在企业级开源日志管理平台ELK VS GRAYLOG一文中,我简单阐述了日志管理平台对技术人员的重要性,并把ELK Stack和Graylog进行了标记。本篇作为“企业级开源日志管理平台”的延伸,基于我在生产环境中的使用经验,向读者介绍ELK Stack的安装与配置。不足之处,还望指正。
架构
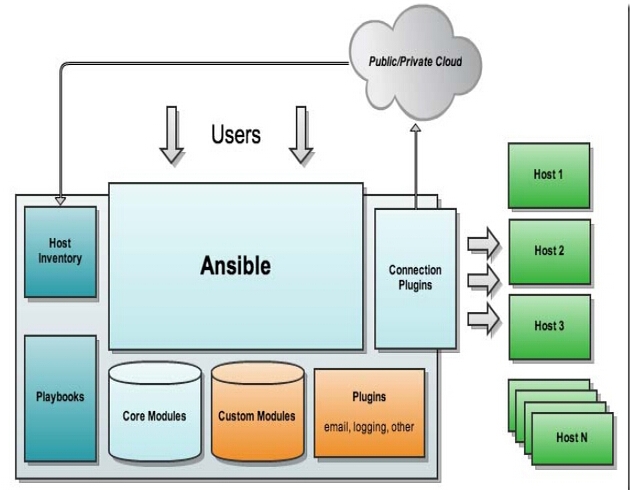
Beats工具收集各节的日志,以list数据结构存储在Redis中,Logstash从Redis消费这些数据并在条件匹配及规则过滤后,输出到Elasticsearch,最终通过kibana展示给用户。
环境介绍
Elastic Stack的产品被设计成需要一起使用,并且版本同步发布,以简化安装和升级过程。本次安装,采用最新的6.5通用版。完整堆栈包括:
1. Beats 6.5
2. Elasticsearch 6.5
3. Elasticsearch Hadoop 6.5(不在本次介绍范围)
4. Kibana 6.5
5. Logstash 6.5
操作系统CentOS7.5,JDK需要8及以上版本。
官方介绍的安装途径包括:tar包安装、rpm包安装、docker安装、yum仓库安装,我使用RPM包安装。
系统设置
Elasticsearch默认监听127.0.0.1,这显然无法跨主机交互。当我们对网络相关配置进行修改后,Elasticsearch由开发模式切换为生产模式,会在启动时进行一系列安全检查,以防出现配置不当导致的问题。
这些检查主要包括:
1. max_map_count:Elasticsearch默认使用混合的NioFs( 注:非阻塞文件系统)和MMapFs( 注:内存映射文件系统)存储索引。请确保你配置的最大映射数量,以便有足够的虚拟内存可用于mmapped文件。此值设置不当,启动Elasticsearch时日志会输出以下错误:[1] bootstrap checks failed
[1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决方法:
- 修改最大文件描述符
- 修改最大线程数
注意:通过RPM包或YUM形式安装,Elasticsearch会自动优化这些参数,如果采用tar包的形式安装,除了手动修改这些配置,还需要创建启动Elasticsearch程序的系统用户,Elasticsearch不允许以root身份运行。
安装
安装顺序:
1. Elasticsearch
2. Kibana
3. Logstash
4. Beats
安装Elasticsearch
- 导入Elasticsearch PGP key,使用Elasticsearch签名密钥(PGP key D88E42B4,可从https://pgp.mit.edu获得)和fingerprint对所有包进行签名:
- 下载安装RPM包
- 配置文件
Elasticsearch包含三个配置文件:
elasticsearch.yml:配置Elasticsearch
jvm.options:设置Elasticsearch堆栈大小,对JVM进行优化
log4j2.properties:定义Elasticsearch日志
这些文件的默认位置取决于安装方式。tar包形式的配置文件目录$ES_HOME/config,RPM包默认位置/etc/elasticsearch/。
elasticsearch.yml文件采用yaml格式,以修改路径为例:
elasticsearch.yml文件也支持环境变量,引用环境变量的方法${…},例如:
jvm.options文件包含以下格式:
行分割;
空行被忽略;
以#开头表示注释;
以-开头的行被视为独立于JVM版本,此项配置会影响所有版本的JVM;
数字开头,后面跟一个:和一个-号的行,只会影响匹配此数字的JVM版本,例如:8:-Xmx2g,只会影响JDK8;
数字开头跟一个-号再跟一个数字再跟一个:,定义两个版本之间,且包含这两个版本,例如8-9:-Xmx2g,影响JDK8,JDK9。
注意:在配置中,应保证JVM堆栈min和max的值相同,Xms表示总堆栈空间的初始值,XmX表示总堆栈空间的最大值。
配置文件中,我将bootstrap.memory_lock的值设为了true,启动时遇到了以下错误:Elasticsearch process memory locking failed
解决此问题,还需要修改三个地方:
1. /etc/sysconfig/elasticsearch
替换4g为总内存的一半(Elasticsearch官方建议是主机总内存的一半)
2. /etc/security/limits.conf
需要将elasticsearch替换为运行Elasticsearch程序的用户
3. /usr/lib/systemd/system/elasticsearch.service
取消服务脚本文件/usr/lib/systemd/system/elasticsearch.service中对LimitMEMLOCK=infinity的注释
然后运行systemctl daemon-reload命令
- 启动节点
Elasticsearch安装完毕,接下来安装Kibana。
安装Kibana
同样使用RPM的形式安装
1. 安装公钥
- 下载rpm包
- 配置文件
Kibana启动时从/etc/kibana/kibana.yml文件里读取配置信息,配置文件内容如下:
- 启动
安装Logstash
- 下载
安装Filebeat
Filebeat客户端是一个轻量级,资源消耗较低的工具,它从服务器的文件中收集日志,并将这些日志转发到Logstash进行处理。
1. 下载filebeat
- 配置文件
- 启动Filebeat
ELK各组件安装完成,开始日志收集相关的配置。
Logstash pipeline
Logstash管道包含两个必要元素Inputs和Outputs,以及一个可选元素Filter。Inputs接收、消费元数据,Filter根据设定过滤数据,Outputs将数据输出到指定程序,我这里定义的是输出到Elasticsearch。
我配置了Filebeat输出message日志和www.vtlab.io 的访问日志,现在创建Logstash管道接收这些数据。
配置文件中,我定义了两个patterns:”message” => “%{SYSLOGBASE2}”与”message” => “%{COMBINEDAPACHELOG}”,一个匹配系统messages日志,一个匹配Nginx访问日志,其他日志类型,就需要不同的Patterns了。ELK提供了很多默认的Patterns,也可以自定义。
定义Patterns
一个简单的方法,通过以下两个步骤实现:
1. 打开Grokdebug discover页面,输入日志内容到文本框,点击discover按钮,如下图:
2. 打开Grokdebug页面,按图中步骤操作,输出内容就是Patterns。
启动Logstash
- 启动前,检验first-pipeline.conf配置文件的语法是否正确:
输出中包含以上内容,说明配置文件正确。
2. 启动指定pipeline:
–config.reload.automatic:开启自动加载配置,这样在每次修改配置文件时会自动加载配置文件
Kibana UI
日志流已经通过Filebeat、Redis、Logstash进入了Elasticsearch,我们通过Kibana对Elasticsearch做一些可视化的管理,方便查看日志。
创建索引
登录Kibana页面,在浏览器中输入 http://10.0.0.21:5601 (10.0.0.21为部署Kibana主机的IP地址,5601是Kibana监听的端口),如图:
点击“Management”–>“Index Patterns”–>“Create index pattern”,在Index pattern框中填写Index name,也就是我们通过Logstash输出到Elasticsearch时的索引名”message-*”和”logstash-nginx-*”,点击Next step,在“Time Filter field name”中选择“@timestamp”,最后点击“Create index pattern”完成索引创建。
经过以上的步骤,就可以在Kibana的discover中依照索引查看日志了。
通过GeoIP展示用户分布
我在Logstash的filter插件部分进行了GeoIP相关的配置,现在我演示下将用户的分布按照地图展示出来。Kibana的图形化可谓丰富多姿,其他的就交给读者自己探索了。
1. 点击左侧导航栏“Dashboard”–>“Create new dashboard”
2. 点击页面中间的“add”标签,如果之前在Visualize中创建过地图,可以通过搜索名字添加,没有的话,需要先在Visualize中创建
3. 点击“Add new Visualization”,选择Maps下的“Coordinate Map”
4. 选择我们需要创建地图的索引“logstash-nginx”
5. 点击“Geo Coordinates”,选择“Geohash”
6. 点击“Options”调整颜色及图例说明位置
7. 点击页面右上角的“Save”按钮,创建完成
安全
细心的读者朋友可能已经发现了,登录kibana的时候,页面并没有验证功能,任何能访问Kibana地址的人,都能查询日志,这对我们来说是不可接受的。
改进方法:
1. X-Pack:Kibana本身不提供认证机制,需要通过X-Pack插件来实现。X-Pack是付费插件,可以申请License获取一年期的免费试用。
2. Nginx:通过htpasswd创建用户及密码,进行Kibana认证。
结尾
ELK Stack包含的功能太多了,这里只介绍了些常用功能,足以应付日常所需,更多功能,还需深入探索。




 京公网安备 11010802041100号
京公网安备 11010802041100号