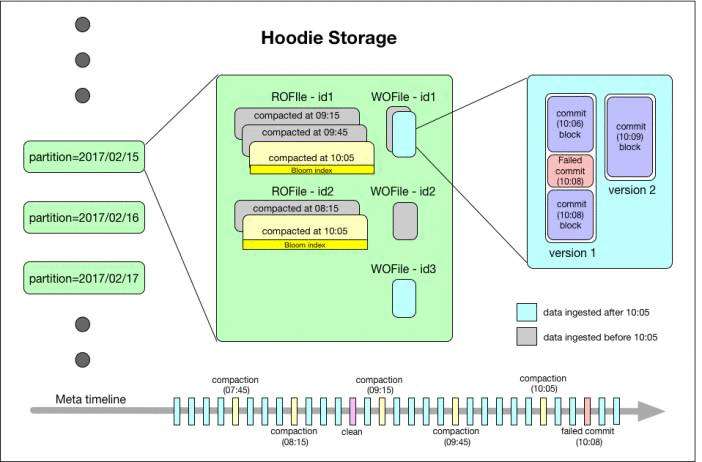
如上图,最下面有一个时间轴,这是 Hudi 的核心。
Hudi 会维护一个时间轴,在每次执行操作时(如写入、删除、合并等),均会带有一个时间戳。
通过时间轴,可以实现在仅查询某个时间点之后成功提交的数据,或是仅查询某个时间点之前的数据。
这样可以避免扫描更大的时间范围,并非常高效地只消费更改过的文件(例如在某个时间点提交了更改操作后,仅 query 某个时间点之前的数据,则仍可以 query 修改前的数据)。
如上图的左边,Hudi 将数据集组织到与 Hive 表非常相似的基本路径下的目录结构中。
数据集分为多个分区,每个分区均由相对于基本路径的分区路径唯一标识。
如上图的中间部分,Hudi 以两种不同的存储格式存储所有摄取的数据。
读优化的列存格式(ROFormat):仅使用列式文件(parquet)存储数据。在写入/更新数据时,直接同步合并原文件,生成新版本的基文件(需要重写整个列数据文件,即使只有一个字节的新数据被提交)。此存储类型下,写入数据非常昂贵,而读取的成本没有增加,所以适合频繁读的工作负载,因为数据集的最新版本在列式文件中始终可用,以进行高效的查询。
写优化的行存格式(WOFormat):使用列式(parquet)与行式(avro)文件组合,进行数据存储。在更新记录时,更新到增量文件中(avro),然后进行异步(或同步)的compaction,创建列式文件(parquet)的新版本。此存储类型适合频繁写的工作负载,因为新记录是以appending 的模式写入增量文件中。但是在读取数据集时,需要将增量文件与旧文件进行合并,生成列式文件。
四、Apache Iceberg
Iceberg 作为新兴的数据湖框架之一,开创性的抽象出“表格式”table format)这一中间层,既独立于上层的计算引擎(如Spark和Flink)和查询引擎(如Hive和Presto),也和下层的文件格式(如Parquet,ORC和Avro)相互解耦。
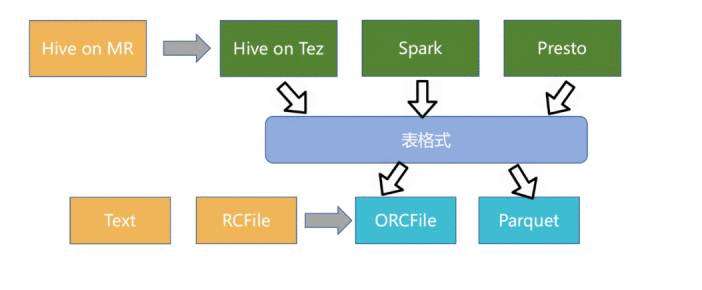
此外 Iceberg 还提供了许多额外的能力:
ACID事务;
时间旅行(time travel),以访问之前版本的数据;
完备的自定义类型、分区方式和操作的抽象;
列和分区方式可以进化,而且进化对用户无感,即无需重新组织或变更数据文件;
隐式分区,使SQL不用针对分区方式特殊优化;
面向云存储的优化等;
Iceberg的架构和实现并未绑定于某一特定引擎,它实现了通用的数据组织格式,利用此格式可以方便地与不同引擎(如Flink、Hive、Spark)对接。
所以 Iceberg 的架构更加的优雅,对于数据格式、类型系统有完备的定义和可进化的设计。
但是 Iceberg 缺少行级更新、删除能力,这两大能力是现有数据组织最大的卖点,社区仍然在优化中。
五、总结
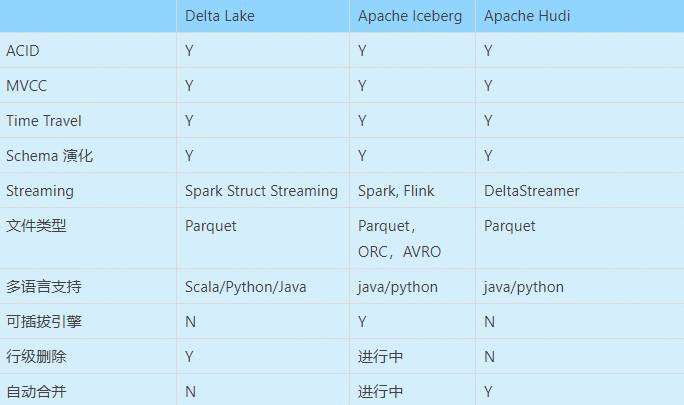
下表从各个维度,总结了三大数据湖框架支持的特性。
如果用一个比喻来说明delta、iceberg、hudi、三者差异的话,可以把三个项目比做建房子。
Delta的房子底座相对结实,功能楼层也建得相对比较高,但这个房子其实可以说是databricks的,本质上是为了更好地壮大Spark生态,在delta上其他的计算引擎难以替换Spark的位置,尤其是写入路径层面。
Iceberg的建筑基础非常扎实,扩展到新的计算引擎或者文件系统都非常的方便,但是现在功能楼层相对低一点,目前最缺的功能就是upsert和compaction两个,Iceberg社区正在以最高优先级推动这两个功能的实现。
Hudi的情况要相对不一样,它的建筑基础设计不如iceberg结实,举个例子,如果要接入Flink作为Sink的话,需要把整个房子从底向上翻一遍,把接口抽象出来,同时还要考虑不影响其他功能,当然Hudi的功能楼层还是比较完善的,提供的upsert和compaction功能直接命中广大群众的痛点。
--end--扫描下方二维码添加好友,备注【交流】
可私聊交流,也可进资源丰富学习群









 京公网安备 11010802041100号
京公网安备 11010802041100号