作者:龙叔君_541 | 来源:互联网 | 2023-06-05 19:34
【版权声明】本资料来源网络,知识分享,仅供个人学习,请勿商用。
【侵删致歉】如有侵权请联系小编,将在收到信息后第一时间删除!
完整资料领取见文末,部分资料内容:
目录
1. 数据中台平台建设方案
1.1. 总体建设方案
1.1.1. 大数据平台-TDH
1.1.2. 云操作系统-TOS
1.1.3. 大数据平台产品优势
1.1.4. 大数据平台性能优化
1.2. 大数据集成平台
1.2.1. 数据采集层建设
1.2.2. 数据存储层建设
1.2.3. 数据交换层建设
1.2.4. 数据管理层建设
1.2.5. 资源管理层建设
1.3. 大数据计算平台
1.3.1. 数据计算层建设
1.4. 大数据开发平台
1.4.1. 大数据平台可视化工具
1.4.2. 大数据平台集成能力
1.5. 大数据运维平台
1.5.1. 大数据平台运维
1.5.2. 大数据平台安全性
1.5.3. 大数据平台高可用性
1.5.4. 大数据平台开放性
1.5.5. 大数据平台兼容性
1.1. 大数据集成平台
1.1.1. 数据采集层建设
大数据平台需要采集各类内外部数据,形式多样,需支持不同频度、不同形态的数据采集。采集方式包含流方式、批量导入方式、外部数据文件导入、异构数据库导入、主动数据抽取、增量追加方式、网上爬虫方式等,数据形态包括结构化数据、半结构化数据、非结构化数据。
数据采集层负责实现内外部结构化数据、非结构化数据和流数据的自动化采集,遵从统一数据交换架构,完成数据采集相关工具、组件的安装、部署和集成,利用数据调度和采集工具将数据源数据导入大数据基础平台中。
本建设方案满足甲方对于数据采集层建设的基本要求:
利用了FTP/SFTP、Sqoop、Kafka、Flume等开源组件和技术;实现了离线采集和加载、实时/准实时数据同步等功能;遵循了开放性和先进性原则;并且提供了更高效的数据导入工具SQL Bulkload,与关系型数据库准实时同步的工具OGG和ODC,使得数据采集工具更加丰富,数据导入效率更高,时效性更强。可以给甲方后续建设提供更丰富、更多样性的选择。
1.1.1.1. 数据接入多样化
1.1.1.1.1. 结构化数据加载
在Oracle、DB2、Mysql等传统关系型数据库以及MongoDB等NoSQL数据库上的产生结构化数据需要迁移到Hadoop平台上Inceptor表、Hyperbase表或者Search表中进行数据分析或者检索,TDH上支持各类结构化数据的加载,支持灵活通用的数据格式描述,包括数据包含的字段、各字段的分隔符、字段类型等。支持传输的带分隔符的元组序列,每个元组的字段结构相同,由指定的分隔符分隔。支持的字段类型包括:整数(最长8字节)、浮点数、字符串、日期、时间等。在Inceptor中定义相关的表结构,Inceptor中支持整形、浮点数、字符串以及日期和时间等常用的简单字段类型以及Map、Array、Struct等复杂的数据类型。
通过Sqoop生成分布式任务对数据进行高效抽出同步,或者通过TDA组件对关系型数据库中的表进行准实时同步插入更新删除等数据操作;业务平台实时产生的结构化日志或者消息通过Flume分布式日志实时采集工具加载到TDH平台上HDFS、Search、Hyperbase或者Kafka数据队列中;加载到HDFS上的数据,通过Inceptor SQL进行数据处理或者在Discover中进行数据挖掘和机器学习。加载到Hyperbase中的数据可以通过Inceptor进行后模糊或精确匹配的高并发检索查询。加载到Search中的数据可以通过Inceptor进行前模糊、后模糊、范围检索、关键字检索、全文检索等。在千兆网络下,Search的数据入库速度为单节点20000条每秒。
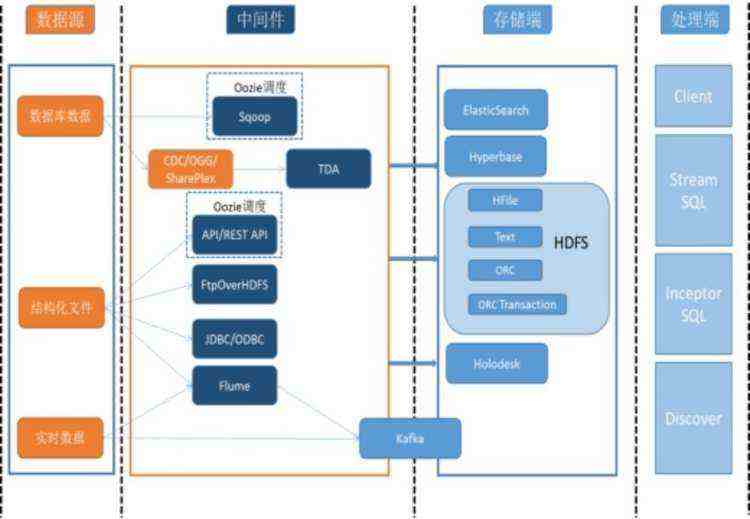
业务系统定义数据格式,数据源(数据库或者结构结构化文件),数据存储端(HDFS、Search、Holodesk、Hyperbase等),数据调度方式,数据同步方式等,TDH上根据定义的数据加载方式为该任务自动配置数据处理的数据源、中间件(Sqoop、TDA、API/REST API、FTPOverHDFS、JDBC/ODBC、Flume或Kafka等)、存储以及处理方式等,启动相应的Oozie工作流任务或者中间件的调度任务,并对数据的加载、传输以及处理入库全流程进行监控和记录。
TDH上支持各类结构化数据的加载,支持灵活通用的数据格式描述,包括数据包含的字段、各字段的分隔符、字段类型等。支持传输的带分隔符的元组序列,每个元组的字段结构相同,由指定的分隔符分隔。支持的字段类型包括:整数(最长8字节)、浮点数、字符串、日期、时间等。在Inceptor中定义相关的表结构,Inceptor中支持整形、浮点数、字符串以及日期和时间等常用的简单字段类型以及Map、Array、Struct等复杂的数据类型。
在负载均衡方面,当一类数据加载量较大时支持由多个加载客户端并行加载。Sqoop,Flume,Kafka等工具均是分布式架构数据采集工具,支持多任务并行执行。Sqoop通过生成并提交MapReduce程序来切分task实现并行执行抽取数据任务;Flume通过分布式架构可以通过定义多个Agent或者多组Source-Channel-Sink组件来实现多个客户端并行加载数据;Kafka通过定义并行收集数据的Kafka Producer或者多个Kafka Producer来对数据进行并行加载。
支持将数据加载到数据库、Hyperbase、总线消息队列、流处理系统以及HDFS上。
Flume支持多个Agent数据传输节点之间以多对一的方式进行数据汇聚,如采集不同服务节点上的同一类日志数据汇聚到同一份文件中,支持一对多的方式数据分发,如将同一份数据通过KafkaSink传输到kafka上导入到Stream中做流式计算,通过HdfsSink传输到HDFS上做数据存储,还可以通过ElasticsearchSink到Search做数据搜索。
分布式数据采集框架Flume集成多种数据源以及数据传输的插件,并通过程序接口可以快速实现相关采集传输数据以及数据计数、数据筛选、数据预处理以及数据流监控等功能。Flume里面的支持自定义插件interceptor对数据进行过滤筛选等,并且在Flume里面,还可以通过KafkaSink将数据流接入Kafka导入到Stream中通过StreamSQL进行数据处理,在这里Flume作为Kafka的一种数据源。
TDH上数据传输工具支持加载数据缓存功能。当目标接收端出现问题时,网络中断或出现阻塞时,支持将加载数据缓存在本地磁盘中,当目标端恢复后继续将数据加载到目标端中。Flume或者Kafka均支持将消息队列缓存在文件系统上,Flume支持failover机制,Kafka通过对数据的多份备份,均对加载的数据有相应的可靠性机制保证数据的安全。
分布式文件系统HDFS与分布式消息队列Kafka均支持断点续传功能的实现,HDFS支持文件中数据的append,并且支持指定offset的数据读取,可以通过对于数据offset的记录实现数据上传下载中断点续传的功能。Kafka中的数据缓存在磁盘上,在消费队列中记录有消息被消费的偏移量offset,因此可以缓存传输中的断点位置来保证数据进行断点续传。
TDH上通过Oozie工作流引擎定制定期作业,通过Sqoop定时将数据库中数据导入到TDH上;离线文件可以通过分布式数据采集组件Flume监控相应的文件目录,定时将数据文件传输到HDFS上或者相应的存储系统中。
在万兆网络的环境下,单台客户端支持的数据加载速度在300MB/s及以上(现场测试结果),可以随集群规模线性扩展直至到达网络传输最大带宽。加载集群对于文本数据的加载总带宽在100Gb/s及以上。单台加载机最大的数据缓存量可以达到TB级。最大可以达到机器存储能力的上限。缓存能力与机器存储能力成线性增长。
1.1.1.1.2. 半结构化数据加载
TDH支持加载各类半结构化数据,支持的类型包括邮件、网页、XML文档,结构化日志中的某些字段等。在TDH上采用Logstash组件对半结构化数据进行加载以及处理,支持自定义输入数据的结构以及输出数据的结构;支持通过Flume自定义数据接口以及数据的简单处理,并将处理后的数据加载到指定的存储端;加载到HDFS上的半结构化数据可以通过Inceptort SQL对其进行结构化加工和处理,Inceptor支持对Json.、XML/HTML、CSV等半结构化数据文件进行直接处理或者查询分析。
在负载均衡方面,当一类数据加载量较大时支持由多个加载客户端并行加载。Sqoop,Flume,Kafka等工具均是分布式架构数据采集工具,支持多任务并行执行。Sqoop通过生成并提交MapReduce程序来切分task实现并行执行抽取数据任务;Flume通过分布式架构可以通过定义多个Agent或者多组Source-Channel-Sink组件来实现多个客户端并行加载数据;Kafka通过定义并行收集数据的Kafka Producer或者多个Kafka Producer来对数据进行并行加载。同时支持多台加载程序以多对一、一对多的方式连接,完成数据的分发或汇聚。
1.1.1.1.3. 非结构化数据加载
业务系统产生的各种类型的文档、图片、非结构化文本需要在TDH上进行存储、检索等处理方式,在TDH上通过定制Flume组件、API接口可以将非结构化数据(文档、图片、音视频等多媒体文件)传输加载到HDFS上或者Hyperbase表中进行处理或者高效检索,TDH上支持ObjectStore对象存储,针对大量小文件(一般小于等于10M)在HDFS上存储的方式进行优化,将数据文件封装为ObjectStore对象进行存储,支持高效率读写ObjectStore对象。因此TDH上支持针对0 KB到数TB的文件的加载、存储和处理或者检索的完整解决方案。

业务系统定义数据格式,数据源(非结构化的文档、图片、音视频多媒体文件等),数据存储端(HDFS、Search、Hyperbase等),数据调度方式,数据同步方式等,TDH上根据定义的数据加载方式为该任务自动配置数据处理的数据源、中间件(API/REST API、FTPOverHDFS、JDBC/ODBC、Flume等)、存储以及处理方式等,启动相应的Oozie工作流任务或者中间件的调度任务,并对数据的加载、传输以及处理入库全流程进行监控和记录。
TDH上支持将各类非结构化文本数据、图片、音频、视频的加载,以文件的形式存储。在TDH中支持将非结构化数据封装成Object Store对象进行存储。在负载均衡方面,当一类数据加载量较大时支持由多个加载客户端并行加载。Sqoop,Flume,Kafka等工具均是分布式架构数据采集工具,支持多任务并行执行。Sqoop通过生成并提交MapReduce程序来切分task实现并行执行抽取数据任务;Flume通过分布式架构可以通过定义多个Agent或者多组Source-Channel-Sink组件来实现多个客户端并行加载数据;Kafka通过定义并行收集数据的Kafka Producer或者多个Kafka Producer来对数据进行并行加载。数据存入HDFS文件系统进行存储、分析和挖掘,或者存入到Hyperbase数据库进行快速检索。TDH上数据加载和传输支持断点续传功能。当目标接收端出现问题恢复时能够在上次传输的断点继续传输。Kafka中的数据缓存在磁盘上,在队列中记录有消息被消费的偏移量offset,因此可以缓存传输中的断点位置来保证数据进行断点续传。
在万兆网络的环境下,单台客户端支持的数据加载速度在300MB/s及以上(现场测试结果),可以随集群规模线性扩展直至到达网络传输最大带宽。通过对象存储与分布式文件系统存储能力,支持1KB到PB级数据存储。
1.1.1.1.4. 流式数据加载
流数据采集可通过高吞吐、高可靠的分布式消息队列缓存Kafka及flume来实现。Kafka可以用作数据缓冲队列,作为流处理的数据源。Transwarp Stream作为Kafka的消费者,使用StreamSQL对数据进行处理。在万兆网络,使用双副本的条件下,对于高效模式单台数据总线服务器支持的业务数据加载速度在300MB/s及以上,吞吐能力可以随集群规模线性扩展。对于可靠模式支持的业务数据单节点加载速度25M/s及以上,可以线性扩展至网络传输的极限。高效模式下数据丢失率在万分之一以内。可靠模式下加载数据要求与输入数据一致。单集群支持的数据总线服务器总数随集群规模扩展而增加,支持100节点以上的集群规模。数据从发布到订阅时延在1秒以内。

Kafka数据总线支持数据订阅和发布功能,可以通过定义消息总线发布端、订阅端、消息队列、数据格式等相关配置来发布数据总线并自动维护总线消息队列,自动对总线消息进行全流程监控。数据由数据客户端加载数据库中数据、由WebService业务系统的访问请求或者外部检索工具发出的请求消息,Kafka中支持缓存和传输结构化半结构以及非结构的文本各类数据以及消息。数据源包括,数据加载客户端,流处理引擎,数据表存储,数据抽取工具或者其他自定义的Kafka Producer。订阅客户端包括:流处理引擎,数据表存储,K-V存储或者自定义的Kafka Consumer。Kafka中可以在Topic上进行业务标记或者在传输的消息中对业务类型等信息进行标记。
Kafka支持跨集群同步,通过MirrorMaker实现两个数据总线集群间的数据镜像。Kafka中支持建立多份Topic数据副本可靠数据传输机制。在可靠数据传输模式下可以保证从生产者到消费者之间数据不会丢失。在高效传输模式下允许数据有一定量的丢失,丢失率在万分之一以下。Kafka将数据缓存在本地磁盘中,通过文件数据队列的相应机制支持数据断点续传。Kafka支持在线服务平滑扩展,并且吞吐能力与集群规模线性正相关,Kafka总线消息队列集群支持数百节点的规模,理论上集群规模并无上限。Kafka支持通过Guardian对用户进行权限管理,用户经过相应的授权后才可以访问相关数据主题。
篇幅有限,无法完全展示,如需获取完整内容,请转发后私信资料名称。
文章引用的资料均通过互联网等公开渠道合法获取,仅作为行业交流和学习使用,并无任何商业目的。其版权归原资料作者或出版社所有,本文作者不对所涉及的版权问题承担任何法律责任。若版权方、出版社认为本文章侵权,请立即通知作者删除。








 京公网安备 11010802041100号
京公网安备 11010802041100号