导读:本期为 AI 嵌入式简报 20201120 期,将为您带来 8 条相关新闻,希望对您有所帮助~
今日推送干货多多,为关注嵌入式AI的你量身定制~
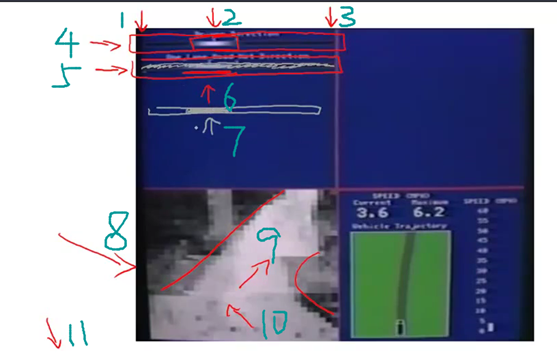
1. 澎峰科技CEO张先轶详解利用AI开发板实现面向无人机的嵌入式视觉应用开发

本文为澎峰科技CEO张先轶在智东西主办的“无人机视觉创新论坛”的演讲内容。张先轶老师的演讲主题为《利用AI开发板实现面向无人机的嵌入式视觉应用开发》。
在本次演讲中,张先轶老师首先介绍了AI开发板硬件选型,之后对嵌入式AI软件性能和相关算法的优化展开详细分析。
本文为此次演讲的图文整理。
演讲的主题为《利用AI开发板实现面向无人机的嵌入式视觉应用开发》,内容主要分为以下3个部分:
1、AI开发板硬件选型
2、嵌入式AI软件性能优化
3、嵌入式AI算法模型
2. TensorFlow为新旧Mac特供新版本,GPU可用于训练,速度最高提升7倍

苹果「一呼百应」的号召力在机器学习领域似乎也不例外。新版 Mac 推出还不到两周,谷歌就把专为 Mac 优化的 TensorFlow 版本做好了,训练速度最高提升到原来的 7 倍。
对于开发者、工程师、科研工作者来说,Mac 一直是非常受欢迎的平台,也有人用 Mac 训练神经网络,但训练速度一直是一个令人头疼的问题。
上周,苹果发布了搭载 Arm 架构 M1 芯片的三款新 Mac,于是就有人想问:用它们训练神经网络能快一点吗?
今天,主流机器学习框架 TensorFlow 发文表示:我们专门做了一版为 Mac 用户优化的 TensorFlow 2.4 框架,M1 版 Mac 和英特尔版 Mac 都能用。这一举动有望大幅降低模型训练和部署的门槛。
3. 干货!在C++平台上部署PyTorch模型流程+踩坑实录
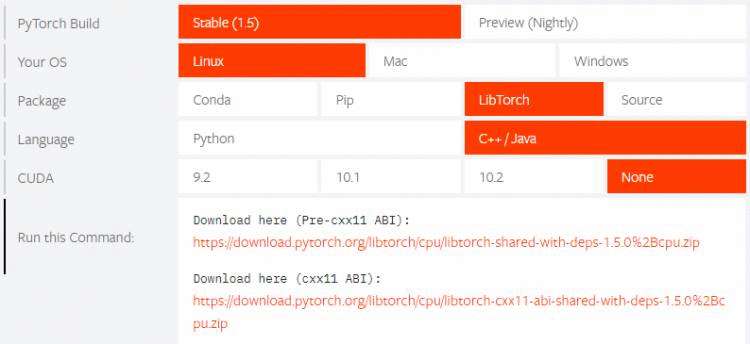
原文地址:https://zhuanlan.zhihu.com/p/146453159
最近因为工作需要,要把pytorch的模型部署到c++平台上,基本过程主要参照官网的教学示例,期间发现了不少坑,此为记录贴。
本文主要讲解如何将pytorch的模型部署到c++平台上的模型流程,按顺序分为四大块:
4. 420 FPS!LSTR:基于Transformer的车道线检测网络

论文:https://arxiv.org/abs/2011.04233
代码即将开源!
https://github.com/liuruijin17/LSTR
性能优于PolyLaneNet等网络,速度可高达420 FPS!
车道线检测是将车道识别为近似曲线的过程,被广泛用于自动驾驶汽车的车道线偏离警告和自适应巡航控制。流行的分两步解决问题的pipeline:特征提取和后处理。虽然有用,但效率低下,在学习全局上下文和通道的长而细的结构方面存在缺陷。
本文提出了一种端到端方法,该方法可以直接输出车道形状模型的参数,使用通过transformer构建的网络来学习更丰富的结构和上下文。车道形状模型是基于道路结构和摄像头姿势制定的,可为网络输出的参数提供物理解释。transformer使用自我注意机制对非局部交互进行建模,以捕获细长的结构和全局上下文。
该方法已在TuSimple基准测试中得到验证,并以最轻巧的模型尺寸和最快的速度显示了最新的准确性。
此外,我们的方法对具有挑战性的自收集车道线检测数据集显示出出色的适应性,显示了其在实际应用中的强大部署潜力。
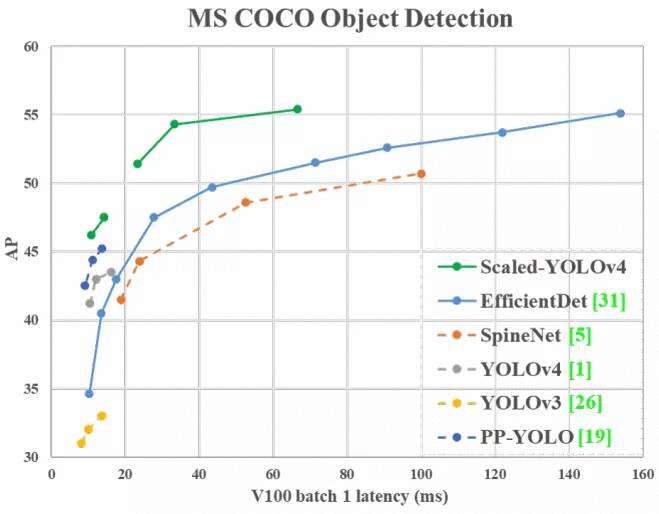
5. YOLOv4官方改进版来了!55.8% AP!速度最高达1774 FPS,Scaled-YOLOv4正式开源!
论文:
https://arxiv.org/2011.08036
GitHub :https://github.com/WongKinYiu/ScaledYOLOv4
本文是YOLOv4的原班人马(包含CSPNet一作与YOLOv4一作AB大神)在YOLO系列的继续扩展,从影响模型扩展的几个不同因素出发,提出了两种分别适合于低端GPU和高端GPU的YOLO。
该文提出一种“网路扩展(Network Scaling)”方法,它不仅针对深度、宽度、分辨率进行调整,同时调整网络结果,作者将这种方法称之为Scaled-YOLOv4。
由此得到的YOLOv4-Large取得了SOTA结果:在MS-COCO数据集上取得了55.4%AP(73.3% AP50),推理速度为15fps@Tesla V100;在添加TTA后,该模型达到了55.8%AP(73.2%AP50)。截止目前,在所有公开论文中,YOLOv-Large在COCO数据集上取得最佳指标。而由此得到的YOLOv4-tiny取得了22.0%AP(42.0%AP50),推理速度为443fps@TRX 2080Ti;经由TensorRT加速以及FP16推理,batchsize=4时其推理速度可达1774fps。
该文的主要贡献包含以下几点:
设计了一种强有力的“网络扩展”方法用于提升小模型的性能,可以同时平衡计算复杂度与内存占用;
设计了一种简单而有效的策略用于扩展大目标检测器;
分析了模型扩展因子之间的相关性并基于最优划分进行模型扩展;
通过实验证实:FPN structure is inherently a once-for-all structure
基于前述分析设计了两种高效模型:YOLOv4-tiny与YOLOv4-Large。
6. 人像抠图已经满足不了研究者了,这个研究专门给动物抠图!
在这个图像和视频逐渐成为主流媒介的时代,大家早已对「抠图」习以为常,说不定还看过几部通过「抠图」拍摄的电视剧呢。然而,相比于人像抠图,长相各异、浑身毛茸茸的动物似乎难度更大。
那么,是否有专用于动物的抠图技术呢?IEEE 会士 Jizhizi Li、陶大程等人就开发了一个专门处理动物抠图的端到端抠图技术。
动物的外观和毛皮特征给现有的方法带来了挑战,这些方法通常要求额外的用户输入(如 trimap)。
为了解决这些问题,陶大程等人研究了语义和抠图细节,将任务分解为两个并行的子任务:高级语义分割和低级细节抠图。具体而言,该研究提出了新型方法——Glance and Focus Matting network (GFM),使用共享编码器和两个单独的解码器以协作的方式学习两项子任务,完成端到端动物图像抠图。
7. 英特尔发布首款用于5G、人工智能、云端与边缘的结构化ASIC
原文地址:
http://www.eepw.com.cn/article/202011/420476.htm
2020年11月18日,在英特尔FPGA技术大会上,英特尔发布了全新可定制解决方案英特尔® eASIC N5X,帮助加速5G、人工智能、云端与边缘工作负载的应用性能。该可定制解决方案搭载了英特尔® FPGA兼容的硬件处理器系统,是首个结构化eASIC产品系列。英特尔® eASIC N5X通过FPGA中的嵌入式硬件处理器帮助客户将定制逻辑与设计迁移到结构化ASIC中,带来了更低的单位成本,更快的性能和更低的功耗等好处。
英特尔® eASIC N5X器件作为具有创新性的新产品,与FPGA相比最高可降低50%的核心能耗和成本,与ASIC相比则提升了面市速度,降低了非重复性工程成本。用户可以创建功耗优化、高性能、高度差异化的解决方案。
8. M1808 AI 核心板搭载5G模块,助力5G布局工业领域
原文地址:
http://www.eepw.com.cn/article/202011/419966.htm
关于5G 的讨论,虽然目前更多的是聚焦于智能手机,但事实上,在5G的大应用时代,智能手机只是其中很小的一部分,更多的应用会聚焦于工业互联网、物联网、车联网等,并悄无声息地渗透到人们的生活当中。
在2020年初,ZLG致远电子首款人工智能AI核心板M1808正式发布。该款核心板采用高端双核架构,集成神经网络处理器NPU,内置专业AI算法,为用户提供“硬件+软件+算法”系统化解决方案。M1808还有丰富的外设接口,便于应用扩展。视频支持MIPI/CIF/BT1120输入,支持MIPI/RGB显示输出;具有PWM/I2C/SPI/UART等一系列传感器输入输出接口;具有USB3.0/USB2.0/PCIE等高速设备接口,因此ZLG M1808 AI核心板同时支持有方的N510M 5G模块驱动。
M1808AI核心板搭配5G上网模块Neoway N510M,产品具有出色的射频性能,支持 5G、4G、3G,频段覆盖广,支持SA与NSA组网方式,支持Sub-6GHz,覆盖全面。集成各种网络协议并提供行业标准接口,最大限度满足eMBB场景下的超高速数据传输应用,是电力物联网、安防监控、智慧能源、工业控制、智慧交通等领域的较好的选择。


你可以添加微信17775982065为好友,注明:公司+姓名,拉进 RT-Thread 官方微信交流群!

RT-Thread
让物联网终端的开发变得简单、快速,芯片的价值得到最大化发挥。Apache2.0协议,可免费在商业产品中使用,不需要公布源码,无潜在商业风险。
长按二维码,关注我们
 点击阅读原文进入官网
点击阅读原文进入官网

你点的每个“在看”,我都认真当成了喜欢

![[TensorFlow系列3]:初学者是选择Tensorflow2.x还是1.x? 2.x与1.x的主要区别?](https://img.php1.cn/3cd4a/189d8/978/7dbdf0f38ad53545.jpeg)





 京公网安备 11010802041100号
京公网安备 11010802041100号