命名实体识别在越来越多的场景下被应用,如自动问答、知识图谱等。非结构化的文本内容有很多丰富的信息,但找到相关的知识始终是一个具有挑战性的任务,命名实体识别也不例外。前面我们用隐马尔
命名实体识别在越来越多的场景下被应用,如自动问答、知识图谱等。非结构化的文本内容有很多丰富的信息,但找到相关的知识始终是一个具有挑战性的任务,命名实体识别也不例外。
前面我们用隐马尔可夫模型(HMM)自己尝试训练过一个分词器,其实 HMM 也可以用来训练命名实体识别器,但在本文,我们讲另外一个算法——条件随机场(CRF),来训练一个命名实体识别器。
浅析条件随机场(CRF)
条件随机场(Conditional Random Fields,简称 CRF)是给定一组输入序列条件下另一组输出序列的条件概率分布模型,在自然语言处理中得到了广泛应用。
首先,我们来看看什么是随机场。“随机场”的名字取的很玄乎,其实理解起来不难。随机场是由若干个位置组成的整体,当按照某种分布给每一个位置随机赋予一个值之后,其全体就叫做随机场。
还是举词性标注的例子。假如我们有一个十个词形成的句子需要做词性标注。这十个词每个词的词性可以在我们已知的词性集合(名词,动词……)中去选择。当我们为每个词选择完词性后,这就形成了一个随机场。
了解了随机场,我们再来看看马尔科夫随机场。马尔科夫随机场是随机场的特例,它假设随机场中某一个位置的赋值仅仅与和它相邻的位置的赋值有关,和与其不相邻的位置的赋值无关。
继续举十个词的句子词性标注的例子。如果我们假设所有词的词性只和它相邻的词的词性有关时,这个随机场就特化成一个马尔科夫随机场。比如第三个词的词性除了与自己本身的位置有关外,还只与第二个词和第四个词的词性有关。
理解了马尔科夫随机场,再理解 CRF 就容易了。CRF 是马尔科夫随机场的特例,它假设马尔科夫随机场中只有 X 和 Y 两种变量,X 一般是给定的,而 Y 一般是在给定 X 的条件下我们的输出。这样马尔科夫随机场就特化成了条件随机场。
在我们十个词的句子词性标注的例子中,X 是词,Y 是词性。因此,如果我们假设它是一个马尔科夫随机场,那么它也就是一个 CRF。
对于 CRF,我们给出准确的数学语言描述:设 X 与 Y 是随机变量,P(Y|X) 是给定 X 时 Y 的条件概率分布,若随机变量 Y 构成的是一个马尔科夫随机场,则称条件概率分布 P(Y|X) 是条件随机场。
基于 CRF 的中文命名实体识别模型实现
在常规的命名实体识别中,通用场景下最常提取的是时间、人物、地点及组织机构名,因此本模型也将提取以上四种实体。
1.开发环境。
本次开发所选用的环境为:
Sklearn_crfsuite
- Python 3.6
- Jupyter Notebook
2.数据预处理。
本模型使用人民日报1998年标注数据,进行预处理。语料库词性标记中,对应的实体词依次为 t、nr、ns、nt。对语料需要做以下处理:
- 将语料全角字符统一转为半角;
- 合并语料库分开标注的姓和名,例如:
温/nr 家宝/nr;
- 合并语料库中括号中的大粒度词,例如:
[国家/n 环保局/n]nt;
- 合并语料库分开标注的时间,例如:
(/w 一九九七年/t 十二月/t 三十一日/t )/w。
首先引入需要用到的库:
import re
import sklearn_crfsuite
from sklearn_crfsuite import metrics
from sklearn.externals import joblib
数据预处理,定义 CorpusProcess 类,我们还是先给出类实现框架:
class CorpusProcess(object):
def __init__(self):
"""初始化"""
pass
def read_corpus_from_file(self, file_path):
"""读取语料"""
pass
def write_corpus_to_file(self, data, file_path):
"""写语料"""
pass
def q_to_b(self,q_str):
"""全角转半角"""
pass
def b_to_q(self,b_str):
"""半角转全角"""
pass
def pre_process(self):
"""语料预处理 """
pass
def process_k(self, words):
"""处理大粒度分词,合并语料库中括号中的大粒度分词,类似:[国家/n 环保局/n]nt """
pass
def process_nr(self, words):
""" 处理姓名,合并语料库分开标注的姓和名,类似:温/nr 家宝/nr"""
pass
def process_t(self, words):
"""处理时间,合并语料库分开标注的时间词,类似: (/w 一九九七年/t 十二月/t 三十一日/t )/w """
pass
def pos_to_tag(self, p):
"""由词性提取标签"""
pass
def tag_perform(self, tag, index):
"""标签使用BIO模式"""
pass
def pos_perform(self, pos):
"""去除词性携带的标签先验知识"""
pass
def initialize(self):
"""初始化 """
pass
def init_sequence(self, words_list):
"""初始化字序列、词性序列、标记序列 """
pass
def extract_feature(self, word_grams):
"""特征选取"""
pass
def segment_by_window(self, words_list=None, window=3):
"""窗口切分"""
pass
def generator(self):
"""训练数据"""
pass
由于整个代码实现过程较长,我这里给出重点步骤,最后会在 Github 上连同语料代码一同给出,下面是关键过程实现。
对语料中的句子、词性,实体分类标记进行区分。标签采用“BIO”体系,即实体的第一个字为 B_*,其余字为 I_*,非实体字统一标记为 O。大部分情况下,标签体系越复杂,准确度也越高,但这里采用简单的 BIO 体系也能达到相当不错的效果。这里模型采用 tri-gram 形式,所以在字符列中,要在句子前后加上占位符。
def init_sequence(self, words_list):
"""初始化字序列、词性序列、标记序列 """
words_seq = [[word.split(u‘/‘)[0] for word in words] for words in words_list]
pos_seq = [[word.split(u‘/‘)[1] for word in words] for words in words_list]
tag_seq = [[self.pos_to_tag(p) for p in pos] for pos in pos_seq]
self.pos_seq = [[[pos_seq[index][i] for _ in range(len(words_seq[index][i]))]
for i in range(len(pos_seq[index]))] for index in range(len(pos_seq))]
self.tag_seq = [[[self.tag_perform(tag_seq[index][i], w) for w in range(len(words_seq[index][i]))]
for i in range(len(tag_seq[index]))] for index in range(len(tag_seq))]
self.pos_seq = [[u‘un‘]+[self.pos_perform(p) for pos in pos_seq for p in pos]+[u‘un‘] for pos_seq in self.pos_seq]
self.tag_seq = [[t for tag in tag_seq for t in tag] for tag_seq in self.tag_seq]
self.word_seq = [[u‘‘]+[w for word in word_seq for w in word]+[u‘‘] for word_seq in words_seq]
处理好语料之后,紧接着进行模型定义和训练,定义 CRF_NER 类,我们还是采用先给出类实现框架,再具体讲解其实现:
class CRF_NER(object):
def __init__(self):
"""初始化参数"""
pass
def initialize_model(self):
"""初始化"""
pass
def train(self):
"""训练"""
pass
def predict(self, sentence):
"""预测"""
pass
def load_model(self):
"""加载模型 """
pass
def save_model(self):
"""保存模型"""
pass
在 CRF_NER 类中,分别完成了语料预处理和模型训练、保存、预测功能,具体实现如下。
第一步,init 函数实现了模型参数定义和 CorpusProcess 的实例化和语料预处理:
def __init__(self):
"""初始化参数"""
self.algorithm = "lbfgs"
self.c1 ="0.1"
self.c2 = "0.1"
self.max_iteratiOns= 100
第二步,给出模型定义,了解 sklearn_crfsuite.CRF 详情可查该文档。
def initialize_model(self):
"""初始化"""
algorithm = self.algorithm
c1 = float(self.c1)
c2 = float(self.c2)
max_iteratiOns= int(self.max_iterations)
self.model = sklearn_crfsuite.CRF(algorithm=algorithm, c1=c1, c2=c2,
max_iteratiOns=max_iterations, all_possible_transitiOns=True)
第三步,模型训练和保存,分为训练集和测试集:
def train(self):
"""训练"""
self.initialize_model()
x, y = self.corpus.generator()
x_train, y_train = x[500:], y[500:]
x_test, y_test = x[:500], y[:500]
self.model.fit(x_train, y_train)
labels = list(self.model.classes_)
labels.remove(‘O‘)
y_predict = self.model.predict(x_test)
metrics.flat_f1_score(y_test, y_predict, average=‘weighted‘, labels=labels)
sorted_labels = sorted(labels, key=lambda name: (name[1:], name[0]))
print(metrics.flat_classification_report(y_test, y_predict, labels=sorted_labels, digits=3))
self.save_model()
第四至第六步中 predict、load_model、save_model 方法的实现,大家可以在文末给出的地址中查看源码,这里就不堆代码了。
最后,我们来看看模型训练和预测的过程和结果:
ner = CRF_NER()
model = ner.train()
经过模型训练,得到的准确率和召回率如下:
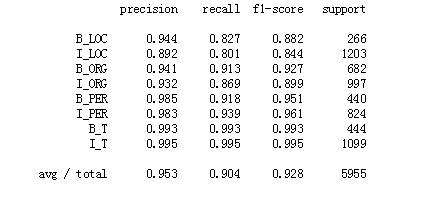
进行模型预测,其结果还不错,如下:

基于 CRF 的中文命名实体识别模型实现先讲到这儿,项目源码和涉及到的语料,大家可以到:Github 上查看。
总结
本文浅析了条件随机场,并使用 sklearn_crfsuite.CRF 模型,对人民日报1998年标注数据进行了模型训练和预测,以帮助大家加强对条件随机场的理解。
参考资料及推荐阅读
- 条件随机场(CRF)
- 条件随机场CRF(一)从随机场到线性链条件随机场
- 命名实体:基于 CRF 的中文命名实体识别模型
- 条件随机场(CRF)理论及应用








 京公网安备 11010802041100号
京公网安备 11010802041100号