没想到昨天 一个没有写完的 面试备战笔记 上了牛客热搜第一
成就值一下涨了一千多 刷了三年题 也才勉强凑够一千 成就值
那我就 趁热打铁 再准备一篇
昨天那个可能 太难了
这回这个就正经多了。
网易互联网 暑期实习一面面经 源地址
3月19投简历,3月22约面,3月24下午14:15面试
这个我没学过 应该也不会问我 先pass 加入代办事项 谁会也可以直接评论回答下
就是红黑树 弱平衡 查找快 但是 其他平衡二叉树 插入的效率低 红黑树性能最好
红黑树需要的连续内存空间少 红黑树适合内存
B+树节点都挤在一起 需要大量连续内存空间 适合硬盘的操作
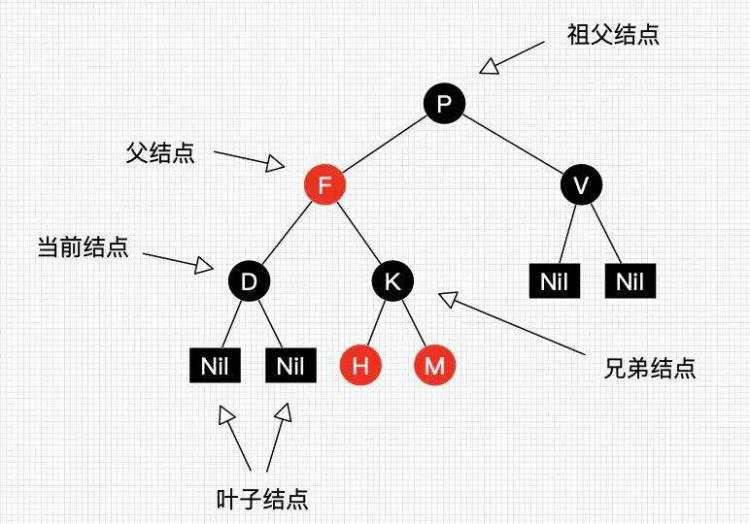
红黑树定义和性质
红黑树是一种含有红黑结点并能自平衡的二叉查找树。它必须满足下面性质:
性质1:每个节点要么是黑色,要么是红色。
性质2:根节点是黑色。
性质3:每个叶子节点(NIL)是黑色。
性质4:每个红色结点的两个子结点一定都是黑色。
性质5:任意一结点到每个叶子结点的路径都包含数量相同的黑结点。
从性质5又可以推出:
性质5.1:如果一个结点存在黑子结点,那么该结点肯定有两个子结点
红黑树并不是一个完美平衡二叉查找树,从图1可以看到,根结点P的左子树显然比右子树高,但左子树和右子树的黑结点的层数是相等的,也即任意一个结点到到每个叶子结点的路径都包含数量相同的黑结点(性质5)。所以我们叫红黑树这种平衡为黑色完美平衡。
红黑树能自平衡,它靠的是什么?三种操作:左旋、右旋和变色。
作者:安卓大叔 链接:https://www.jianshu.com/p/e136ec79235c 来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
首先红黑树在主流的平衡树里面属于平衡度比较低的(树高最坏可以到2logn),
相对的平衡操作成本也更低,
工程上一般不会碰到最坏情况,
所以平衡操作成本低的红黑树相对性能更好。
其次红黑树需要的额外存储成本是最低的(1bit表示红/黑就行了,AVL都至少需要2bit),
较小的空间开销也可以带来更高的缓存效率,从而提高性能。
最后,工程上更倾向于使用有成功案例的方案,
红黑树早期的流行使得大家在没有很特殊的需求时都会优先考虑红黑树。
很可能一些场景下别的数据结构性能比红黑树还好,
但是“红黑树也不是不能用,
代码还好抄,就先将就用着吧”。
作者:鱼你太美 链接:https://www.zhihu.com/question/27542473/answer/840995214
来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
B/B+树多用于外存上时,B/B+也被成为一个磁盘友好的数据结构。
HashMap本来是数组+链表的形式,链表由于其查找慢的特点,所以需要被查找效率更高的树结构来替换。如果用B/B+树的话,在数据量不是很多的情况下,数据都会“挤在”一个结点里面,这个时候遍历效率就退化成了链表。
TreeMap是排序的而HashMap不是
先看HashMap的定义:
public class HashMap
implements Map
再看TreeMap的定义:
public class TreeMap
extends AbstractMap
implements NavigableMap
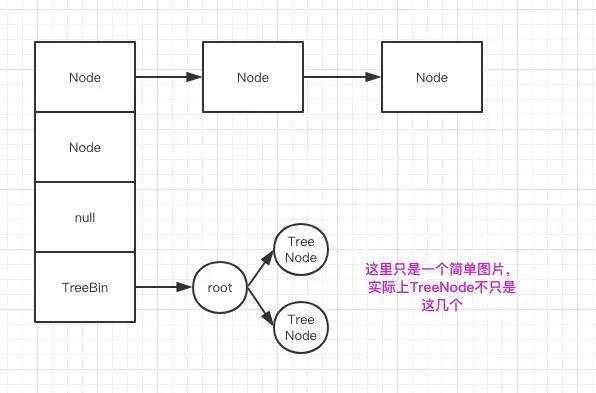
HashMap的底层结构是Node的数组:
transient Node
当HashMap中存储的数据过多的时候,table数组就会被装满,这时候就需要扩容,HashMap的扩容是以2的倍数来进行的。而loadFactor就指定了什么时候需要进行扩容操作。默认的loadFactor是0.75。
public HashMap(int initialCapacity, float loadFactor)
TreeMap的底层是一个Entry:实现是一个红黑树,方便用来遍历和搜索。
private transient Entry
TreeMap的构造函数可以传入一个Comparator,实现自定义的比较方法。
public TreeMap(Comparator comparator) {
this.comparator = comparator;
}
TreeMap输出的结果是排好序的,而HashMap的输出结果是不定的。
HashMap可以允许一个null key和多个null value。
HashMap会报出: NullPointerException。
而TreeMap不允许null key,但是可以允许多个null value。
HashMap的底层是Array,所以HashMap在添加,查找,删除等方法上面速度会非常快。而TreeMap的底层是一个Tree结构,所以速度会比较慢。
另外HashMap因为要保存一个Array,所以会造成空间的浪费,而TreeMap只保存要保持的节点,所以占用的空间比较小。
HashMap如果出现hash冲突的话,效率会变差,不过在java 8进行TreeNode转换之后,效率有很大的提升。
TreeMap在添加和删除节点的时候会进行重排序,会对性能有所影响。
两者都不允许duplicate key,两者都不是线程安全的。
深入理解HashMap和TreeMap的区别
https://www.cnblogs.com/flydean/p/hashmap-vs-treemap.html#%E6%8E%92%E5%BA%8F%E5%8C%BA%E5%88%AB
TreeMap基于红黑树(Red-Black tree)实现。
映射根据其键的自然顺序进行排序,
或者根据创建映射时提供的 Comparator 进行排序,
具体取决于使用的构造方法。
TreeMap的基本操作containsKey、get、put、remove方法,
它的时间复杂度是log(N)。
TreeMap包含几个重要的成员变量:
root、size、comparator。
其中root是红黑树的根节点。
它是Entry类型,Entry是红黑树的节点,它包含了红黑树的6个基本组成:key、value、left、right、parent和color。
Entry节点根据根据Key排序,包含的内容是value。
Entry中key比较大小是根据比较器comparator来进行判断的。
size是红黑树的节点个数。
《牛客Java面试宝典》 第1章 第6节 Java基础-6
https://www.nowcoder.com/tutorial/10070/489ddf1bff5e419ba8f8f99c6ff6e393
HashMap是非线程安全的,这意味着不应该在多线程中对这些Map进行修改操作,否则会产生数据不一致的问题,甚至还会因为并发插入元素而导致链表成环,这样在查找时就会发生死循环,影响到整个应用程序。
Collections工具类可以将一个Map转换成线程安全的实现,其实也就是通过一个包装类,然后把所有功能都委托给传入的Map,而包装类是基于synchronized关键字来保证线程安全的(Hashtable也是基于synchronized关键字),底层使用的是互斥锁,性能与吞吐量比较低。
ConcurrentHashMap的实现细节远没有这么简单,因此性能也要高上许多。它没有使用一个全局锁来锁住自己,而是采用了减少锁粒度的方法,尽量减少因为竞争锁而导致的阻塞与冲突,而且ConcurrentHashMap的检索操作是不需要锁的。
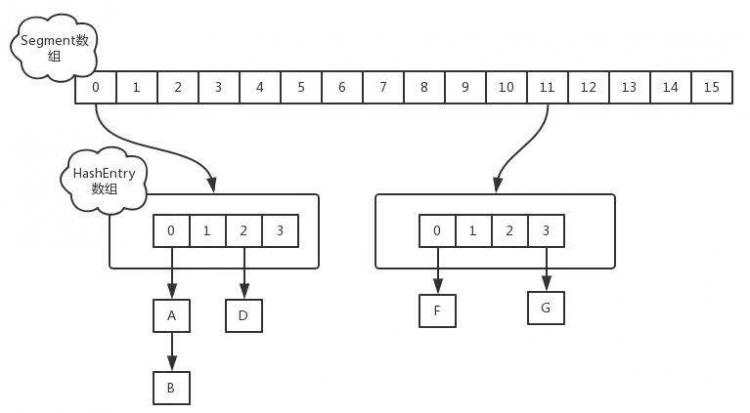
get操作:
Segment的get操作实现非常简单和高效,先经过一次再散列,然后使用这个散列值通过散列运算定位到 Segment,再通过散列算法定位到元素。get操作的高效之处在于整个get过程都不需要加锁,除非读到空的值才会加锁重读。原因就是将使用的共享变量定义成 volatile 类型。
put操作:
当执行put操作时,会经历两个步骤:
不是
volatile关键字为域变量的访问提供了一种免锁机制,
使用volatile修饰域相当于告诉虚拟机该域可能会被其他线程更新,
因此每次使用该域就要重新计算,
而不是使用寄存器中的值。
需要注意的是,volatile不会提供任何原子操作,它也不能用来修饰final类型的变量。
在ArrayList中,底层数组存/取元素效率非常的高(get/set),时间复杂度是O(1),而查找,插入和删除元素效率似乎不太高,时间复杂度为O(n)。
当我们ArrayLIst里有大量数据时,这时候去频繁插入/删除元素会触发底层数组频繁拷贝,效率不高,还会造成内存空间的浪费,
也就是 扩容了100W 就可以 复杂度为1 不扩容 就是一点一点 扩容 复杂度 nlogn
public class SynchronizedDemo {
public void method() {
synchronized (this) {
System.out.println("Method 1 start");
}
}
}
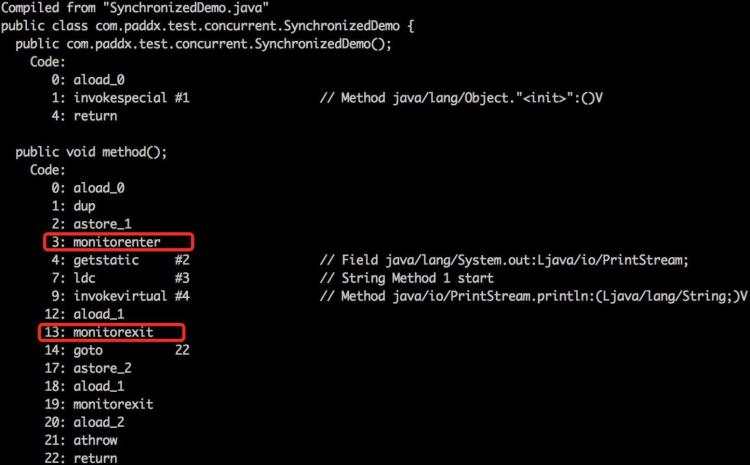
monitorexit指令出现了两次,
第1次为同步正常退出释放锁,
第2次为发生异步退出释放锁。
public class SynchronizedMethod {
public synchronized void method() {
System.out.println("Hello World!");
}
}
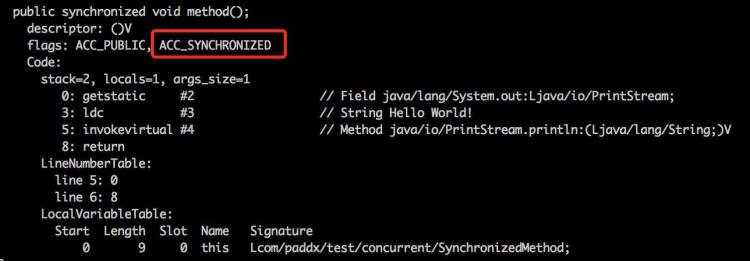
从反编译的结果来看,方法的同步并没有通过 monitorenter 和 monitorexit 指令来完成,
不过相对于普通方法,其常量池中多了 ACC_SYNCHRONIZED 标示符。
JVM就是根据该标示符来实现方法的同步的:
当方法调用时,
两种同步方式本质上没有区别,
只是方法的同步是一种隐式的方式来实现,
无需通过字节码来完成。
两个指令的执行是JVM通过调用操作系统的互斥原语mutex来实现,
被阻塞的线程会被挂起、等待重新调度,
会导致“用户态和内核态”两个态之间来回切换,对性能有较大影响。
一个高度为 3 的 B+ 树大概可以存放 1170 × 1170 × 16 = 21902400 行数据,已经是千万级别的数据量了。
leaf page 和 index page都变满 树的高度会增加
B+树插入新元素时,可能会遇到3种情况

原文链接:https://blog.csdn.net/wei_wenbo/article/details/50819651
简单版本回答是:
因为 B 树不管叶子节点还是非叶子节点,都会保存数据,这样导致在非叶子节点中能保存的指针数量变少(有些资料也称为扇出),指针少的情况下要保存大量数据,只能增加树的高度,导致 IO 操作变多,查询性能变低。
https://zhuanlan.zhihu.com/p/86137284
牛客Java集训营 秒杀项目
https://www.nowcoder.com/courses/cover/live/537

更新缓存与删除缓存哪种方式更合适?
应该先操作数据库还是先操作缓存?
下面,我们来分析一下,应该采用更新缓存还是删除缓存的方式。
从上面的比较来看,一般情况下,删除缓存是更优的方案。
先操作数据库还是缓存:
下面,我们再来分析一下,应该先操作数据库还是先操作缓存。
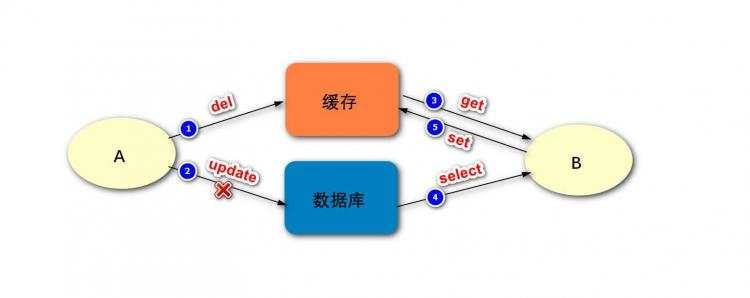
最终,缓存和数据库的数据是一致的,但仍然是旧的数据。而我们的期望是二者数据一致,并且是新的数据。
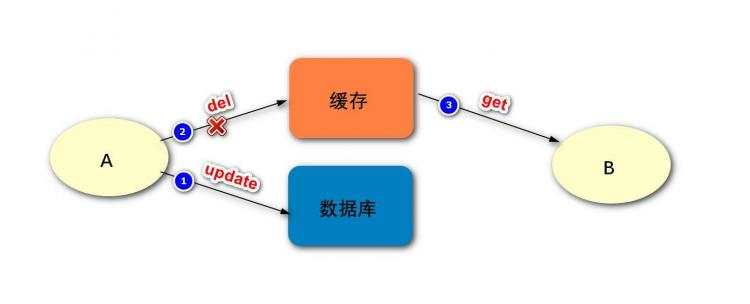
如上图,是先更新数据库再删除缓存,在出现失败时可能出现的问题:
最终,缓存和数据库的数据是不一致的。
经过上面的比较,我们发现在出现失败的时候,
是无法明确分辨出先删缓存和先更新数据库哪个方式更好,因为它们都存在问题。后面我们会进一步对这两种方式进行比较,但是在这里我们先探讨一下,上述场景出现的问题,应该如何解决呢?
实际上,无论上面我们采用哪种方式去同步缓存与数据库,
在第二步出现失败的时候,
都建议采用重试机制解决,
因为最终我们是要解决掉这个错误的。
而为了避免重试机制影响主要业务的执行,
一般建议重试机制采用异步的方式执行,如下图:
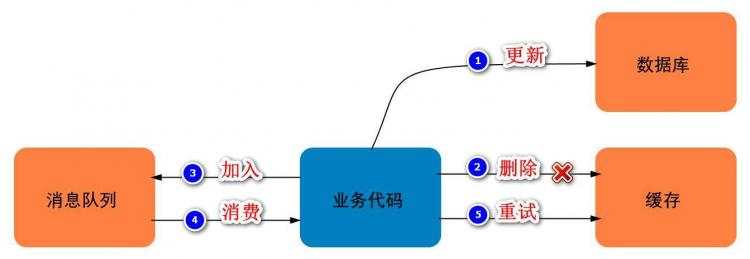
这里我们按照先更新数据库,再删除缓存的方式,来说明重试机制的主要步骤:
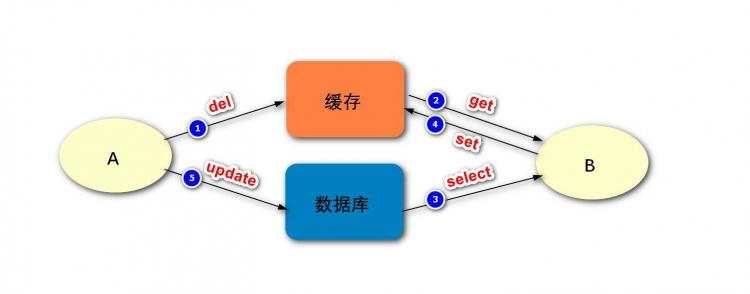
如上图,是先删除缓存再更新数据库,在没有出现失败时可能出现的问题:
可见,进程A的两步操作均成功,
但由于存在并发,
在这两步之间,
进程B访问了缓存。
最终结果是,缓存中存储了旧的数据,而数据库中存储了新的数据,二者数据不一致。
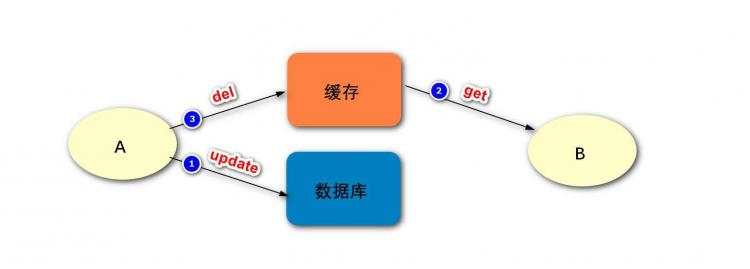
如上图,是先更新数据库再删除缓存,再没有出现失败时可能出现的问题:
可见,最终缓存与数据库的数据是一致的,并且都是最新的数据。
但进程B在这个过程里读到了旧的数据,
可能还有其他进程也像进程B一样,在这两步之间读到了缓存中旧的数据,
但因为这两步的执行速度会比较快,所以影响不大。
对于这两步之后,其他进程再读取缓存数据的时候,就不会出现类似于进程B的问题了。
最终结论:
经过对比你会发现,
先更新数据库、再删除缓存是影响更小的方案。
如果第二步出现失败的情况,
则可以采用重试机制解决问题。
上面我们提到,
如果是先删缓存、再更新数据库,
在没有出现失败时可能会导致数据的不一致。
如果在实际的应用中,
出于某些考虑我们需要选择这种方式,
那有办法解决这个问题吗?
答案是有的,那就是采用延时双删的策略,
延时双删的基本思路如下:
采用读写分离的架构怎么办?
如果数据库采用的是读写分离的架构,那么又会出现新的问题,如下图:
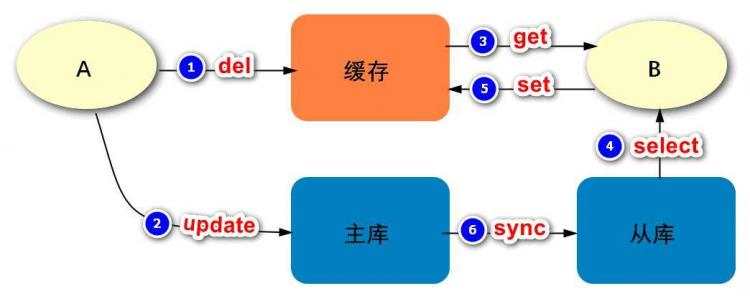
进程A先删除缓存,再更新主数据库,然后主库将数据同步到从库。
而在主从数据库同步之前,可能会有进程B访问了缓存,
发现数据不存在,进而它去访问从库获取到旧的数据,然后同步到缓存。
这样,最终也会导致缓存与数据库的数据不一致。
这个问题的解决方案,依然是采用延时双删的策略,
但是在评估延长时间的时候,要考虑到主从数据库同步的时间。
第二次删除失败了怎么办?
如果第二次删除依然失败,则可以增加重试的次数,
但是这个次数要有限制,
当超出一定的次数时,要采取报错、记日志、发邮件提醒等措施。
估计是 三个线程
同时执行
顺序执行
交替执行
之类的题目
使用 join
public class ThreadTest1 {
// T1、T2、T3三个线程顺序执行
public static void main(String[] args) {
Thread t1 = new Thread(new Work(null));
Thread t2 = new Thread(new Work(t1));
Thread t3 = new Thread(new Work(t2));
t1.start();
t2.start();
t3.start();
}
static class Work implements Runnable {
private Thread beforeThread;
public Work(Thread beforeThread) {
this.beforeThread = beforeThread;
}
public void run() {
if (beforeThread != null) {
try {beforeThread.join();System.out.println("thread start:" + Thread.currentThread().getName());
} catch (InterruptedException e) {e.printStackTrace();
}
} else {
System.out.println("thread start:" + Thread.currentThread().getName());
}
}
}
}
package thread;
import java.util.concurrent.CountDownLatch;
public class TestCountDownLatch {
class Worker implements Runnable{
CountDownLatch countDownLatch;
Worker(CountDownLatch countDownLatch){
this.countDownLatch = countDownLatch;
}
@Override
public void run() {
try {countDownLatch.await(); // 等待其它线程System.out.println(Thread.currentThread().getName() + "启动@" + System.currentTimeMillis());
} catch (InterruptedException e) {e.printStackTrace();
}
}
}
public void doTest() throws InterruptedException {
final int N = 5; // 线程数
CountDownLatch countDownLatch = new CountDownLatch(N);
for(int i=0;i
countDownLatch.countDown();
}
}
public static void main(String[] args) throws InterruptedException {
TestCountDownLatch testCountDownLatch = new TestCountDownLatch();
testCountDownLatch.doTest();
}
}
public class AlterThreadTest {
private ReentrantLock lock = new ReentrantLock();
Condition aCOndition= lock.newCondition();
Condition bCOndition= lock.newCondition();
public static void main(String[] args) {
AlterThreadTest test = new AlterThreadTest();
test.new AOutput().start();
test.new BOutput().start();
}
class AOutput extends Thread {
@Override
public void run() {
while (true) {try { lock.lock(); System.out.println("A"); bCondition.signal(); aCondition.await();} catch (InterruptedException e) { e.printStackTrace();} finally { lock.unlock();}
}
}
}
class BOutput extends Thread {
@Override
public void run() {
while (true) {try { lock.lock(); System.out.println("B"); aCondition.signal(); bCondition.await();} catch (InterruptedException e) { e.printStackTrace();} finally { lock.unlock();}
}
}
}
}
剑指offer
jvm虚拟机
架构设计
MySQL必知必会
服务器被黑了 防患于未然
作者:yhs98
链接:https://www.nowcoder.com/discuss/622474?type=all&order=time&pos=&page=1&channel=-1&source_id=search_all_nctrack
来源:牛客网













 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有