preface
Python在大数据行业非常火爆近两年,as a pythonic,所以也得涉足下大数据分析,下面就聊聊它们。
Python数据分析与挖掘技术概述
所谓数据分析,即对已知的数据进行分析,然后提取出一些有价值的信息,比如统计平均数,标准差等信息,数据分析的数据量可能不会太大,而数据挖掘,是指对大量的数据进行分析与挖倔,得到一些未知的,有价值的信息等,比如从网站的用户和用户行为中挖掘出用户的潜在需求信息,从而对网站进行改善等。
数据分析与数据挖掘密不可分,数据挖掘是对数据分析的提升。数据挖掘技术可以帮助我们更好的发现事物之间的规律。所以我们可以利用数据挖掘技术可以帮助我们更好的发现事物之间的规律。比如发掘用户潜在需求,实现信息的个性化推送,发现疾病与病状甚至病与药物之间的规律等。
预先善其事必先利其器
我们首先聊聊数据分析的模块有哪些:
- numpy 高效处理数据,提供数组支持,很多模块都依赖它,比如pandas,scipy,matplotlib都依赖他,所以这个模块都是基础。所以必须先安装numpy。
- pandas 主要用于进行数据的采集与分析
- scipy 主要进行数值计算。同时支持矩阵运算,并提供了很多高等数据处理功能,比如积分,微分方程求样等。
- matplotlib 作图模块,结合其他数据分析模块,解决可视化问题
- statsmodels 这个模块主要用于统计分析
- Gensim 这个模块主要用于文本挖掘
- sklearn,keras 前者机器学习,后者深度学习。
下面就说说这些模块的基础使用。
numpy模块安装与使用
安装:
下载地址是:http://www.lfd.uci.edu/~gohlke/pythonlibs/
我这里下载的包是1.11.3版本,地址是:http://www.lfd.uci.edu/~gohlke/pythonlibs/f9r7rmd8/numpy-1.11.3+mkl-cp35-cp35m-win_amd64.whl
下载好后,使用pip install "numpy-1.11.3+mkl-cp35-cp35m-win_amd64.whl"
安装的numpy版本一定要是带mkl版本的,这样能够更好支持numpy
numpy简单使用
import numpyx=numpy.array([11,22,33,4,5,6,7,]) #创建一维数组
x2=numpy.array([['asfas','asdfsdf','dfdf',11],['1iojasd','123',989012],["jhyfsdaeku","jhgsda"]]) #创建二维数组,注意是([])x.sort() #排序,没有返回值的,修改原处的值,这里等于修改了X
x.max() # 最大值,对二维数组都管用
x.min() # 最小值,对二维数组都管用
x1=x[1:3] # 取区间,和python的列表没有区别
生成随机数
主要使用numpy下的random方法。
#numpy.random.random_integers(最小值,最大值,个数) 获取的是正数
data = numpy.random.random_integers(1,20000,30) #生成整形随机数
#正态随机数 numpy.random.normal(均值,偏离值,个数) 偏离值决定了每个数之间的差 ,当偏离值大于开始值的时候,那么会产生负数的。
data1 = numpy.random.normal(3.2,29.2,10) # 生成浮点型且是正负数的随机数
pandas
使用pip install pandas即可
直接上代码:
下面看看pandas输出的结果, 这一行的数字第几列,第一列的数字是行数,定位一个通过第一行,第几列来定位:
print(b)0 1 2 3
0 1 2 3 4.0
1 sdaf dsaf 18hd NaN
2 1463 None None NaN
常用方法如下:
import pandas
a=pandas.Series([1,2,3,34,]) # 等于一维数组
b=pandas.DataFrame([[1,2,3,4,],["sdaf","dsaf","18hd"],[1463]]) # 二维数组
print(b.head()) # 默认取头部前5行,可以看源码得知
print(b.head(2)) # 直接传入参数,如我写的那样
print(b.tail()) # 默认取尾部前后5行
print(b.tail(1)) # 直接传入参数,如我写的那样
下面看看pandas对数据的统计,下面就说说每一行的信息
# print(b.describe()) # 显示统计数据信息3 # 3表示这个二维数组总共多少个元素
count 1.0 # 总数
mean 4.0 # 平均数
std NaN # 标准数
min 4.0 # 最小数
25% 4.0 # 分位数
50% 4.0 # 分位数
75% 4.0 # 分位数
max 4.0 # 最大值
转置功能:把行数转换为列数,把列数转换为行数,如下所示:
print(b.T) # 转置0 1 2
0 1 sdaf 1463
1 2 dsaf None
2 3 18hd None
3 4 NaN NaN
通过pandas导入数据
pandas支持多种输入格式,我这里就简单罗列日常生活最常用的几种,对于更多的输入方式可以查看源码后者官网。
CSV文件
csv文件导入后显示输出的话,是按照csv文件默认的行输出的,有多少列就输出多少列,比如我有五列数据,那么它就在prinit输出结果的时候,就显示五列
csv_data = pandas.read_csv('F:\Learnning\CSDN-python大数据\hexun.csv')
print(csv_data)
excel表格
依赖于xlrd模块,请安装它。
老样子,原滋原味的输出显示excel本来的结果,只不过在每一行的开头加上了一个行数
excel_data = pandas.read_excel('F:\Learnning\CSDN-python大数据\cxla.xls')
print(excel_data)
读取SQL
依赖于PyMySQL,所以需要安装它。pandas把sql作为输入的时候,需要制定两个参数,第一个是sql语句,第二个是sql连接实例。
conn=pymysql.connect(host="127.0.0.1",user="root",passwd="root",db="test")
sql="select * from fortest"
e=pda.read_sql(sql,conn)
读取HTML
依赖于lxml模块,请安装它。 显示的是时候是通过python的列表展示,同时添加了行与列的标识 输出显示的时候同时添加了行与列的标识 安装方法是先下载whl格式文件,然后通过 我们安装这个模块直接使用pip install即可。不需要提前下载whl后通过 pip install安装。 下面请看代码: 画出的图是这样的: 我们还可以对图稍作修改,添加一些样式,下面修改圆点图为红色的点,代码如下: 我们还可以画虚线图,代码如下所示: 还可以给图添加上标题,x,y轴的标签,代码如下所示 利用直方图能够很好的显示每一段的数据。下面使用随机数做一个直方图。 图形区别语言无法描述很详细,大家可以自信尝试。 举个例子: 什么是子图功能呢?子图就是在一个大的画板里面能够显示多张小图,每个一小图为大画板的子图。 我们现在可以通过一堆数据来绘图,根据图能够很容易的发现异常。下面我们就通过一个csv文件来实践下,这个csv文件是某个网站的文章阅读数与评论数。 下面看看代码: 转:https://www.cnblogs.com/liaojiafa/p/6239262.html
对于HTTPS的网页,依赖于BeautifulSoup4,html5lib模块。
读取HTML只会读取HTML里的表格,也就是只读取标签包裹的内容.
html_data = pandas.read_html('F:\Learnning\CSDN-python大数据\shitman.html') # 读取本地html文件。
html_from_online = pandas.read_html('https://book.douban.com/') # 读取互联网的html文件
print(html_data)
print('html_from_online')读取txt文件
text_data = pandas.read_table('F:\Learnning\CSDN-python大数据\dforsay.txt')
print(text_data)scipy
pip install “包名” 安装。whl包下载地址是:http://www.lfd.uci.edu/~gohlke/pythonlibs/f9r7rmd8/scipy-0.18.1-cp35-cp35m-win_amd64.whlmatplotlib 数据可视化分析
from matplotlib import pylab
import numpy
# 下面2行定义X轴,Y轴
x=[1,2,3,4,8]
y=[1,2,3,4,8]
# plot的方法是这样使用(x轴数据,y轴数据,展现形式)
pylab.plot(x,y) # 先把x,y轴的信息塞入pylab里面,再调用show方法来画图
pylab.show() # 这一步开始画图,默认是至线图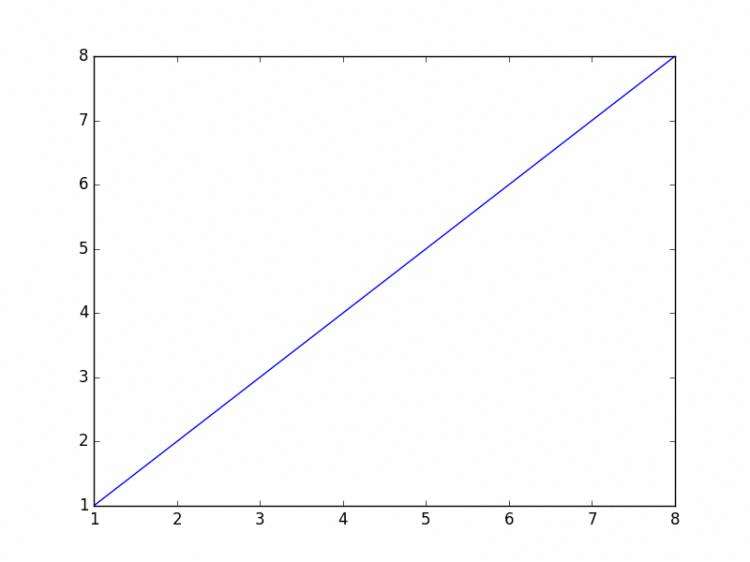
下面说说修改图的样式
关于图形类型,有下面几种:
- 直线关于颜色,有下面几种:
关于形状,有下面几种:
* 星形pylab.plot(x,y,'or') # 添加O表示画散点图,r表示red
pylab.show()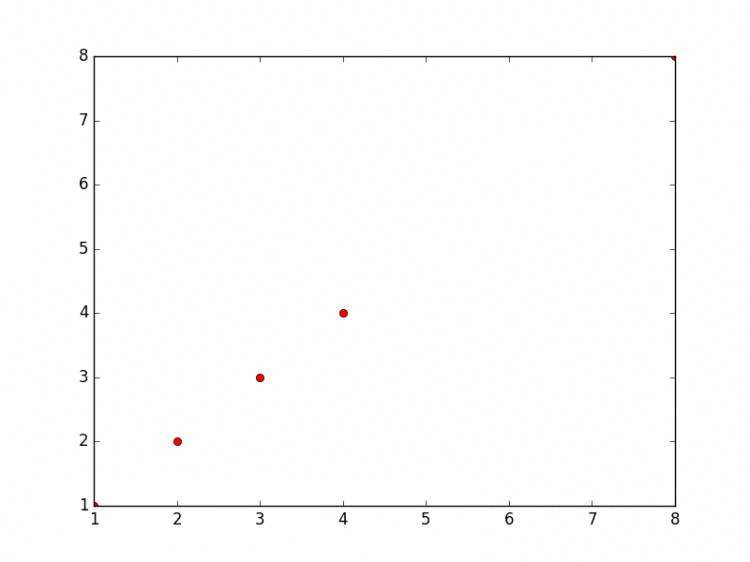
pylab.plot(x,y,'r:')
pylab.show()pylab.plot(x,y,'pr--') #p是图形为五角星,r为红色,--表示虚线
pylab.title('for learnning') # 图形标题
pylab.xlabel('args') # x轴标签
pylab.ylabel('salary') # y轴标签
pylab.xlim(2) # 从y轴的2开始做线
pylab.show()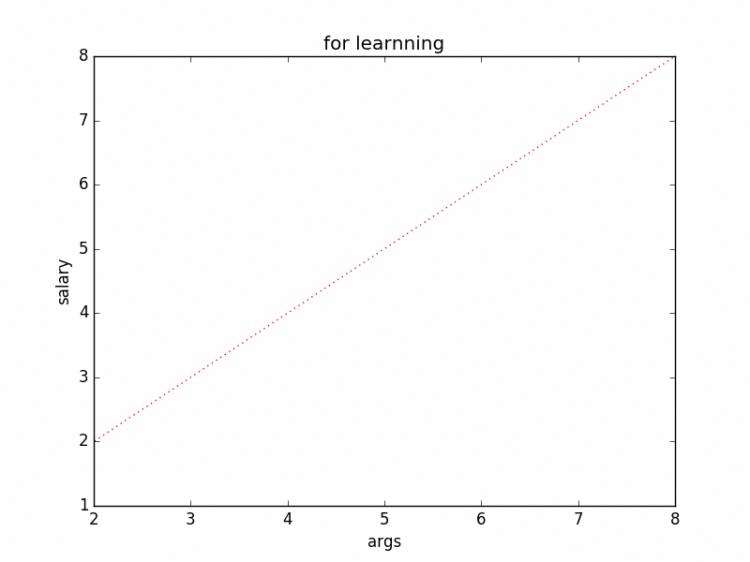
直方图
data1 = numpy.random.normal(5.0,4.0,10) # 正态随机数
pylab.hist(data1)
pylab.show()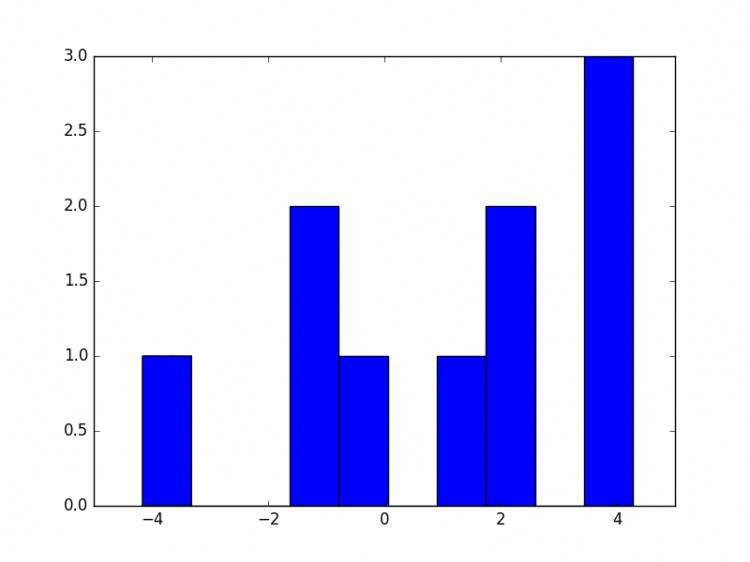
Y轴为出现的次数,X轴为这个数的值(或者是范围)还可以指定直方图类型通过histtype参数:
are given the bars are aranged side by side.
data are stacked on top of each other.
unfilled.
filled.sty=numpy.arange(1,30,2)
pylab.hist(data1,histtype='stepfilled')
pylab.show() 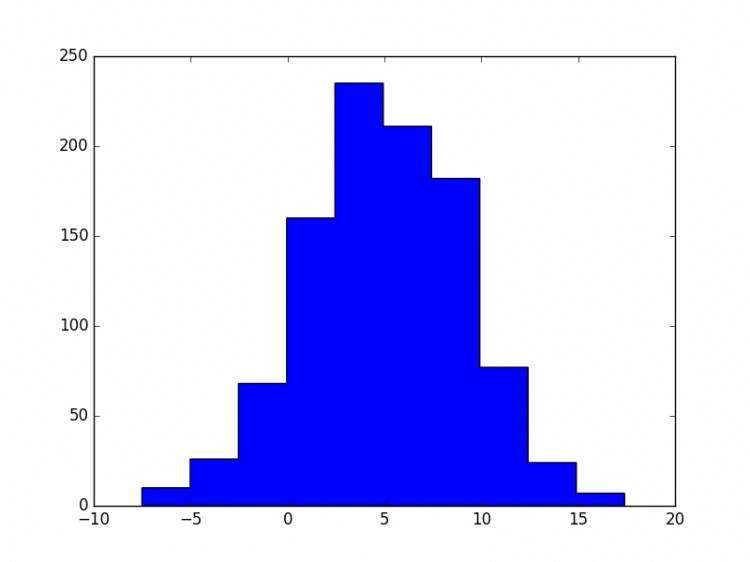
子图功能
我们知道生成一个图是使用plot功能,子图就是subplog。代码操作如下:#subplot(行,列,当前区域)
pylab.subplot(2,2,1) # 申明一个大图里面划分成4块(即2*2),子图使用第一个区域(坐标为x=1,y=1)
pylab.subplot(2,2,2) # 申明一个大图里面划分成4块(即2*2),子图使用第二个区域(坐标为x=2,y=2)
x1=[1,4,6,9]
x2=[3,21,33,43]
pylab.plot(x1,x2) # 这个plot表示把x,y轴数据塞入前一个子图中。我们可以在每一个子图后使用plot来塞入x,y轴的数据
pylab.subplot(2,1,2) # 申明一个大图里面划分成2块(即),子图使用第二个区域(坐标为x=1,y=2)
pylab.show()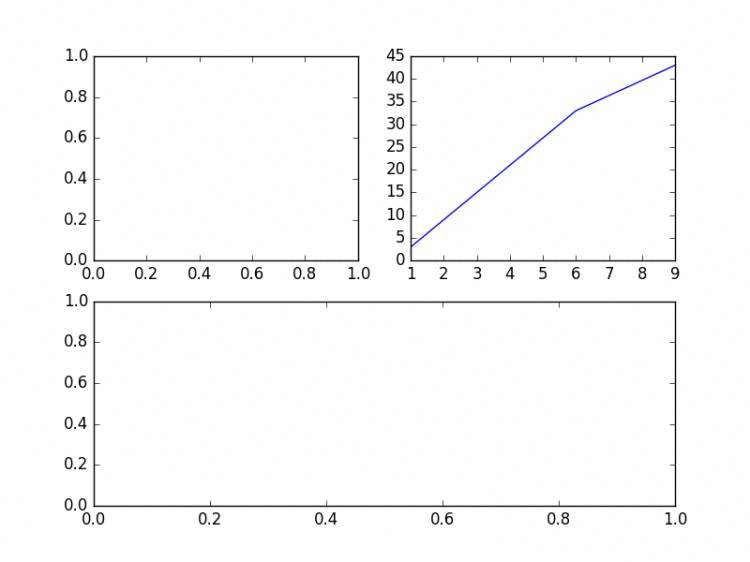
实践小例子
先说说这个csv的文件结构,第一列是序号,第二列是每篇文章的URL,第三列每篇文章的阅读数,第四列是每篇评论数。
我们的需求就是把评论数作为Y轴,阅读数作为X轴,所以我们需要获取第三列和第四列的数据。我们知道获取数据的方法是通过pandas的values方法来获取某一行的值,在对这一行的值做切片处理,获取下标为3(阅读数)和4(评论数)的值,但是,这里只是一行的值,我们需要是这个csv文件下的所有评论数和阅读数,那怎么办?聪明的你会说,我自定义2个列表,我遍历下这个csv文件,把阅读数和评论数分别添加到对应的列表里,这不就行了嘛。呵呵,其实有一个更快捷的方法,那么就是使用T转置方法,这样再通过values方法,就能直接获取这一评论数和阅读数了,此时在交给你matplotlib里的pylab方法来作图,那么就OK了。了解思路后,那么就写吧。
csv_data = pandas.read_csv('F:\Learnning\CSDN-python大数据\hexun.csv')
dt = csv_data.T # 装置下,把阅读数和评论数转为行
readers=dt.values[3]
comments = dt.values[4]
pylab.xlabel(u'reads')
pylab.ylabel(u'comments') # 打上标签
pylab.title(u"The Article's reads and comments")
pylab.plot(readers,comments,'ob')
pylab.show()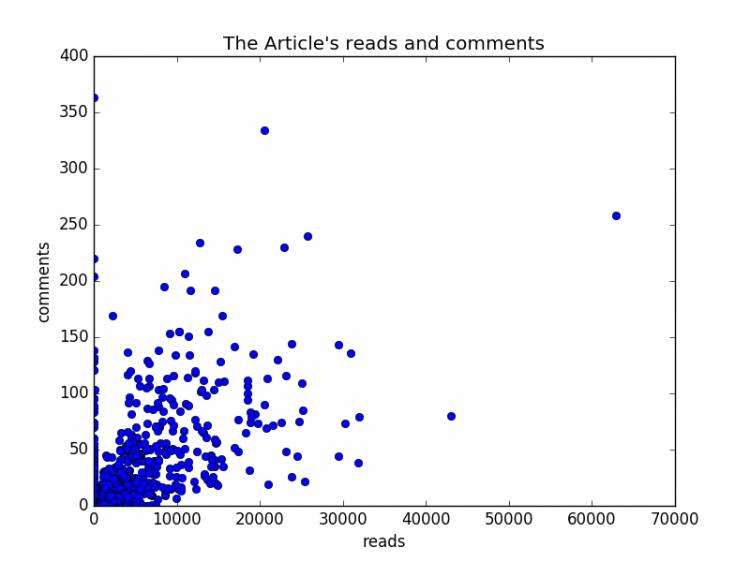









Copyright © 1998 - 2020 PHP1.CN. All Rights Reserved |  京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有

